
第2号「画像編集と動画生成」

Edit One for All: Interactive Batch Image Editing

どんなもの
課題:今までの画像編集は一つの画像に対しての手法でした。例えばDragGANも一つの画像に対してです。このような手法を多くの画像に適用するにはどうすれば効率的かということについての課題をこの論文では議論しています。
先行研究と比べてどこがすごい?
新規性: 従来の研究が単一画像の編集に焦点を当てていたのに対し、この研究ではユーザーが指定した編集を一連のテスト画像に自動的に適用する新しい問題を提起しています。
技術の手法やキモはどこ?
手法: StyleGAN2の学習された潜在空間に基づいて、ユーザーの編集をモデリングし、この編集を他の画像に適用する方法を提案しています。編集された属性(例えば、目の閉じ具合)が潜在空間での方向に沿って線形に変化することを利用して、全ての画像が同じ最終状態になるように編集の度合いを制御しています。
どうやって有効だと検証した?
実験: 人間の顔、猫、犬など様々なドメインでStyleGANモデルを用いた編集を行い、インタラクティブな点描画やテキストベースの画像編集ベースラインと比較しました。さらに、提案された方法で編集された画像が元のテスト画像と大きく歪まないことを確認するために、FID(Fréchet Inception Distance)スコアも計算されました。
議論はある?
結論: 提案されたバッチ画像編集フレームワークは、従来の単一画像編集メソッドと同等の品質を持ちながら、著しく時間と人的労力を節約できることが示されました。現在のところ、この方法はStyleGANモデルに限定されていますが、将来的には拡張してより多様な編集タイプに対応できる可能性があります。
Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation

どんなもの
内容: 「Motion-Zero」と名付けられたこのフレームワークは、ビデオ内の動くオブジェクトの軌跡をゼロショットで制御することを可能にします。これにより、事前訓練済みのビデオ生成拡散モデルにおいて、バウンディングボックスによって制御されるテキスト・ビデオ拡散モデルを実現します。
先行研究と比べてどこがすごい?
新規性: Motion-Zeroは追加の訓練なしで様々な事前訓練済みビデオ拡散モデルに適用可能であり、これまでの大規模なビデオトレーニングデータが必要な既存の軌跡制御方法とは異なります。これにより計算コストを大幅に削減し、プラグアンドプレイが可能になります。
技術の手法やキモはどこ?
手法: 初期ノイズを基にしたプライオリティモジュールを用いて、動くオブジェクトの位置に基づくプライオリティを提供します。これにより、オブジェクトの外観の安定性と位置の精度を向上させます。さらに、空間的制約と新しい時間的注意メカニズムを導入し、位置精度と時間的連続性を確保します。

