
【論文瞬読】LOFT: 大規模言語モデルの新時代を切り拓くベンチマーク

みなさん、こんにちは。株式会社AI Nestです。近年、自然言語処理の分野では大規模言語モデル (LCLMs) が大きな注目を集めています。LCLMs は、膨大な量のテキストデータを用いて訓練された言語モデルで、質問応答、要約、翻訳など、様々なタスクで優れた性能を示しています。しかし、LCLMs の真の能力を評価するためには、長文コンテキストでの性能を測定する必要があります。今回は、そのための新しいベンチマーク「LOFT」について詳しく見ていきましょう。
タイトル:Can Long-Context Language Models Subsume Retrieval, RAG, SQL, and More?
URL:https://arxiv.org/abs/2406.13121
所属:Google DeepMind
著者:Jinhyuk Lee, Anthony Chen, Zhuyun Dai, Dheeru Dua, Devendra Singh Sachan, Michael Boratko, Yi Luan, Sébastien M. R. Arnold, Vincent Perot, Siddharth Dalmia, Hexiang Hu, Xudong Lin, Panupong Pasupat, Aida Amini, Jeremy R. Cole, Sebastian Riedel, Iftekhar Naim, Ming-Wei Chang, Kelvin Guu
LOFT とは?
LOFT (Long-Context Frontiers) は、LCLMs の長文コンテキストにおける性能を評価するためのベンチマークです。LOFTは、テキスト、画像、音声を含む6つのタスク、35のデータセットで構成されており、最大100万トークンまでのコンテキスト長に対応しています。これは、これまでのベンチマークと比べて非常に長いコンテキストです。

LOFT の目的は、LCLMs が検索、Retrieval-Augmented Generation (RAG)、SQL、many-shot in-context learning などのタスクで従来のパイプラインを置き換えられるかを評価することです。
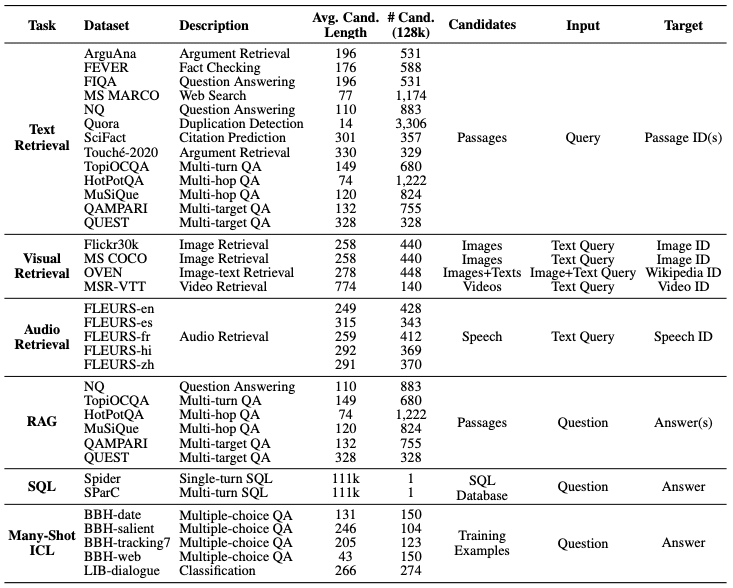
検索タスク: LCLMs が、関連する情報を大規模なコーパスから直接検索できるかを評価します。これにより、検索システムを別途構築する必要がなくなります。
RAG タスク: LCLMs が、検索結果を利用して質問に回答できるかを評価します。これにより、複雑なパイプラインを簡略化できます。
SQLタスク: LCLMs が、構造化データに対する自然言語クエリを処理できるかを評価します。これにより、SQLへの変換が不要になります。
Many-shot in-context learning タスク: LCLMs が、少数のサンプルから新しいタスクを学習できるかを評価します。これにより、タスクごとに最適なサンプルを探す必要がなくなります。
既存のベンチマークの問題点
これまでの LCLMs の評価は、主に二つの問題点がありました。
合成的なタスクへの依存: 多くのベンチマークが、人工的に生成されたデータを使用しています。これらのタスクは、実世界のアプリケーションで必要とされる長文コンテキストでの性能を十分に反映していません。
パラダイムシフトを起こすタスクの欠如: 既存のベンチマークは、LCLMs がもたらす可能性のあるパラダイムシフトを十分に評価していません。例えば、LCLMs が検索システムやデータベースを置き換えられるかどうかは、ほとんど検証されていません。
LOFT は、これらの問題点に対処するために設計されました。実世界のタスクを用いて、長文コンテキストでの性能を評価します。また、パラダイムシフトを起こす可能性のあるタスクを含めることで、LCLMs の真の能力を測定します。
LOFT の評価結果
LOFT では、Gemini 1.5 Pro、GPT-4o、Claude 3 Opus といった最先端の LCLMs を評価しました。その結果、以下のような興味深い知見が得られました。


LCLMs と専用モデルの性能比較
検索タスクでの優れた性能: LCLMs は、検索タスクにおいて専用モデルに匹敵する性能を示しました。これは、LCLMs が特定のタスクに特化した訓練を行わずとも、大規模なコーパスから関連情報を検索できることを示唆しています。
複雑な推論タスクでの課題: 一方で、複数のステップを必要とする複雑な推論タスクでは、LCLMs はまだ専用モデルに及ばないことが明らかになりました。この結果は、LCLMs の推論能力の向上が今後の課題であることを示しています。
プロンプティング戦略の重要性: LOFT の評価では、プロンプティング戦略が性能に大きく影響することが示されました。つまり、LCLMs を効果的に使うためには、適切な指示やサンプルを与える必要があるのです。この結果は、ロバストで指示可能な LCLMs の開発が重要であることを示唆しています。


今後の展望
LOFT は、LCLMs の評価に新たな視点をもたらすベンチマークであり、長文コンテキストにおける言語モデルの進歩を測る上で重要な役割を果たすでしょう。特に、LCLMs が従来のパイプラインを置き換える可能性を探る点で興味深い取り組みです。
今後は、以下のような展開が期待されます。
LOFT の拡張: より多様なタスクや、さらに長いコンテキスト長への対応が求められます。また、効率性の評価など、新たな評価軸の導入も検討されるでしょう。
LCLMs の性能向上: LOFT で明らかになった課題を解決するために、プロンプティング戦略やアーキテクチャの改善、訓練データの拡充などの研究が進むと予想されます。
実世界アプリケーションへの応用: LCLMs の能力が向上するにつれ、検索システムやデータベースなどの従来のパイプラインを置き換える実世界アプリケーションが登場するかもしれません。
LOFT は、こうした研究開発を加速させる重要なベンチマークになると考えられます。
まとめ
LOFT は、LCLMs の長文コンテキストにおける性能を評価するための野心的なベンチマークです。検索、RAG、SQL、many-shot learning など、幅広いタスクを網羅しており、LCLMs が従来のパイプラインを置き換える可能性を探る上で重要な役割を果たします。
LOFT の評価結果から、LCLMs は特定のタスクに特化した訓練を行わずとも優れた性能を発揮できることが示唆されました。一方で、複雑な推論タスクやプロンプティング戦略の影響など、まだ課題も残されています。
今後、LOFT はさらなる拡張が期待されており、LCLMs の研究開発を加速させる重要なベンチマークになるでしょう。言語モデルの進化に伴い、LOFT がどのように発展していくのか、非常に楽しみです。LCLMs が自然言語処理の様々な課題を解決し、我々の生活をより豊かにしてくれる日が来ることを期待しましょう!