
【論文瞬読】訓練不要のグラフニューラルネットワーク:TFGNNsが切り開く新たな可能性

こんにちは!株式会社AI Nestです。今回は、最近話題の論文「Training-free Graph Neural Networks and the Power of Labels as Features」について深掘りしていきます。この論文が提案するTFGNNs(Training-free Graph Neural Networks)は、GNNの世界に革命を起こす可能性を秘めています。さあ、一緒に最先端の研究を覗いてみましょう!
タイトル:Training-free Graph Neural Networks and the Power of Labels as Features
URL:https://arxiv.org/abs/2404.19288
所属:National Institute of Informatics
著者:Ryoma Sato
1. TFGNNsとは?驚きの特徴
TFGNNsは、その名の通り「訓練不要」のグラフニューラルネットワークです。従来のGNNが訓練に多大な時間とリソースを必要としたのに対し、TFGNNsは初期化直後から使用可能です。しかも、必要に応じて訓練を行うことで性能をさらに向上させることができるんです。
主な特徴をまとめると:
訓練なしで即時使用可能
オプショナルな訓練による性能向上
Labels as Features (LaF)の活用
ラベル伝播アルゴリズムの近似
特に注目したいのは、LaFの活用です。これまでGNNの研究ではあまり注目されてこなかったのですが、この論文ではLaFがGNNの表現力を大幅に向上させることを理論的に証明しています。
2. なぜTFGNNsが必要なの?
ここで疑問に思うかもしれません。「既存のGNNでダメなの?」という声が聞こえてきそうですね。確かに、GCNやGATなどの従来のGNNも素晴らしい性能を示してきました。しかし、いくつかの課題がありました:
計算コストが高い:大規模グラフの処理には膨大な計算リソースが必要
即時展開が困難:訓練に時間がかかるため、すぐに使用できない
トランスダクティブ設定の未活用:利用可能なラベル情報を十分に活用していない
TFGNNsは、これらの課題に一石を投じる画期的なアプローチなんです。
3. TFGNNsの仕組み:理論と実践
TFGNNsの魔法の秘密は、Labels as Features (LaF)とラベル伝播アルゴリズムの巧妙な組み合わせにあります。
3.1 Labels as Features (LaF)
LaFは、ノードのラベル情報を特徴量として使用する手法です。これにより、GNNは周辺ノードのクラス分布などの情報を直接利用できるようになります。著者らは、LaFがGNNの表現力を理論的に向上させることを証明しました。
具体的には、LaFを使用したGNNがラベル伝播アルゴリズムを表現できることを示しています。これは、従来のGNNには不可能だったことなんです!
3.2 ラベル伝播アルゴリズムの近似
TFGNNsの初期化は、ラベル伝播アルゴリズムを近似するように設計されています。つまり、訓練を行わなくても、ある程度の性能を発揮できるわけです。これが「訓練不要」を実現する鍵となっています。
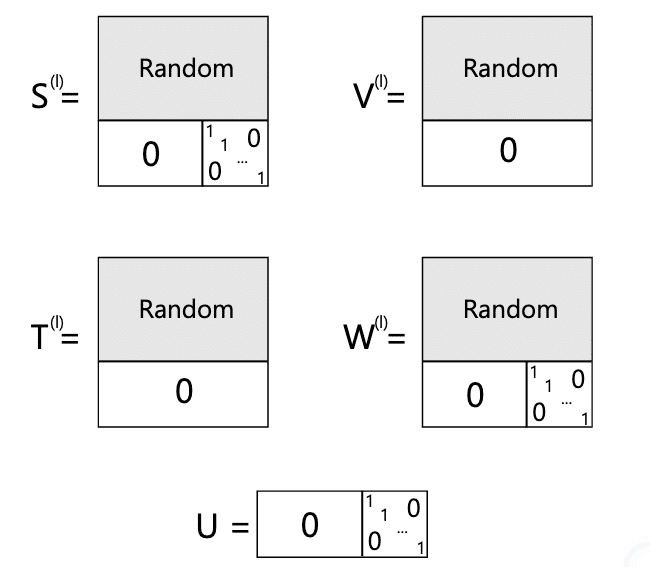
上の図は、TFGNNsの初期化方法を示しています。最後の(1 + |Y|)行または|Y|行のパラメータが特殊なパターンで0または1に初期化されているのがわかります。この巧妙な初期化が、訓練なしでもラベル伝播アルゴリズムを近似できる秘密なんです。
4. 実験結果:TFGNNsの威力
論文では、様々な実験によってTFGNNsの有効性を検証しています。主な結果をご紹介しましょう:
4.1 訓練不要設定での性能比較

