
Akira's ML news summary #September 2020

※有料設定してますが、投げ銭用なので全部無料でみれます。
2020年9月に投稿された論文や記事で特に面白かったものを紹介します。
内容 1. 論文, 2.技術的な記事等, 3. 機械学習の活用/社会実装, 4. その他話題
---------------------------------------------------------------------
論文
人物をビデオから消す
Flow-edge Guided Video Completion
https://arxiv.org/abs/2009.01835
Flowを用いたビデオの欠損補完の研究。ポイントは①欠損部エッジ検出して繋げる(補完する)ことでFlowの補完③少し時間的に遠いフレームを使ったFlow計算で見えない部分を取得③勾配を用いた再構成で継ぎ目を防ぐ。先行研究より定量的に優れており、ビデオから人を消すこともできる。

数学の定理の証明をNLPで実施する
Generative Language Modeling for Automated Theorem Proving
https://arxiv.org/abs/2009.03393
自然言語処理界隈でよく使われるTransformerモデルを用いて、数学定理の証明を自動で行うGPT-fを提案。定理の証明を[GOAL,(定理),PROOFSTEP,...]のように言語モデルとして定義して学習させる。事前学習を行うことで精度が向上し、23個の定理で既存の証明より短くすることに成功。数学界隈でも評判よかったとのこと。

AlphaZeroでゲームバランスを整える
Assessing Game Balance with AlphaZero:Exploring Alternative Rule Sets in Chess
https://arxiv.org/abs/2009.04374
トップ囲碁棋士に勝利したAlphaGoの後継モデルで、将棋なども扱えるAlphaZeroを用いてゲームバランス評価をする試み。キャスリング不可など微量のルール変化を与えたチェスもどきをAlphaZeroで学習させることで、熟練プレーヤーがそれぞれのチェスの亜種に対してどのような見方をしているのかを見ることができる。チェスの歴史でもルールの改変を繰り返して今のルールに落ち着いており、他のゲームでもそのようなことがAlphaZeroを使うことで擬似的にできるようになることができるとのこと。

ビデオの中の人の時間軸を操作する
Layered Neural Rendering for Retiming People in Video
https://arxiv.org/abs/2009.07833
動画中の人物の動きのタイミング(動作の開始、速度)を変更できるモデル。まず、影になっている人も含めてそれぞれの人の動きと背景を分離する。そして、背景とそれぞれの人の情報を組み合わせて特徴量化し、それらを組み合わせることで合成する。人の動きに付随する水しぶきなどのタイミングも変更できている。

Wavelet変換を用いてBigGANを小さくする。
not-so-BigGAN: Generating High-Fidelity Images on a Small Compute Budget
https://arxiv.org/abs/2009.04433
Wavelet変換(WT)を用いて低周波情報のみから画像を再現することで、少ない計算資源で高精細画像をGANで生成する研究。具体的には失われた高周波情報をNNで再現し、逆Wavelet変換(iWT)をかける。BigGANに適用し、生成画像の質は少し下がるがTPUx256からGPUx4にまで計算資源を落とすことに成功。

活性するかを適用的に判断する活性化関数
Activate or Not: Learning Customized Activation
https://arxiv.org/abs/2009.04759
ReLUとSwishを統一的に扱い、その一般的な形としての活性化関数ACtivationOrNot(ACON)を提案。活性化関数の中に複数の学習可パラメータが入ることで、活性するか否かを自由に変えられる。物体検知、画像検索で精度が向上することを確認した。

