[第1部] 今更聞けない!ControlNetの仕組みと使い方を徹底解説!

2024.07.16 追記
ControlNetパラメータの、Hires-Fix OptionとImg2Img内のみの専用オプションについて記載を失念しておりましたので、追記しております。
はじめに
皆さん、ControlNetは使っていますか?
ControlNetとは、2023年4月頃より話題となり、lllyasviel氏より公開された画期的な技術として認知され、今やもう広く知れ渡っています。
しかし実際にどういう機能なのか、各ControlNetタイプの特徴とは何なのか、ControlNetモデルって何なのか等、しっかりと理解した上で使っていない方もいるのではないでしょうか。
今回はその第1部目ということで、基本的なところを説明していきますが、今後は徹底的に解説していきたいと思います。
ControlNetとは?
改めてご紹介するほどでもないですが、この技術はlllyasviel氏より発表・公開されたもので、今や必須技術と言っても過言ではない拡張機能となっています。
使用目的としては、構図の固定化、キャラクターのポーズ指定、描き込み量調整・高品質化など、様々なユーズに対応してます。
今までプロンプトで一生懸命制御してた部分を、ControlNetを使うことで楽に制御することを可能にした、画像生成AI界隈では激震が走った技術です。
ControlNetの概要
ControlNetとは、要約すると「拡散モデル(Diffusion Model)においてニューラルネットワーク内の各Blockに追加条件を与え、拡散モデルのプロセスを制御するニューラルネットワーク構造を持った技術」になります。
これは、画像生成AIにおける潜在空間を制御するには、非常に理に適っています。
どういうことかというと、本来U-Netは独立したニューラルネットワーク構造で、様々なレイヤーを介して生成物を生み出していることに起因しています。
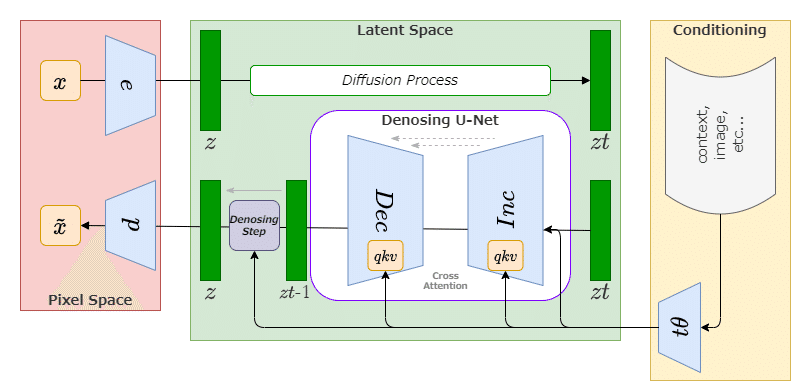