この表は、訓練不要の設定でのノード分類精度を比較しています。驚くべきことに、TFGNNsは全てのデータセットでGCNsやGATsを大きく上回っています。例えば、Coraデータセットでは、TFGNNsが60%の精度を達成している一方、GCNsは16.3%、GATsは17.7%にとどまっています。これは、TFGNNsが本当に「訓練不要」で高い性能を発揮できることを示しています。
4.2 深層TFGNNsの挙動

この図は、TFGNNsの層の深さと精度の関係を示しています。通常のGNNでは層を深くすると性能が低下する「over-smoothing」問題が知られていますが、TFGNNsではむしろ層を深くするほど性能が向上しているんです。これは、従来のGNNの常識を覆す発見と言えるでしょう。
4.3 収束速度の比較

この図は、TFGNNsとGCNsの訓練イテレーション数と精度の関係を示しています。TFGNNsは初期状態から高い精度を示し、わずかな訓練で更に性能が向上しています。一方、GCNsは多くの訓練イテレーションを必要としています。これは、TFGNNsが実用的な状況で素早く展開できることを示唆しています。
4.4 ノイズに対する頑健性

この図は、特徴量にノイズを加えた場合のTFGNNsとGCNsの性能を比較しています。ノイズレベルが高くなるにつれて、GCNsの性能は急激に低下していますが、TFGNNsはより頑健な振る舞いを示しています。これは、TFGNNsが実世界の不完全なデータに対しても強い耐性を持つことを示唆しています。
5. TFGNNsの可能性と限界
TFGNNsは確かに革新的ですが、万能ではありません。著者らも正直にその限界を認めています:
インダクティブ設定への適用が困難
異種グラフでの性能低下の可能性
しかし、これらの制限はむしろ今後の研究の方向性を示唆しているとも言えます。TFGNNsのアイデアを拡張し、これらの課題を克服する研究が今後出てくるかもしれません。
6. 筆者の考察:TFGNNsが切り開く未来
個人的に、この研究は非常にエキサイティングだと感じています。TFGNNsは、GNNの設計において「何を入力とするか」という根本的な問いを投げかけています。これまでGNNの研究は主にアーキテクチャの改良に焦点を当ててきましたが、TFGNNsは入力情報の選択の重要性を浮き彫りにしたんです。
また、訓練不要でありながら、オプショナルな訓練で性能向上が可能という柔軟性は、実世界のアプリケーションにおいて大きな価値があると考えています。例えば、リソースの制限が厳しい環境でも即座にGNNを展開でき、余裕ができたら徐々に性能を向上させていくといった使い方が可能になります。
7. まとめ:GNNの新時代の幕開け?
TFGNNsは、GNNの研究に新しい風を吹き込む可能性を秘めています。訓練不要、LaFの活用、理論と実践のバランスなど、多くの魅力的な特徴を持っています。
もちろん、まだ改善の余地はあります。より多様なデータセットでの検証や、大規模グラフでの性能評価など、今後の研究で明らかにされるべき点は多々あります。しかし、TFGNNsが示した新しい方向性は、間違いなくGNN研究の未来に大きな影響を与えるでしょう。
皆さんは、TFGNNsについてどう思いますか?従来のGNNを置き換える日が来るのか、それとも新たな用途を切り開くのか。GNNの世界はまだまだ発展の途上にあり、私たちはエキサイティングな時代に生きているんですね。これからのGNN研究の発展が本当に楽しみです!