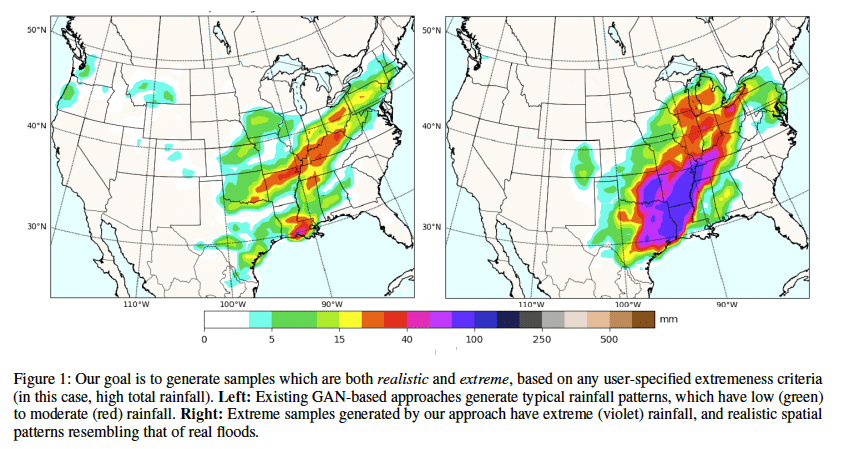
稀少な気象データを自由に生成できるGAN
ExGAN: Adversarial Generation of Extreme Samples
https://arxiv.org/abs/2009.08454
通常GANは典型的なデータのみを学習して生成するが、ExGANは低確率で出現するデータをコントロールしながら生成することができる。GANで生成したサンプルの中で極端なものだけをデータセットに加えてデータを偏らせた上で、それを使って極端度を条件付きにしたGANでデータを生成する。気象データにおいて、上手く生成できることを確認した。
ユニット各々の役割を特定することで生成画像をコントロールする
Understanding the Role of Individual Units in a Deep Neural Network
https://arxiv.org/abs/2009.05041
DNNの各々のユニットの役割を解釈する研究。明示的に”木”などの概念を与えなくても、それらを学習しているユニットが存在していることを発見。GANにおいて、各々の概念を司るユニットを操作することで画像から木を減らしたり、建物にドアをつけることに成功した。

Transformerモデルのサーベイ
Efficient Transformers: A Survey
https://arxiv.org/abs/2009.06732
自然言語処理を中心に近年広がってきたTransformerモデルの改善系のサーベイ論文。メモリ改善やattentionの使い方などの項目ごとにまとめられている。図表とDiscussionだけ見ても、なんとなく流れがつかめる。