CNNベースの拡散モデルのニューラルネットワークであるU-Netは、各Blockを経て推論が進んでいきます。
ユーザが条件を与えられるのは、主にText-to-Imageで用いられるプロンプト、Image-to-Imageで用いられる画像データが主要リソースでした。(また付随する推論パラメータ類など)
つまりは、ユーザが指定するリソースとしては限界があったのです。
その為、従来はユーザがプロンプトや各種パラメータを用いて、U-Net内だけで完結できる仕組みの中で、構図や人物等の描写について試行錯誤する必要がありました。
そこの課題をクリアしたのがControlNetです。
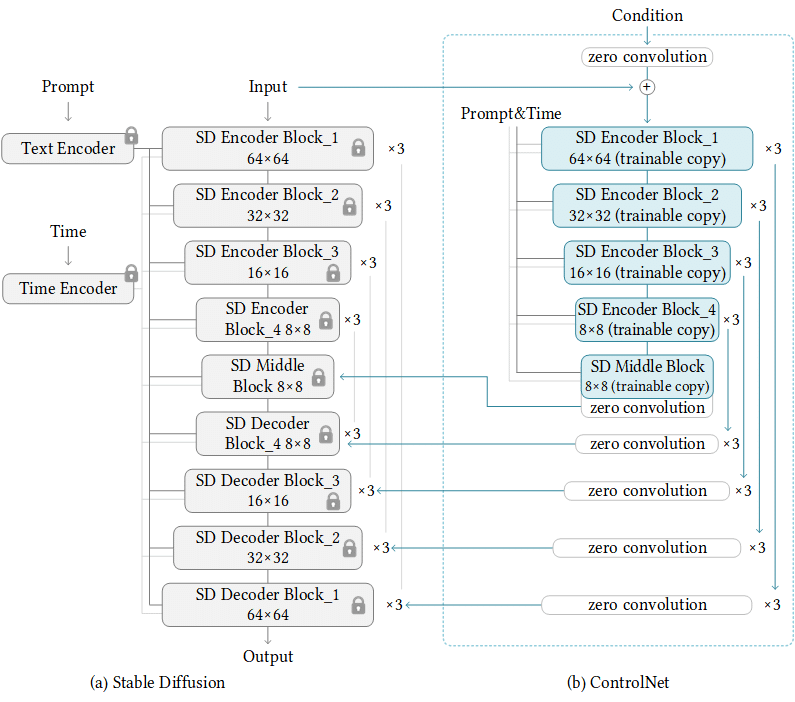
ControlNetは、U-Netのニューラルネットワークブロックを保持して、ControlNet上のニューラルネットワークでユーザから与えられた追加条件を付加し、U-Netへ返します。
そうすることで、構図の固定化等の生成物への制御が、大幅に改善することができます。
いまいちピンと来ていない方もいらっしゃると思いますので、もっと端的に説明すると、「もう一つのニューラルネットワーク(ControlNetモデル)で処理した結果を、本道であるStable DiffusionのU-Netへ追加条件を付加した状態で返してあげることで、決まった構図、キャラクターの姿形などへの寄与が格段と容易になった」ということです。
ControlNetの特徴
前項で図式したControlNetの概要を参照頂けると分かりますが、conv層(畳み込みの重みに係る層)の重みがゼロとなっています。
これはどういうことかというと、CNNによる畳み込みには、次元のベクトルを算定しなければ、特徴量の畳み込みができません。
conv層へ重みやバイアスをゼロで返すということは、ベクトルの勾配もゼロ(ゼロ畳み込み)となり、ニューラルネットワークは何も学習しないと、通常は思ってしまいます。
しかしlllyasviel氏は、「保持したニューラルネットワークブロックの影響を受けずに、与えられた特徴量がゼロ以外である限りは、最初の勾配降下反復にて非ゼロ行列に最適化され、最終的には、ゼロ畳み込みは徐々に非ゼロの重みを持つ共通の conv 層となる」とし、ControlNetの基盤を生み出しています。

ものすごく端的に言うと、「生成過程に左右されることなく、ControlNetの付加条件の重みだけを与えることができる(=全く意図しない出力を与えづらい)」と言ったところでしょうか。
ControlNetとImage-to-Imageとの違い
では、多くの人が感じているであろう、ControlNetとImage-to-Image(img2img)の違いは何かを解説していきます。
ControlNetとimg2img、どちらも画像データ(ControlNetの場合は、プリプロセッサで処理された画像も含む)をインプットリソースとして使用します。
じゃあ、実質img2imgでは?と思われる方も多いと思いますが、性質やプロセスが全く異なります。
img2imgは「画像の特徴量を算定し、画像全体の特徴量と類似した画像を推論する」機能になります。
対して、ControlNetは「画像内の線形や深度、輪郭、ランドマーク(骨格や関節等の構造)等の画像構成の特徴量を付加条件とした、新しい画像を推論する」技術になります。
フロントエンド上の見た目やユーザビリティとしては、img2imgに近い感覚を持ってしまいがちですが、本質は全く異なり、img2img以上にControlNetは用途の汎用性、応用性が高いと言えます。
ControlNetの基礎知識
使用するシーンとしては、主に以下が挙げられます。
キャラクターの構図を変更したくない
キャラクターのポーズは固定で背景のみを変えたい
キャラクターを意図したポーズにしたい
キャラクターの見た目のみを変更したい
生成物の一部分のみを意図したものに変更したい
描き込み量、高品質化したい
などなど…用途は非常に多岐に渡ります。
この中でも、キャラクターを意図したポーズにするといった点は非常に優れており、プロンプトで制御し、生成ガチャをするといった従来方法よりも格段とアウトプット品質は向上します。
導入
今回は第1部ということで、導入~基本的な使い方をお伝えしたいと思います。
この項は、まだControlNetを入れてない!という方向けになります。
入れている方は飛ばして頂いてOKです。
まずは本体の導入からしましょう。
SD WebUIの拡張機能として、Mikubill氏が開発してくれています。
こちらを使用していくことになります。
導入方法は2つあります。
Gitリポジトリよりクローンして導入する方法
SD WebUIの拡張機能リストより導入する方法
どちらでもOKです。
(1) Gitリポジトリよりクローンして導入する方法
まずは、Powershell等で、お使いのSD WebUIのextentionsフォルダまで階層を掘りましょう。
cd ./python/venv/stable-diffusion-webui/extentionsフォルダの指定はお使いの環境に応じて、適宜変更してください。
続いて、Git Cloneします。
git clone https://github.com/Mikubill/sd-webui-controlnet以上で本体の導入は完了です。
(2) SD WebUIの拡張機能リストより導入する方法
SD WebUI上の拡張機能 (Extentions)タブ - 拡張機能リスト (Available)を開いて読込みましょう。
登録されているリポジトリの一覧が表示されます。
その次に、「sd-webui-controlnet」と検索欄に入力してください。

