【機械学習実装】ロボットの加速度から製品の良否判定

論文紹介
『 加速度信号を用いた溶接ロボットの異常検知モデルの開発 』https://www.jstage.jst.go.jp/article/jsaeronbun/52/3/52_20214249/_pdf
自動車の車体はプレスで成形した鋼板を溶接でくっつけているわけですが、溶接に不備があると、衝突安全性が確保できません。なので、溶接不良を判断する検査技術の検討が進められています。
そのなかで、機械学習を使って不良を診断するシステムを研究した例があったので、今回紹介するとともにpythonで実装してみたいと思います。
データ
自動車の車体はスポット溶接という溶接方法が使用されています。
スポット溶接とは、鋼板を銅製の電極で挟み、1万アンペアの電流を流して発熱・溶融させる手法です。
よく自動車工場の動画で、ロボットが火花を散らしながら溶接を行っている場面があるかと思います。このときに行っているのがスポット溶接です。
これの電極先端と鋼板を拡大したものが下の動画になります。
板の間から溶け始め、溶けた金属が飛散する様子がわかると思います。
ちなみに、実際の現場では溶けた範囲が小さく、溶接後すぐはがれてしまうことがあります。
このような場合を溶接不良とみなして対策を行います。
今回紹介する検査手法は、電極に加速度センサを取付け

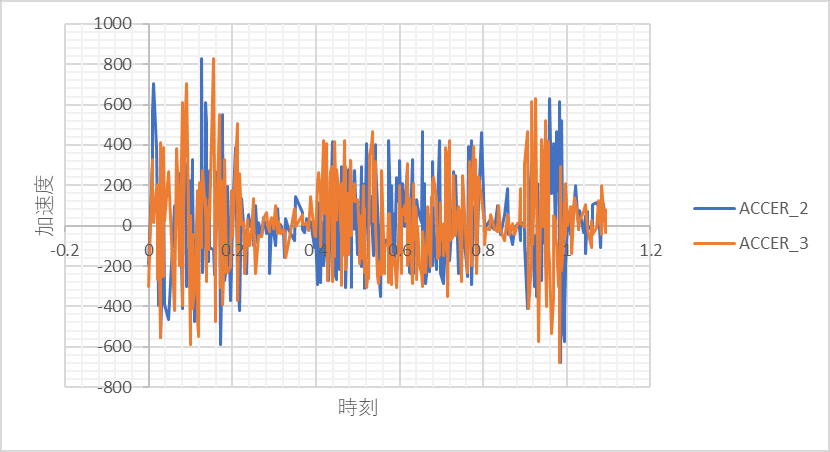
以下のようにダミーデータを500個くらい作りました。
これをLightGBMでクラス分類するコードを作成しました。
######################## やること
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import lightgbm as lgb
from sklearn.model_selection import *
################# データ読み込み ########################
data = pd.read_csv(r"csvファイルのパス")
################# データの前処理 ########################
# TIMEをcolumnsに変換するための辞書を作る
data_dict = data['TIME'].T
data_col_dict = data_dict.to_dict()
# timeをindexにする
data = data.rename(index=data_col_dict)
print(data.head())
# dataを転置する
data = data.T
data = data.drop(['TIME'], axis=0)
# indexを連番にする
data = data.reset_index()
data = data.drop(['index'], axis=1)
##### 判定をつける
for i in range(len(data.index)):
data.loc[i, '判定'] = round(np.random.rand())
print(data['判定'].unique())
print(data.info())
print(data.head())
y = data['判定']
X = data.drop(y.name, axis=1)
################# 機械学習モデルの作成 ########################
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, shuffle=False)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train,
test_size=0.2, shuffle=False)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_validation, y_validation, reference=lgb_train)
# LightGBM parameters
lgb_clf = lgb.LGBMClassifier(max_depth=5)
lgb_clf.fit(X_train, y_train)
# y_pred = lgb_clf.predict(X_test, num_iteration=gbm.best_iteration)
y_pred = lgb_clf.predict(X_test)
################# accuracyの出力 ########################
# accuracy
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_pred, y_test)
print(acc)プログラムの説明
データの前処理
ダミーデータのcsvファイルを見ると、時刻(TIME)に対して、加速度(ACCER_*)の値が入力されています。

ただ縦に並んでいると、機械学習できません。
機械学習で分類をする場合、縦には条件を記入するのが一般的です。今回なら加速度ですが、ほかにも産業用ロボットであれば軸の番号や回転角度なども入力できると思います。
つまり、データの形としては、以下のように各時刻に対して加速度のデータがある状態にします。

なので、プログラムを書いて変換しています。
上のプログラムで以下の部分がそれにあたります。
# TIMEをcolumnsに変換するための辞書を作る
data_dict = data['TIME'].T
data_col_dict = data_dict.to_dict()
# print(data_dict.head())
# timeをindexにする
data = data.rename(index=data_col_dict)
print(data.head())
# dataを転置する
data = data.T
data = data.drop(['TIME'], axis=0)
# indexを連番にする
data = data.reset_index()
data = data.drop(['index'], axis=1)判定の入力
実際の現場で機械学習による予測を行う場合、製品の検査結果を予測することが多いかと思います。今回のダミーデータに検査結果は入力していませんので、判定結果もダミーデータを作成します。
今回は判定という列にランダムで1か0を入力しました。プログラムはこの部分です。
##### 判定をつける
for i in range(len(data.index)):
data.loc[i, '判定'] = round(np.random.rand())分類結果
ちなみにですが、分類の精度(accuracy)はおよそ50%程度です。ダミーデータをランダムで作成したためです。

この記事が気に入ったらサポートをしてみませんか?