どうやって有効だと検証した?
実験: 様々なビデオ拡散モデルに対するMotion-Zeroの有効性を評価しました。ベースラインとなるビデオ拡散方法と比較し、定性的、定量的にその効果を確認しました。その結果、Motion-Zeroはオブジェクトの動きの方向と軌跡を効果的に制御し、既存の方法と比べて優れたパフォーマンスを示しました。
議論はある?
考察と限界: Motion-Zeroの性能はベースモデルに依存しており、ビデオ拡散モデルが時に不安定なオブジェクトを生成することがあります。また、現在の方法では、ユーザーが完全に動きの軌跡を制御しており、ビデオとの意味的な相互作用が欠けています。今後の研究では、オブジェクトの動きと背景の相互作用や、物語的な意味的制御を探求する方向です。
OMG-Seg: Is One Model Good Enough For All Segmentation?
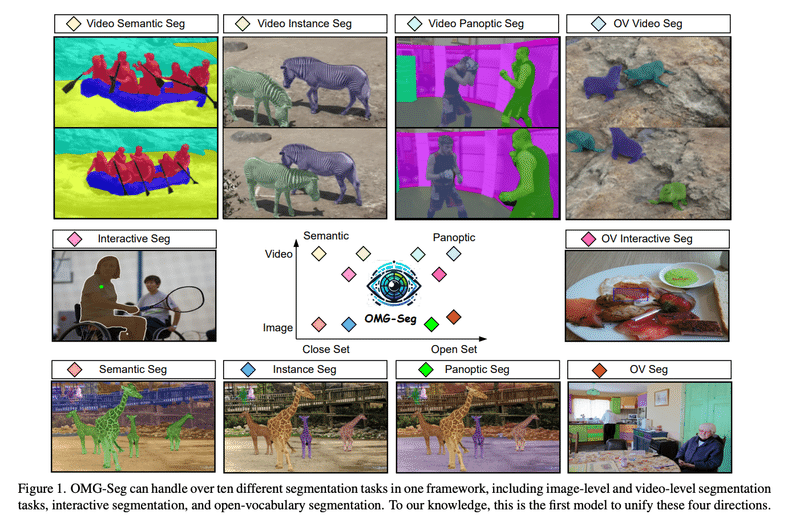
どんなもの
概要: OMG-Segは、画像セマンティック、インスタンス、パノプティックセグメンテーションやビデオカウンターパート、オープンボキャブラリ設定、プロンプト駆動インタラクティブセグメンテーション、ビデオオブジェクトセグメンテーションなど、多様なセグメンテーションタスクを効率的かつ効果的に処理できるモデルです。これは、これらのタスクを一つのモデルで処理し、満足のいくパフォーマンスを達成する最初のモデルです。
先行研究と比べてどこがすごい?
新規性: 既存のディープセグメンテーションモデルは通常、特定のタスクに特化していますが、OMG-Segは幅広いスペクトルのセグメンテーションタスクを一つの統一されたアーキテクチャで処理できます。これにより、タスク固有の設計が不要になり、大量のデータを活用してモデルの適応性と効果性を高めることができます。
技術の手法やキモはどこ?
手法: OMG-Segは、変換器ベースのエンコーダ・デコーダアーキテクチャを採用し、タスク固有のクエリと出力をサポートします。様々なマスクタイプとそれに対応するビデオフォーマットを表現するために、オブジェクトクエリを活用します。さらに、CLIP埋め込みをマスク分類に採用し、オープンボキャブラリ推論を可能にしています。
どうやって有効だと検証した?
実験: OMG-Segの有効性を検証するために、複数のデータセット(COCO、VIPSeg、Youtube-VISなど)で共同トレーニングを行い、異なるセグメンテーションタスクでのパフォーマンスを評価しました。その結果、OMG-SegはMask2FormerやTubeLinkなどの特定の画像・ビデオセグメンテーションモデルと同等のパフォーマンスを示し、オープンボキャブラリメソッドに対しても競争力があることが示されました。
議論はある?
多データセット設定: OMG-Segは、複数のデータセット設定での共同トレーニングを通じて、ほとんどのビデオセグメンテーションデータセットでパフォーマンスを向上させ、モデルパラメータを大幅に削減することができました。しかし、ADE-20kデータセットでは共同トレーニングの下でパフォーマンスが著しく低下しました。これは、スケールの変動やクラス内の不均一な分布が原因であると推測されています。
RAP-SAM: Towards Real-Time All-Purpose Segment Anything

どんなもの
概要: RAP-SAMは、インタラクティブセグメンテーション、パノプティックセグメンテーション、ビデオセグメンテーションという異なる3つのタスクをリアルタイムで処理できるモデルです。これは、実際のアプリケーションに適した多様な出力を提供することを目的としています。RAP-SAMは効率的なエンコーダと効率的な分離型デコーダを含んでおり、プロンプト駆動のデコードを行います。
先行研究と比べてどこがすごい?
新規性: 既存のセグメンテーションモデルは、特定のタスクに特化しており、リアルタイムでの動作やモバイルデバイスとの互換性に課題がありました。RAP-SAMは、これらの制約を克服し、リアルタイムでの汎用セグメンテーションタスクを実現することに成功しています。
技術の手法やキモはどこ?
手法: RAP-SAMは、画像レベルのオブジェクト、ビデオレベルで追跡されるオブジェクト、プロンプトベースの特定のオブジェクトを表すクエリベースのマスクトランスフォーマーを組み合わせて使用します。また、位置エンコーディングを利用してプロンプトクエリを生成し、特徴マップFと共にマルチステージデコーダに送ります。