インストールを押下することで、本体が導入されます。
続いて、ControlNetモデルの導入を行いましょう。
ControlNetモデルには、SD1.x/2.x用とSDXL用で分かれています。
ControlNetモデルには、pth拡張子とsafetensors拡張子が存在します。
また、yamlファイルもありますが、ない場合はダウンロードしてください。
SD1.x/2.x用ControlNetモデル
SDXL用ControlNetモデル
一つずつ手動でダウンロードすることも可能ですが、纏めてダウンロードすることも可能です。
纏めてダウンロードしたい方は、以下を試してください。
リポジトリ内のControlNetモデルを一括ダウンロードする
Powershell等でターミナルを開き、以下コマンドを入力してください。
初めに、huggingface_hubモジュールをpip導入します。
pip install huggingface_hubPythonコマンドを実行し、スクリプト記述を有効にします。
pythonhuggingface_hubモジュール内のsnapshot_download関数をインポートします。
from huggingface_hub import snapshot_download一括ダウンロードしたいリポジトリをsnapshot_download関数で指定し実行します。
snapshot_download関数の指定は以下のようにします。
snapshot_download(
# Hugging FaceリポジトリID
repo_id="",
# ブランチ名
revision="",
# 一括ダウンロード対象の拡張子(正規表現指定可)
allow_patterns="",
# 保存先
local_dir="")今回は一例で、SD1.x/2.x用ControlNetモデルを一括ダウンロードしてみますので、以下のように設定します。
repo_id = "lllyasviel/ControlNet-v1-1"
revision = "main"
allow_patterns = "*.pth"
local_dir = ".\python\venv\stable-diffusion-webui\extensions\sd-webui-controlnet\models"
実行関数に置き換えると
snapshot_download(
repo_id = "lllyasviel/ControlNet-v1-1",
revision = "main",
allow_patterns = "*.pth",
local_dir = ".\python\venv\stable-diffusion-webui\extensions\sd-webui-controlnet\models"
)となります。
local_dirに関しては、お使いの環境で適宜変更してください。
実行すると、以下のようにダウンロードが開始されます。
Fetching 14 files: 0%| | 0/14 [00:00<?, ?it/s]
control_v11p_sd15_inpaint.pth: 25%|██████████████████████████████▍ | 367M/1.45G [00:33<03:00, 5.97MB/s]
control_v11e_sd15_shuffle.pth: 22%|██████████████████████████▉ | 325M/1.45G [00:33<02:39, 7.02MB/s]
control_v11p_sd15_canny.pth: 28%|█████████████████████████████████▋ | 398M/1.45G [00:34<02:28, 7.04MB/s]
control_v11e_sd15_ip2p.pth: 25%|██████████████████████████████▎ | 357M/1.45G [00:33<03:07, 5.80MB/s]
control_v11p_sd15_mlsd.pth: 23%|████████████████████████████▌ | 336M/1.45G [00:34<02:31, 7.30MB/s]
control_v11p_sd15_normalbae.pth: 20%|███████████████████████▉ | 294M/1.45G [00:29<02:51, 6.73MB/s] あとはダウンロードが完了するまで、しばらくお待ちください。
共通機能の説明
では、ControlNetを開いてみましょう。
本体の導入が完了していれば、下記のような項目がGenerationタブ内に追加されているはずです。
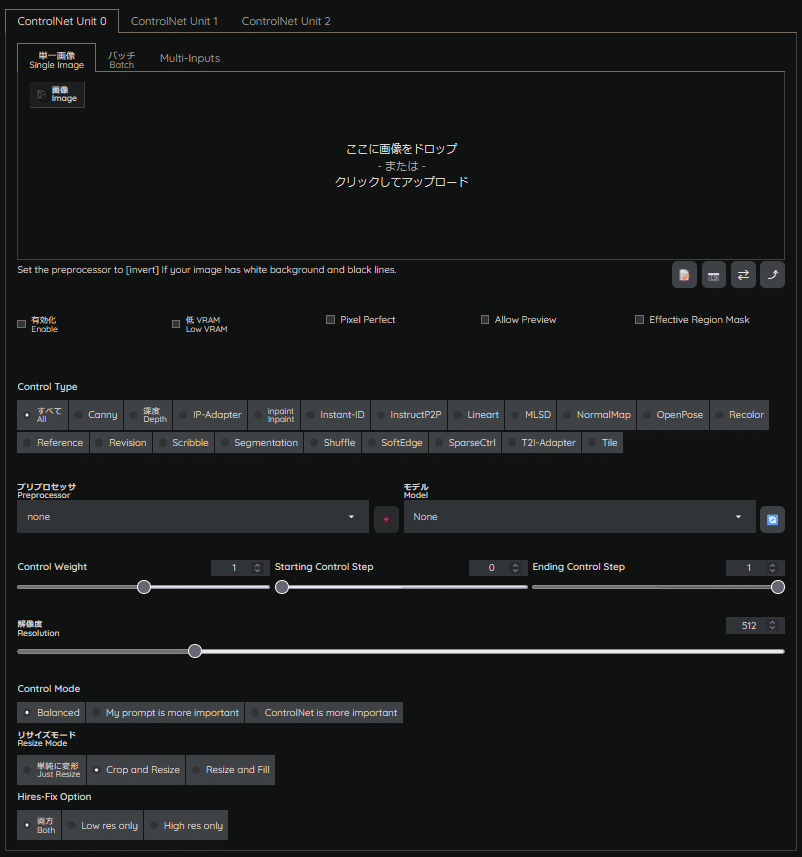
なんだか色んな機能やらプリプロセッサやモデル等の項目があるのが確認できます。
どのようなものなのか、一つずつ解説していきたいと思います。
画像リソース部
単一画像(Single Image)
1つの出力に対して、1つのControlNet処理を行う際に使用します。
1回の出力で、1枚のマスク画像が生成され、ControlNetモデルの推論結果は1枚分影響します。
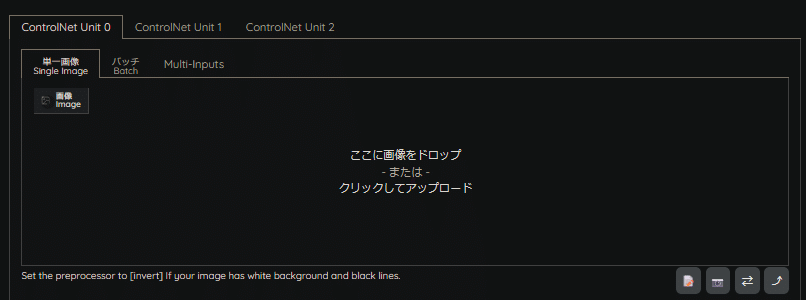
基本はこの機能を活用します。
1枚につき1枚のControlNet割り当てなので、イメージしやすいですね。
以下にて一例を挙げます。
例えば、1枚の画像と似た構図を作成したいと考えます。

