
【論文瞬読】RISEの登場:言語モデルに自己改善能力を授ける革新的アプローチ

こんにちは、みなさん。株式会社AI Nestです。
今日は、大規模言語モデルの自己改善能力に関する興味深い研究論文を紹介したいと思います。その論文とは、「Recursive Introspection: Teaching Language Model Agents How to Self-Improve」という題名の研究で、略称は「RISE」です。
タイトル:Recursive Introspection: Teaching Language Model Agents How to Self-Improve
URL:https://arxiv.org/pdf/2407.18219
所属:Carnegie Mellon University, UC Berkeley, MultiOn
著者:Yuxiao Qu, Tianjun Zhang, Naman Garg, Aviral Kumar
従来の言語モデルの問題点
近年、GPT-3.5などの強力な言語モデルが登場し、自然言語処理の分野に大きな進歩をもたらしました。これらのモデルは、大量のテキストデータを学習することで、人間のような自然な文章を生成できるようになりました。しかし、一方で、これらのモデルには、複数回の試行で自身の応答を改善することが難しいという問題があります。
例えば、ある複雑な問題に対して、言語モデルが不完全な回答を生成したとします。人間であれば、フィードバックを受けて自分の回答を見直し、修正を加えることで、より良い回答を導き出すことができます。しかし、現在の言語モデルは、このような自己改善のプロセスが苦手なのです。つまり、一回の応答で満足せず、フィードバックを受けて改善を重ねるという、人間のような学習プロセスが欠けているのです。
RISEの革新的なアプローチ
RISEは、この問題に取り組むために、マルチターンのMarkov Decision Process (MDP) を構築し、オンポリシーのロールアウトデータと、専門家や自己生成の監督を利用して自己改善を促します。MDPとは、エージェントが環境と相互作用しながら、報酬を最大化するような行動を学習するための数理モデルです。RISEは、この枠組みを言語モデルの自己改善に応用しています。

具体的には、RISEは以下のようなプロセスを反復的に実行します。
データセットからマルチターンのMDPを構築: 与えられた問題文と正解の応答のペアから、複数ターンの対話形式のデータを作成します。
現在のモデルからオンポリシーのロールアウトデータを収集: 現在の言語モデルを使って、構築したMDP上で複数ターンの応答を生成します。この際、モデルは自身の過去の応答を参照しながら、新たな応答を生成します。
専門家モデルからの応答や自己生成の応答で改善された履歴を作成: 生成されたロールアウトデータに対して、より優れた応答を提供するために、専門家モデル(より性能の高い言語モデル)からの応答や、モデル自身が生成した複数の応答の中から最良のものを選択します。
報酬で重み付けされた回帰により、改善された履歴でモデルをファインチューニング: 改善された応答履歴に対して、報酬(正解との一致度合い)で重み付けした回帰損失を用いて、モデルのパラメータを更新します。これにより、モデルは自身の応答を改善するための方策を学習します。

この革新的なアプローチにより、RISEは言語モデルに自己改善能力を効果的に付与することができるのです。モデルは、自分自身の過去の応答を分析し、フィードバックを取り入れながら、徐々に応答の質を高めていくことができます。
実験結果と今後の展望
研究チームは、RISEの有効性を検証するために、GSM8KとMATHの2つのデータセットで広範な実験を行いました。GSM8Kは、算数の文章題を集めたデータセットで、MATHは、より高度な数学の問題を含むデータセットです。

実験の結果、RISEは両方のデータセットにおいて、他の手法よりも優れたパフォーマンスを達成しました。特に、複数ターンにわたる自己改善のプロセスを経ることで、単一ターンの応答生成と比べて、大幅な性能向上が見られました。また、RISEは、異なる言語モデルやアウトオブドメインのプロンプト(学習データとは異なる問題)に対しても、一貫した結果を示しました。
ただし、RISEにはまだ課題も残されています。例えば、現在のRISEは、オフラインで収集されたデータを用いて学習を行っていますが、将来的には、完全にオンラインの強化学習へと拡張することが望まれます。これにより、モデルは実環境でのフィードバックを直接取り入れながら、自己改善を行うことができるようになるでしょう。


また、RISEを他のタスクや分野に適用することで、言語モデルの能力をさらに引き出せる可能性があります。例えば、質問応答や対話システム、要約生成など、様々なアプリケーションでRISEを活用できるかもしれません。

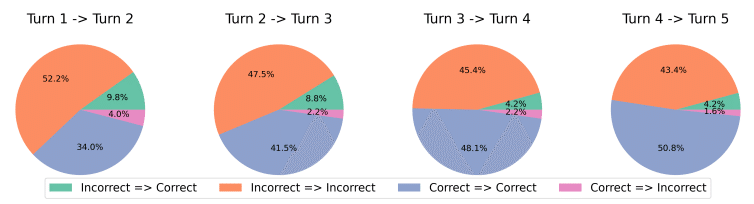
さらに、GPT-3.5のような強力なモデルが自己改善に苦戦する理由についても、さらなる考察が必要です。モデルの構造的な限界なのか、学習データの不足なのか、あるいは他の要因が関与しているのか、詳細な分析が求められます。
さいごに
いかがでしたか?RISEは、言語モデルに人間のような自己改善能力を付与するための、非常に興味深いアプローチです。この研究は、自然言語処理の分野に新たな視点をもたらし、言語モデルのさらなる進歩の可能性を示唆しています。
今後、RISEの枠組みがさらに洗練され、より多様なタスクに適用されることで、言語モデルの性能が飛躍的に向上することが期待されます。また、RISEの考え方を応用することで、言語モデルだけでなく、他の機械学習モデルの自己改善能力を高めることもできるかもしれません。
言語モデルの進化は、私たち人間の生活をより豊かで便利なものにしてくれるでしょう。同時に、言語モデルが人間のように自己を改善できるようになることで、人工知能と人間の関係性にも変化が生じるかもしれません。言語モデルの可能性と限界を見極めながら、倫理的な配慮を忘れずに、この技術を発展させていくことが重要です。
RISEに代表されるような革新的な研究は、私たちに言語モデルの未来を考えるきっかけを与えてくれます。今後も、この分野の動向から目が離せませんね。それでは、また次の記事でお会いしましょう!