
【論文瞬読】AI最前線:大規模言語モデルの評価に革命!? 新手法「Sharpeスコア」とは

こんにちは!株式会社AI Nestです。今回は、大規模言語モデル(LLM)の評価方法に革命を起こすかもしれない新しい研究について、深掘りしていきたいと思います。では、早速見ていきましょう!
タイトル:Toward the Evaluation of Large Language Models Considering Score Variance across Instruction Templates
URL:https://arxiv.org/abs/2408.12263
所属:Nara Institute of Science and Technology
著者:Yusuke Sakai, Adam Nohejl, Jiangnan Hang, Hidetaka Kamigaito, Taro Watanabe
1. 背景:LLM評価の課題
みなさん、ChatGPTやGPT-4など、最近話題の大規模言語モデル(LLM)をご存じですよね。これらのAIモデルは日々進化を続けていますが、その能力を正確に評価するのは意外と難しいんです。
なぜかって?それは、LLMの性能が「どんな指示(プロンプト)を与えるか」によって大きく変わってしまうからなんです。つまり、評価に使うプロンプトを変えると、結果もガラッと変わってしまう...これじゃあ、公平な評価なんてできないですよね。
2. 新たなアプローチ:複数テンプレートとSharpeスコア
そんな中、最近発表された論文が、この問題に切り込む新しいアプローチを提案しているんです。
2.1 複数の指示テンプレート
まず、この研究では「複数の指示テンプレート」を使った評価を提案しています。つまり、1つのプロンプトだけじゃなく、いろんなパターンの指示を使ってLLMを評価するんです。これなら、特定のプロンプトに最適化されたモデルを見抜くことができますね。

Figure 1は、自然言語推論タスク(MNLI)のデータセット作成プロセスを示しています。複数の指示テンプレートを使用することで、モデルの真の能力をより正確に評価できるんです。
2.2 Sharpeスコア
さらに面白いのが、「Sharpeスコア」という新しい評価指標です。これ、実は金融業界で使われる「シャープレシオ」というものをヒントに考え出されたんです。
Sharpeスコアの公式はこんな感じ:
Sharpeスコア = μscore / (α * σscore + 1)ここで、
μscore:評価スコアの平均
σscore:評価スコアの標準偏差
α:分散の影響を調整するパラメータ
つまり、平均スコアが高くて、ばらつきが小さいモデルほど高いスコアになるわけです。これって、まさに「安定して高性能」なモデルを評価できる指標ですよね!
3. 研究の詳細:日本語と英語でクロス言語評価
この研究では、日本語と英語の両方でデータセットを作成し、様々なLLMを評価しています。対象としたタスクは以下の5つ:
言語的受容性(文法的に正しいかどうか)
意味的類似性(2つの文がどれくらい似ているか)
自然言語推論(ある文から別の文が導けるか)
読解力(文章を読んで質問に答える)
常識推論(一般常識を必要とする質問に答える)
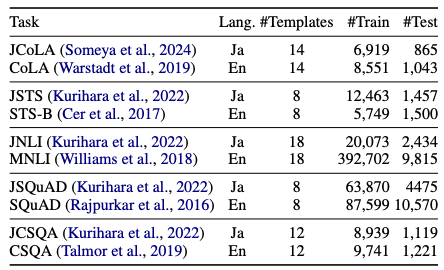
Table 1は、各タスクのテンプレート数とデータセットのサイズを示しています。かなり大規模な評価が行われていることがわかりますね。
これらのタスクを、ゼロショット(事前学習だけ)とファインチューニング(追加学習あり)の両方の設定で評価しているんです。

Table 2は、この研究で評価されたLLMのリストです。日本語専用モデルから多言語モデルまで、幅広いモデルが評価対象となっていることがわかります。
4. 興味深い発見たち
この研究から、いくつか面白い発見がありました。
指示チューニングの落とし穴:指示に従うようにチューニングしたモデルが、逆に性能が下がることも!
大きいモデル≠高性能:パラメータ数を増やしても、必ずしも性能向上につながらない。
クロス言語転移:英語で学習したモデルが、日本語タスクでも高性能を発揮することも。
デコード方法の影響:ゼロショットでは制約付きデコード、ファインチューニングではグリーディデコードが有効。

Figure 3は、日本語データセットにおけるファインチューニング設定での各モデルのランキング変化を示しています。Sharpeスコアのパラメータαを変えると、モデルの順位が変動することがわかります。これは、単一の評価指標では捉えきれない、モデルの安定性や一貫性を反映しているんですね。
5. この研究が示唆すること
この研究は、LLMの評価方法に一石を投じています。複数のプロンプトを使った評価とSharpeスコアの導入は、より公平で信頼性の高いLLM評価につながる可能性があります。
また、クロス言語評価の結果は、多言語LLMの開発に新たな視点をもたらすかもしれません。

Table 4は、日本語データセットにおけるファインチューニング設定での結果を示しています。モデルによって得意不得意のタスクがあることがわかりますね。これらの詳細な結果は、今後のLLM開発の方向性を示唆しているかもしれません。
6. 今後の展望
この研究はまだ始まりに過ぎません。今後は、
より多くの言語やタスクへの適用
さらに多様なLLMの評価
Sharpeスコアの他分野への応用
などが期待されます。
7. まとめ:LLM評価の新時代の幕開け?
今回紹介した研究は、LLMの評価方法に新しい風を吹き込む可能性を秘めています。単一のプロンプトによる評価から、複数プロンプトとSharpeスコアを用いた評価へ。これは、より信頼性の高いAI評価への第一歩と言えるでしょう。
AIの進化とともに、その評価方法も進化していく。そんな時代の幕開けを、私たちは目撃しているのかもしれません。
さて、みなさんはこの新しい評価方法をどう思いますか? コメント欄で皆さんの意見をお聞かせください。それでは、次回のAI最前線でお会いしましょう!