これを、Cannyプリプロセッサに通します。

上記のようなマスク画像が生成されました。
このまま、生成を実行してみます。

上図のような構図・ポーズが固定化された画像が生成されました。
バッチ(Batch)
同一生成条件で、ControlNet処理を複数回行い、一括出力する際に使用します。
指定したフォルダ内の画像リソース全てに対して、ControlNetモデルが推論します。
1回の出力で、複数枚のマスク画像が生成され、ControlNetモデルの推論結果がフォルダ内の枚数分影響します。
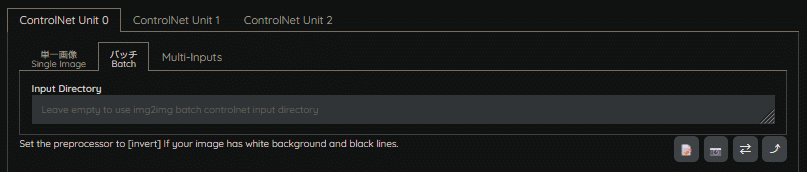
この機能の活用方法としては、一度に複数枚、ControlNetを適用した状態で出力できるようになるので、決まった構図などがある場合は、単一指定で1枚ずつ生成するのではなく、マスク画像に沿った画像を一括で出力するといった活用ができると思います。
以下にて一例を挙げます。
例えば、異なる2つのマスク画像が存在するフォルダを指定したとします。

