
【論文瞬読】大規模言語モデルの知識編集に革命を起こす「DeCK」の実力とは?

こんにちは、みなさん!株式会社AI Nestです。
今日は、大規模言語モデル(LLMs)の知識編集に関する最新の研究について紹介したいと思います。
タイトル:Decoding by Contrasting Knowledge: Enhancing LLMs' Confidence on Edited Facts
URL:https://arxiv.org/abs/2405.11613
所属:CAS Key Laboratory of AI Safety, ICT, CAS, University of Chinese Academy of Sciences, University of California, Los Angeles 4 Carnegie Mellon University
著者:Baolong Bi, Shenghua Liu, Lingrui Mei, Yiwei Wang, Pengliang Ji, Xueqi Cheng
最近、GPT-3やLLaMAなどのLLMsが自然言語処理の分野で大きな注目を集めています。これらのモデルは、膨大なテキストデータを学習することで、驚くほど高度な言語理解と生成能力を獲得しています。
しかし、LLMsが持つ膨大な知識をいかに編集・更新するかは、大きな課題となっています。世界は常に変化しており、新しい情報が日々生まれています。LLMsがこれらの変化に適応し、常に最新の知識を提供するためには、効果的な知識編集の手法が必要不可欠です。
そんな中、ある研究グループが、LLMsの知識編集における新たな手法 "Decoding by Contrasting Knowledge (DeCK)" を提案し、大きな話題となっています。
既存手法の問題点と DeCK の登場
LLMsの知識編集では、In-Context Editing (ICE) と呼ばれる手法がよく使われています。ICEは、LLMsに編集された知識を含むプロンプトを与えることで知識の編集を行います。例えば、「東京オリンピックは2020年に開催された」という知識を「東京オリンピックは2021年に開催された」に編集したい場合、ICEではこの編集内容をプロンプトとしてLLMsに与えます。
しかし、ICEには大きな問題点があります。それは、訓練時に過度に確信を持ってしまった知識 (stubborn knowledge) の編集が難しいということです。LLMsは、訓練データから特定の知識を強く学習してしまうことがあります。このような知識は、ICEによる編集に抵抗します。

左:単純な知識に対するICEの例
中央:stubborn knowledgeに対するICEの失敗例
右:stubborn knowledgeに対するDeCKの成功例


ここで登場するのが、DeCKです。DeCKは、編集された知識の注目度を高め、パラメトリックな知識との対比によって編集後の知識の確信度を向上させます。具体的には、DeCKは以下の2つの要素から構成されます:
編集シグナル強化 (Editing Signal Enhancement):編集された知識の注目度を高めることで、対比デコーディングの際に、この知識が除外されないようにします。
知識対比デコーディング (Decoding by Contrasting Knowledge):ICEによる編集後の分布と、編集前のパラメトリックな分布を対比することで、次のトークンを予測します。
これらの要素により、DeCKは編集された知識の確信度を効果的に高めることができるのです。
DeCKの内部動作
DeCKがどのようにしてLLMsの知識編集を改善するのか、もう少し詳しく見ていきましょう。

まず、編集シグナル強化では、編集された知識に関連するトークンの確率を上げるようにモデルの出力分布を調整します。これは、編集された知識を表すトークンとその意味的関連性の高いトークンに高い重みを与えることで実現されます。
次に、知識対比デコーディングでは、編集後の分布と編集前の分布を比較します。具体的には、編集後の分布から編集前の分布を引くことで、編集による知識の変化を強調します。この結果得られた分布を使って、次のトークンを予測するのです。
これらの操作により、DeCKは編集された知識の影響を強め、LLMsがその知識を使って出力することを促進します。
実験結果と今後の展望
研究グループは、DeCKとICEを比較する実験を行いました。実験には、MQUAKE-3Kというデータセットが使用されました。このデータセットは、複数ステップの推論を必要とする質問と、それに対応する知識の編集から構成されています。
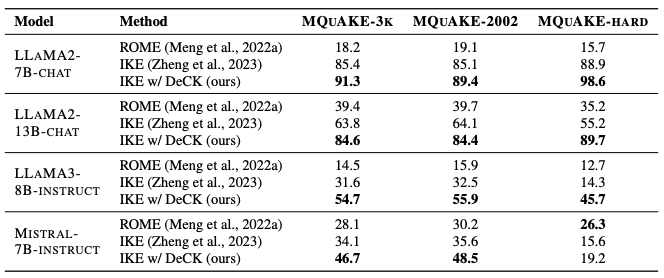

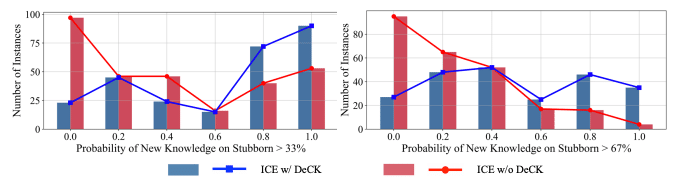
実験の結果、DeCKがICEの性能を大幅に向上させることが明らかになりました。特に、stubborn knowledgeの編集において、DeCKは著しい効果を示しました。例えば、LLAMA3-8B-INSTRUCTモデルでは、DeCKがICEの性能を219%も向上させたのです。


この結果は、LLMsの知識編集における大きなブレイクスルーと言えるでしょう。DeCKは、ICEの性能を向上させるだけでなく、LLMsの知識編集における新たな方向性を示唆しています。
ただし、DeCKにも課題はあります。例えば、デコード時の遅延の問題や、より低コストなDeCKの探索などです。また、DeCKを他の知識編集手法と組み合わせることで、さらなる性能向上が期待できます。
これらの課題が解決されれば、DeCKは LLMs の知識編集における強力なツールになると期待されます。
まとめ
LLMsの知識編集は、急速に発展している分野であり、DeCKはその重要な一歩を示しています。
DeCKは、編集シグナル強化と知識対比デコーディングという2つの要素により、編集された知識の確信度を効果的に高めます。実験結果から、DeCKがICEの性能を大幅に向上させ、特にstubborn knowledgeの編集において著しい効果を示すことが明らかになりました。
今後は、DeCKの更なる改良や、他の知識編集手法との組み合わせなどが期待されます。また、LLMsの知識編集が、実世界のアプリケーションにどのように応用されていくのかにも注目が集まります。
LLMsは、自然言語処理の分野に大きな革新をもたらしています。そして、DeCKに代表される知識編集技術の進歩は、LLMsの可能性をさらに広げるでしょう。
この分野の進展から目が離せませんね!