どうやって有効だと検証した?
実験: RAP-SAMは、さまざまなバックボーンにおいて、パノプティックセグメンテーション、ビデオインスタンスセグメンテーション、インタラクティブセグメンテーションの3つのビジュアルセグメンテーションタスクにおいて、最高の速度と精度のトレードオフを達成しました。これは、Mask2Formerなどの既存の状態最先端のメソッドと比較しても同等以上の結果を示しました。
議論はある?
共同トレーニング: このモデルは、異なるタスクを共同で一度にトレーニングすることを目的としており、オブジェクトクエリをビデオ/画像のエンティティに割り当てるためにハンガリアンマッチングを適用します。また、データセット間の分類体系の衝突を避けるために、クラス分類器をCLIPテキスト埋め込みに置き換えています。
[1] Edit One for All: Interactive Batch Image Editing
DORAEMONGPT : TOWARD UNDERSTANDING DYNAMIC SCENES WITH LARGE LANGUAGE MODELS

どんなもの
内容: DoraemonGPTは、動的なビデオタスクを効率的に処理するために設計されたLLM駆動のエージェントです。ビデオと関連するタスクに基づいて、関連する情報をシンボリックメモリに変換し、空間的・時間的な問い合わせや推論を可能にします。また、専門分野の知識を必要とするタスクに対応するために、外部知識源を活用するプラグアンドプレイツールを組み込んでいます。
先行研究と比べてどこがすごい?
新規性: 従来のLLM駆動のビジュアルエージェントは主に静止画タスクに焦点を当てていましたが、DoraemonGPTは動的なビデオタスクに対応しています。このシステムは、複雑な動画タスクをサブタスクに分解し、モンテカルロ木探索を基にした計画を行うことが特徴です。
技術の手法やキモはどこ?
手法: システムは「メモリ・ツール・プランナー」の形で構成されており、空間優位メモリと時間優位メモリの二つのタイプのメモリを使用しています。これらのメモリは、関連するタスクの属性を抽出し、SQL言語でクエリ可能なコンパクトな表に統合します。また、サブタスクツールと知識ツールを使って、計画プロセスを支援しています。
どうやって有効だと検証した?
実験: NExT-QAというビデオ質問応答のベンチマークを用いてDoraemonGPTを評価しました。その結果、DoraemonGPTは最先端の監督付きVQAモデルや他のLLM駆動システムと比較して競争力のあるパフォーマンスを示しました。特に因果関係に関する質問では、以前の最先端モデルを上回る結果を示しました。
議論はある?
考察: DoraemonGPTは、動的なビデオタスクのための新しいアプローチを提供し、より複雑な質問に対応できる能力を示しています。さらに、シンボリックメモリを用いた推論と、モンテカルロ木探索に基づく計画により、複数の解決策を効果的に探索し、情報豊富な最終回答を提供します。これにより、実世界の動的なシナリオでの複雑なタスクの解決における新たな可能性が広がります。
[2]Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation
[3] OMG-Seg: Is One Model Good Enough For All Segmentation?
[4] RAP-SAM: Towards Real-Time All-Purpose Segment Anything
[5] DORAEMONGPT : TOWARD UNDERSTANDING DYNAMIC SCENES WITH LARGE LANGUAGE MODELS
この記事が気に入ったらサポートをしてみませんか?