バッチを有効にした状態で生成をすると、以下のようになります。


この処理が、1回の生成で行われます。
但し注意点として、その際の生成条件は同一プロンプト、同一パラメータでの処理、マスク画像は順番に処理されていくので、ランダム生成などには不向きです。
Multi-Inputs
単一の画像に対して、複数ControlNet処理を行う際に使用します。
指定した画像リソースに対して、ControlNetモデルが推論します。
1回の出力で、複数枚のマスク画像が生成され、ControlNetモデルの推論結果が、単一画像の生成に指定枚数分影響します。
バッチと異なる点は、単一毎に処理される(バッチモード)か、複数枚で処理される(Multi-Inputs)かになります。
いわば、
バッチモード = 生成画像1枚に対して、ControlNet処理が1枚。これを複数回行う。
Multi-Inputs = 生成画像1枚に対して、ControlNet処理がn枚。これを1回行う。
です。
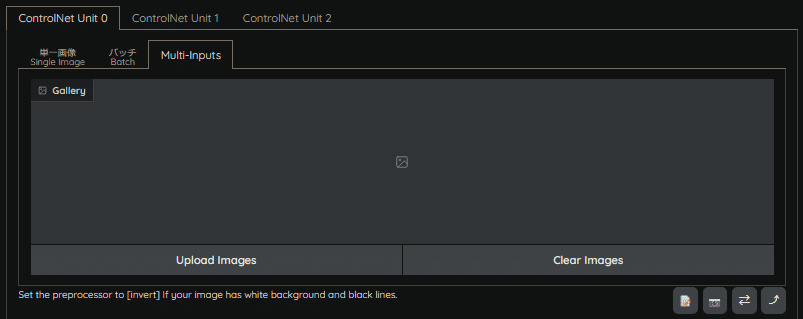
この機能の活用方法とは、複数人もしくは複数のオブジェクトを決まった配置がある場合に、マスク画像を複数枚指定することで、生成画像の好きな位置にキャラクターなどを配置することができるようになります。
以下にて一例を挙げます。
例えば、異なる2つのマスク画像があったとします。
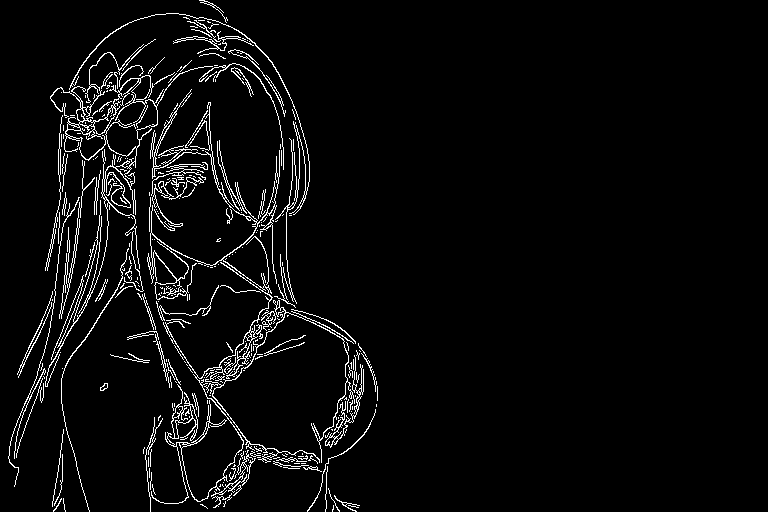

