
Stable Diffusion はここがすごい! - SDXL を1クリックで導入する方法

はじめに
こんばんは、kimamanaDr です。
前回は 生成AIのオープンソースの問題と、Stable Diffusion が弱い点について紹介しました。
今回は、そんな Stable Diffusion の魅力をお伝えします!
オープンソースの強み
Stable Diffusion の魅力は、オープンソースであることです。
オープンソースの強みは、何といってもユーザーが誰でも開発に参加できることです。

Stable Diffusion は生成AIの改造のメッカで、多くのユーザーが自作のコードを公開しています。
改造は何でもある
Stable Diffusion の改造は何でもあります。
Stable Difusion を始める時に特に便利なのが、1クリックでインストールから起動まで行えるツールです。
以前は Stable Diffusion をインストールするにもそれなりに知識が必要でしたが、今は全部自動で行えます。
Stable Diffusion を1クリックで始める方法は、記事の最後で紹介します
個性的なモデル
前回紹介したように、Stable Diffusion の公式モデルは公開後はアップデートされませんが、代わりにユーザーがカスタムして公開しているものがたくさんあります。
Stable Diffusion ではアニメ系・実写系を問わず、完成度の高いモデルを選ぶことができます。



モデルを選ぶときの一番の基準は見た目ですが、モデルは進化するにつれてプロンプトの再現性や破綻の少なさも改善しているので、なるべく新しいものを選ぶのがおすすめです。
今回使用したモデルはこちらです。
アニメ系モデル
実写系モデル
構図を制御できる
Stable Diffusion はそのほかにもオリジナルの機能があります。その中で特に画期的な機能が ControlNet です。
ControlNet は拡散モデルが 画像を生成する過程に介入して構図を決める 方法で 2023年11月に その仕組みが論文として発表 されました。
論文の内容はこちらの とーふのかけら さんの記事で解説されていますが、私には難しくて理解できませんでした。
仕組みは分からなくても使えるので、私の使い方を紹介します!
実際の制御
実際の使用例を2つ紹介します。
まずは構図の元になる画像を生成します。
次に ControlNet を利用して、元画像の構図を維持しながらタッチを描き直してみます。


絵柄は全く変わっていますが、人物のポーズや、背景の構図が維持されているのが分かります。
次は実際の写真を取り込んでその「雰囲気」をイラストに再現してみます。


紅葉の色や写真の構図が、イラストにきれいに活かされているのが分かります。
画像生成AIに触れたことのある人には、このイラストをプロンプトだけで表現するのはかなり難しい ことがお分かりになると思います。
ControlNetを使えばかなりのレベルで制御することができます。
AI が構図を修正
なお、先の紅葉の写真では画面の下半分ぐらいまで地面が写っていますが、AI は3分の1ぐらいがバランスが良いと考え、修正したようです。

これは絵画や写真では3分割法と呼ばれるテクニックで、画面を3等分した線やその交点にオブジェクトを配置すると全体が安定して見える構図です。
よく見ると前の女性工作員の絵も同じように3分割されています。

画像を生成して「出来が良い」と思うものは、だいたいこの構図になっていることが多いです。
世界の名画でも同じ手法が用いられているらしく、AI はそんなことも学習しているのですね!
参考:サク さんの記事
もう「運」まかせではない
今までの画像生成は、プロンプトを工夫して書いてあとは大量に画像を作成して 当たり を待つ方法でした。
ControlNet を使うと失敗がずっと少なくなり、さらに生成した絵の修正もできるので、クオリティをもっと上げることができるようになりました。
Stable Diffusion は尖っていく
一方で、ControlNet のような独自機能を使いこなすには様々なパラメータの調整が必要で、Stable Diffusion は新しく画像生成AIを始める人にとって少しハードルが高くなっています。
ほかの生成AIが、言葉から画像を生成するシンプルな機能を進化させているのに対して、Stable Diffusion はよりニッチな用途に特化しています。
次回は、生成AIを使う上で気を付けるべきルールについて紹介します。
1クリックで Stable Diffusion を始める
文中で触れた、1クリックで Stable Diffusion を始める方法です。
ここでは、私が利用している EasySdxlWebUi の導入方法を紹介します。
まず、こちらの Zuntan03 さんのページにアクセスします。
ページの説明に書いてある通りに Install-EasySdxlWebUi-forge.bat をクリックして、コードが表示されたら 右クリック → 名前をつけて保存 します。この時、拡張子は .bat で保存します。
ダウンロードした Install-EasySdxlWebUi-forge.bat を インストールしたいフォルダに配置して実行 します。「WindowsによってPCが保護されました」と表示されたら、詳細表示から実行します。
インストールを行うか確認画面が出るので、y と Enter を押します。
容量が 20GB 以上あるのでダウンロードに時間がかかりますが、あとは待つだけで起動します!
プロンプトを入力
起動すると、次のような画面が表示されます。
モデルは、最初から animagine-xl-3.0 というアニメモデルが選択されているのでこのままにします。
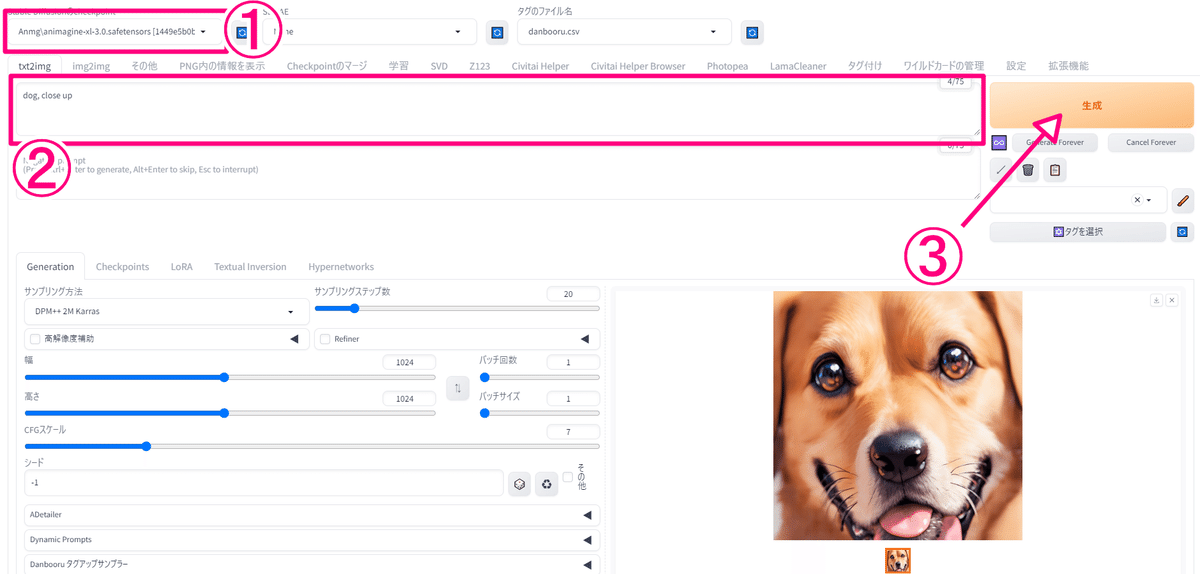
プロンプトに描きたいものを英語で入力して、生成をクリックすれば完了です!
Zuntan03 さん、素晴らしい機能を公開して頂きありがとうございます。
最後までお読み頂きありがとうございます!
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?