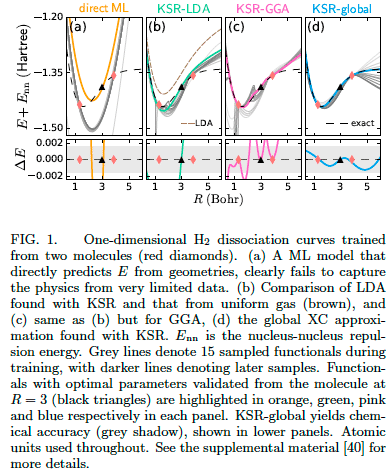
密度汎関数理論と機械学習
https://arxiv.org/abs/2009.08551
密度汎関数理論を用いた物理シミュレーションをニューラルネットワークで近似する問題において、Kohn-Sham方程式を微分可能なモデルとして扱うことにより、物理的な制約をMLモデルに課すことができる。それにより交換相互作用項計算の精度を大きく向上させることができた。
---------------------------------------------------------------------
2. 技術的な記事
Kaggleの創始者であるAnthony Goldbloom氏へのインタビュー記事
KaggleのコンペがRandom Forestの有用性を証明したこと、学会でGBDTそこまで流行してないが構造化データでは上手く機能していること、現在の研究が特定のデータセットに過学習しているのではないか、Kaggle NotebookとKaggle Datasetの導入で多くの人が自由に洞察を述べられる環境になったこと、などを議論している。
良い初期値だけでネットワークを疎に保ったまま学習
GoogleのICML2020の研究で、個人的にすごく注目していた論文の解説記事。初めからスパースなネットワークで枝刈&接続しながら、スパース性を保ちつつ良い初期値のみで学習させる"Rigging the Lottery"という手法を提案。手法名は、「NNには精度に貢献する良い初期値をもつニューロンが少数のみ存在する」宝くじ仮説(Lottery Ticket Hypothesis)より、良い初期値のみをとってこれるイカサマ(Rigging)ができることより由来している(と思う)。ネットワークがスパースなまま学習できるので、メモリに乗り切らない超巨大なネットワークを学習できることができると主張している。
私が以前書いた解説記事↓
ACL2020 SlideLive
ACL2020のSlideLive(著者が論文をスライドにおとして数分で解説してくれるビデオ)が公開されている。下記URLで、論文の左側にあるビデオカメラのアイコンをクリックすると再生できる。
ICML2020 SlideLive
ICMLL2020のSlideLive(著者が論文をスライドにおとして数分で解説してくれるビデオ)が公開されている。わりと見やすいWebページになっており、最新のものや人気のものでソートが可能。
強化学習の網羅的な資料
えるエル(@ImAI_Eruel)さんによる深層強化学習サマースクールにおける講義資料。強化学習の基礎からAgent57のような新しめの話題まで網羅されている。7ページ目から度々登場する強化学習の流れをまとめた図は必見。
V100 / T4 / M60 GPUの速度比較
V100 / T4 / M60 GPUの速度を、カタログスペックではなく実際にMLを扱う人たちが使うとどのようになるかを検証した記事。様々なネットワークで速度を比較している。
結果、データサイズが小さい時は、T4,M60でもV100に匹敵する結果を出すことができ、コスパが良い。(V100と比較して、T4は1/5, M60は1/4程度のコスト)。しかし、バッチサイズを大きくするときは、V100を使う方が良さそう。
自然言語処理の未来と課題
HuggingFaceのThomas Wolf氏による、NLPの未来と題した発表。巨大すぎるモデル/巨大すぎるデータセットの問題や、データセットを巨大化すれば精度は上がるのか、モデルは常識を理解しているのか、ドメイン外への汎化など様々な話題がある。
自己教師あり学習BYOLはバッチ正規化で暗黙的に対比学習を行っている
近年のSOTAとなった自己教師あり学習手法であるMoCo系やSimCLR系は、異なるデータ拡張をかけた同じデータ同士を正のサンプル、それ以外を負のサンプルとして、対比学習を行っていた。しかし、BYOLは対比損失を含んでいない。この記事では、バッチ正規化があることによって、ミニバッチのデータ集中を防いでばらけるため、暗黙的に対比学習を行っていることを説明している。
------------------------------------------------------------------
3. 機械学習の活用/社会実装
GNNを使ってGoogle Mapの到着時刻予測を改善する
Graph Neural Networksを用いて、Google Mapの到着時刻を最大で50%程度の改善に成功した。グラフで局所的な交通網をグラフデータとして扱い、サンプリングすることで単一のモデルを大規模に展開できる。
科学者とAIアシスタントで宇宙の監視をする
太陽風が地球の磁気圏とぶつかることで発生するマグネトポーズという現象は稀にしか発生しないため、高度な技術をもつ科学者をフルタイムで動員することで監視していた。その作業を機械学習でアシスタントを作る試行錯誤の記事。難しいタスクなので、学習のループ内に科学者を介在させる”Scientist in the Loop”で精度を改善した。
AIツールへの保険適用
脳卒中の兆候を察知して患者が時間的に重要な治療を受けられるようにするAIツール「Viz LVO」の使用に対する病院への払い戻しに合意した。Viz LVOは、90パーセントの精度で脳のCTスキャンから脳卒中患者を特定し、自動的に専門家に通知する。1回の使用毎に最大で1040ドルの払い戻しができる。病院側が大きな経済的な負担なしにこのようなAIツールを使えるようになる。
マスク検出/検温/追跡を同時に実施
Barcom は、顔認識機能と体温スキャン機能を備えたスタンドアロンターミナルを発売し、企業が人手による温度チェックなしで再開ガイドラインに対応できるようにした。マスクの検出、±0.2℃の精度で同時に40人が測定できる温度のスキャン、追跡が可能となっている。
------------------------------------------------------------------
4. その他話題
DeepSpeedで1兆パラメータモデルの学習が可能に
Micorsoftの深層学習ライブラリDeepspeedで最大1兆パラメーターのモデルの学習が可能になった。これはGPT-3(2020年9月17日現在で最大のパラメータ数をもつモデル)の5倍以上のパラメータ数である。NvidiaのV100 GPUが1つしか使えないとしても、130億パラメータのモデルが学習できるもよう。貧弱な計算環境しかない企業や研究室でも色々できるようになるかもしれない。
GPT-3の商用化
GPT-3が10月から商用化利用になるが、それへの考察の記事。学習には純粋な計算コスト(つまり給与は入っていない)だけで2760万ドルかかったであろうこと、まともに推論させるとV100が11個いること、covid-19関係の新語には対応出来ないこと、などが書いてある。
NeurIPS2020では誰でも聴講できる
NeurIPS2020の参加申込が始まりましたが、今年は誰でも聴講できるもよう。聴講費用は学生25ドル、一般100ドル。会議の質と規模を考えると決して高くはない金額なので、是非参加しましょう。
---------------------------------------------------------
TwitterでMLの論文や記事の紹介しております。
https://twitter.com/AkiraTOSEI
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。