このマスク画像を2枚入力画像として、Multi-Inputsへ与えます。

生成をすると以下のようになります。


このように、マスク画像は複数レイヤのように機能し、複数枚のマスク画像を1枚の生成画像に適用させることができます。
この機能は複数のControlNet Unitを並列で複数処理する為、有効化する場合は、WebUI設定を変更する必要があります。
設定 (Settings) > Uncategorized - ControlNet > Multi-ControlNet: ControlNet unit number
この設定は、WebUIの再起動が必要です。
2024-07-15 14:19:25,989 - ControlNet - INFO - unit_separate = False, style_align = False
2024-07-15 14:19:25,989 - ControlNet - INFO - Loading model from cache: control_v11p_sd15_canny [d14c016b]
2024-07-15 14:19:26,001 - ControlNet - INFO - Using preprocessor: none
2024-07-15 14:19:26,001 - ControlNet - INFO - preprocessor resolution = 512
2024-07-15 14:19:26,340 - ControlNet - INFO - Loading model from cache: control_v11p_sd15_canny [d14c016b]
2024-07-15 14:19:26,352 - ControlNet - INFO - Using preprocessor: none
2024-07-15 14:19:26,352 - ControlNet - INFO - preprocessor resolution = 512
2024-07-15 14:19:26,456 - ControlNet - INFO - ControlNet Hooked - Time = 0.4697611331939697上記のログを見れば、1セクションにControlNetモデルが2回ロードされているのがわかりますね。
入力画像エリアにおける、補足事項を記載します。
Q. 画像リソース・キャンバスの右下にある、これって何?

A.
左から
「新しいキャンバスを作成」
「ウェブカメラを有効にする」
「ウェブカメラを左右を反転させる」
「キャンバスサイズをStable Diffusion側へ適用する」
という機能になります。
デッサン人形などがある場合、ポーズ指定が容易にできる為、ウェブカメラ画像は非常に有益な機能になります。
ControlNet設定部

有効化 (Enable)
ControlNetの適用を有効化します。
低VRAM (Low VRAM)
低VRAMでの処理を優先します。
その代わり、処理速度を犠牲にする為、非常に低速になります。
Pixel Perfect
入力画像に対して、ピクセルレベルでの正確さを維持する設定になります。
一部のタスクにおいて、一定の品質向上が期待できます。
Allow Preview
プリプロセッサで処理されたマスク画像のプレビューを確認することができます。

以下ボタンを押すことで、プリプロセッサのプレビューを作成することができます。

また、Preprocessor Preview内にあるEditボタンを押すことで、マスク画像のキャンバス編集が可能になります。
Effective Region Mask

ControlNetの適用領域を指定する機能となります。
本機能では、白と黒のマスク画像を使用します。
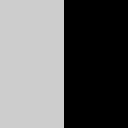
上図の場合、左側(白)が有効領域、右側(黒)が無効領域になります。
ControlNetパラメータ部
Control Type

ControlNetでは推論方式のタイプが複数あります。
これがControlNetの中枢部と言っても過言ではありません。
本機能の詳細については、第2部以降で説明します。
プリプロセッサ (Preprocessor)

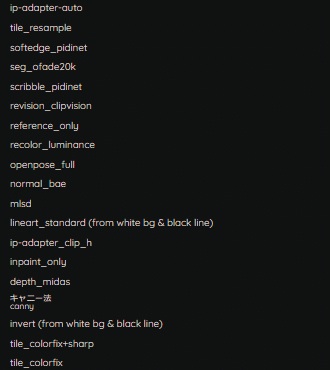
プリプロセッサとは、ControlNetモデルへ引き渡す前に、指定したモデルが適切に処理できる画像にする為の前処理装置(Pre-Processor)のことを指しています。
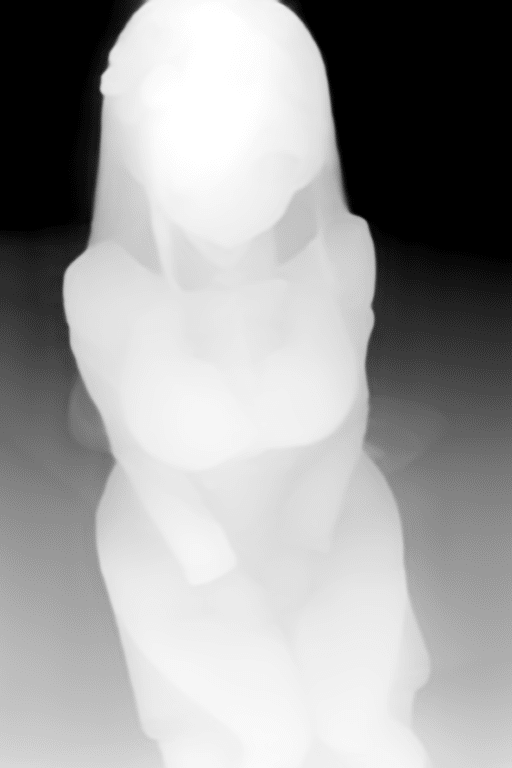
例えば、下図のような画像があったとします。

これを仮に、Depth Preprocessor(深度プリプロセッサ)に通すと以下のようになります。

これは、ControlNet Depth機能において、深度情報を読み取るために必要な前処理です。
入力画像の深度情報を、白黒の濃淡で表現した画像に変換し、ControlNet Depthモデルへ引き渡す為に使用されます。
モデル (Model)

モデルとは、ControlNetモデルのことです。
通常のCheckpointモデルとは異なり、マスク画像から構成情報を推論し、Stable Diffusion U-Netへ追加条件を引き渡す役割を担っています。
Control Weight
Starting Control Step
Ending Control Step
解像度 (Resolution)

Control Weight
ControlNetの適用強度を指定できます。
プロンプトの強調指定・強度指定と似たような役割を持ちます。
例えば、smileというプロンプトの強度を1.2とした場合と同義になります。
e.g.) (smile:1.2)
ポーズ指定などの構図固定(CannyやDepth)では、比較的強い強度(0.8~1)が目安です。
描き込み量(Tile)では、0.4~0.6程度が望ましいと思われます。
Starting Control Step / Ending Control Step
Starting Control Stepは、ControlNetの適用ステップ開始割合を指定できます。
どの程度のステップから、ControlNetの適用を開始するかを指定します。
例えば、
Step : 30
Starting Control Step : 0.2
であった場合、30 Stepの20%である6 Step目からControlNetが適用されます。
Ending Control Stepは、ControlNetの適用ステップ終了割合を指定できます。
どこの時点で、ControlNetの適用を終了するかを指定します。
正しく機能させる為には指定値は「Starting Control Step < Ending Control Step」でなければなりません。
ポーズ指定などの構図固定(CannyやDepth)では、デフォルト(Start 0 - End 1)でも綺麗に反映されますが、描き込み量(Tile)では、Ending Control Stepとの兼ね合いが重要で、調整しないと構図崩壊を引き起こす可能性があります。
解像度 (Resolution)
プリプロセッサの前処理画像(マスク画像)の解像度を指定します。
後述するリサイズモードに影響を及ぼします。
Control Mode
リサイズモード (Resize Mode)
Hires-Fix Option
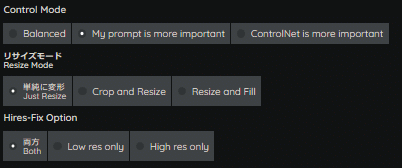
Control Mode
ControlNetは、主経路であるU-Net Blockと追加条件のマージを行う際、主経路側(Stable Diffusion側)か副経路側(ControlNet側)、どちらを優先するかを選択できます。
・Balanced
モデルマージにおける、Alpha=0.5のような役割で、優先度を半々にします。
・My prompt is more important
その名の通り、主経路側(Stable Diffusion側のプロンプト)を優先的にします。
・ControlNet is more important
その名の通り、副経路側(ControlNet側の追加条件)を優先的にします。
基本的にはBalancedで良いですが、構図は固定してキャラクターの見た目を変更したいとした場合は、My prompt is more importantを選択する必要があります。
指定プロンプトを優先するシーンのほうが多いと思いますので、ControlNet is more importantを選択する機会は少ないと思われます。
リサイズモード (Resize Mode)
マスク画像と生成画像の解像度に差異があった際に、どのようにリサイズ(解像度変更)を実行するかを指定します。
・単純に変形 (Just Resize)
アスペクト比を考慮せずにリサイズします。
・Crop and Resize
指定解像度に合ったアスペクト比に切り抜き、アスペクト比を保持したままリサイズを行います。
はみ出た部分は除外されます。
・Resize and Fill
指定解像度に合ったアスペクト比でリサイズされ、空白部分は無効領域としてマスクが埋められます。
Hires-Fix Option
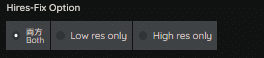
この機能は、Hires.fix機能が有効時のみ選択可能になります。
・両方 (Both)
ControlNet適用ステップをSampling StepsとHires Steps、両方に適用します。
・Low res only
ControlNet適用ステップをSampling Stepsのみに適用します。
・High res only
ControlNet適用ステップをHires Stepsのみに適用します。
[ 技術的補足 ]
本機能の挙動について、各所で詳しい記載がない為、ControlNetスクリプトから読み解いて説明します。
本機能は、至って単純です。
通常のフローで全てControlNetの処理を適用するか、Hires-FixのControlNet処理の適用を有効にするか、無効にするかのみの記述しかありません。
以下は、sd-webui-controlnet/scripts/hook.py内の一部です。
(分岐が多岐に渡ってて長いので、フラグ部分のみ引用します)
def disabled_by_hr_option(self, is_in_high_res_fix: bool) -> bool:
if self.hr_option == HiResFixOption.BOTH:
control_disabled = False
elif self.hr_option == HiResFixOption.LOW_RES_ONLY:
control_disabled = is_in_high_res_fix
elif self.hr_option == HiResFixOption.HIGH_RES_ONLY:
control_disabled = not is_in_high_res_fix
else:
assert False, "NOTREACHED"
return control_disableddisabled_by_hr_option関数にて、is_in_high_res_fix (bool値)がフラグとして参照されるような記述になっています。
この変数は、以降の分岐でフラグとして使用され、通常のSampling Steps処理・Hires-Fix処理を進めるか否かを判断しています。
Both (HiResFixOption.BOTH) が選択されれば、Hires-Fix無効化処理が無効となり、通常フローで進みます。
Low res only (HiResFixOption.LOW_RES_ONLY) が選択されれば、Hires-Fix無効化処理が有効となり、ControlNetによるHires-Fix処理がスキップされます。
High res only (HiResFixOption.HIGH_RES_ONLY) が選択されれば、not is_in_high_res_fixとなっているため、フラグが反転し結果がTrueであれば、ControlNetによるHires-Fix処理自体は有効化されますが、ControlNetによるSampling Steps処理はスキップされます。
いずれも、Stable Diffusion側のHiresFix処理は実行される為、あくまでもControlNet上の処理で完結するものになります。
但し、ControlNetの適用範囲が変更となる為、出力物に大幅な変化が生じると推測されます。
Batch Loopback

この機能は、バッチモード時のみ選択可能になります。
本機能は、マスク画像を指定せずとも、生成画像を取り込んでControlNet処理を行うことができるようになります。
これにより、生成した画像に微細な変化を加えたり、別のプリプロセッサやパラメータで再生成したりすることが可能になります。
Upload independent control image

この機能は、img2img時のみ選択可能になります。
通常、img2img時は画像リソース(入力画像)を選択することができません。
これは、img2imgの特性上、画像全体の特徴量から推論を行っている為です。
しかし、この機能を有効にすると、画像リソースの選択が可能になります。
これにより、img2imgとは独立したControlNet処理が行え、img2img生成画像にも決まった構図の適用などが可能になります。
Multi ControlNet
Multi ControlNetとは、複数のControlNet Unitで画像を処理することを可能にする機能です。
異なるプリプロセッサや、ControlNetモデルを使用して生成画像にControlNet処理することができます。

この機能は、Multi-Inputsモードでも説明しましたが、以下設定の有効化が必要です。
設定後、WebUIの再起動が必要です。
設定 (Settings) > Uncategorized - ControlNet > Multi-ControlNet: ControlNet unit number
上図の例では、Cannyを用いてキャラクター構図を固定したうえで、Tileにて描き込み量・高品質化を行っています。
従来の場合、この作業は一連の中では完結せず、分割で行う必要がありましたが、Multi ControlNetが実装されてからは、一連処理の中で完結することができるようになりました。
おわりに
いかがでしたでしょうか。
今回は、ControlNetの事前知識として基礎的な部分をお伝えしました。
ControlNetは革新的な機能ですので、使わない手はありません!
第2部ではControl Typeについてお伝えします。
次回より、メンバーシップ向け、有料記事となりますのでご承知ください。
構図やポーズの指定に悩まされている方は、是非ControlNetを使用してみてください!
参考文献・引用元
*1 : U-Net Convolutional Networks for Biomedical Image Segmentation - Fig.1 (Olaf Ronneberger, 18 May 2015)
*2 : Below is ControlNet 1.0 - Stable Diffusion + ControlNet (lllyasviel Update commits on Sep 9, 2023)
*3 : Adding Conditional Control to Text-to-Image Diffusion Models (Lvmin Zhang, 26 Nov 2023)
この記事が参加している募集
よろしければサポートお願いします!✨ 頂いたサポート費用は活動費(電気代や設備費用)に使わさせて頂きます!✨