pythonのscikit-learnライブラリで線形回帰を学ぶ

この記事の対象となる人
・pythonの基本的な構文が読める人
・Jupiternotebookの環境が整ってる人
筆者の環境は
OS:Windows10
python:pyton3系
本記事はJupiternotebookを利用しています
です
Mac環境の人などは一部動作が異なる可能性があります
随時読み替えてください
scikit-learn(サイキットラーン)とは
・pythonのライブラリです
・無料で利用できます
・機械学習アルゴリズムがはいってます
・勉強に便利なデータセットつき!←オススメポイントはここ!
単回帰分析とは
「身長が高い人は比例して体重が重くなる」といったような直線の関係の予測に使います
身長 = 回帰係数a・体重 + 回帰係数b
scikit-learnに入ってるbostonデータセットを確認する
最初の準備
from sklearn import linear_model, datasets
from pandas import DataFrameデータセットのロード
boston = datasets.load_boston()このボストンデータの型を確認すると
print(type(boston))<class 'sklearn.utils.Bunch'>です
for boston_key in boston:
print(boston_key)とすると結果は
data
target
feature_names
DESCR
filenameでした
順番に中身を確認します
print(boston["data"])リスト型のデータがはいってるようです
[[6.3200e-03 1.8000e+01 2.3100e+00 ... 1.5300e+01 3.9690e+02 4.9800e+00]
[2.7310e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9690e+02 9.1400e+00]
[2.7290e-02 0.0000e+00 7.0700e+00 ... 1.7800e+01 3.9283e+02 4.0300e+00]
(以下略)print(boston["target"])こちらもリスト型のデータ
[24. 21.6 34.7 33.4 36.2 28.7 22.9 27.1 16.5 18.9 15. 18.9 21.7 20.4
18.2 19.9 23.1 17.5 20.2 18.2 13.6 19.6 15.2 14.5 15.6 13.9 16.6 14.8
(以下略)print(boston['DESCR'])データの説明が入っています。
_boston_dataset:
Boston house prices dataset
---------------------------
**Data Set Characteristics:**
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000'sprint(boston['filename'])これはロードしたデータがどこに保存されたかがわかります
C:\Users\hogehoge\anaconda3\lib\site-packages\sklearn\datasets\data\boston_house_prices.csvpandasを使ってDataFrame化していきます
dframe = DataFrame(boston.data)とすると
0 1 2 3 4 5 6 7 8 9 10 \
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0 15.3
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0 17.8
(以下略)となります
辞書bostonのキー"data"のvalueのリストの0番目がどうだったか見てみましょう
print(boston["data"][0])0番目のリストの値が、二次元の表になっていることがわかります
[6.320e-03 1.800e+01 2.310e+00 0.000e+00 5.380e-01 6.575e+00 6.520e+01
4.090e+00 1.000e+00 2.960e+02 1.530e+01 3.969e+02 4.980e+00]しかしこのままだと列名がないので何番目の列がなんのデータを示しているのかわかりません。
feature_namesから列名を取得します
print(boston.feature_names)とすると出力結果はいかになります
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']columnsパラメータで列名を指定をします
dframe.columns = boston.feature_names確認してみましょう
print(dframe)となり、列名が付与されてるのがわかります
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0
(以下略)dframe.head()を使うとより表っぽく描画されるので、見やすいです
printだと列が長い場合折り返されてしまうので確認には不向きです
.head()は最初の5行を表示します
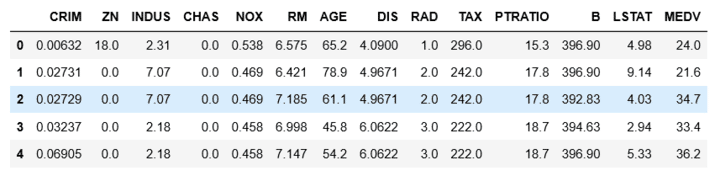
この先は有料です!
さきほどの「print(boston['DESCR'])」で確認したデータの説明には「Number of Attributes: 13 numeric/categorical predictive. Median Value (attribute 14) is usually the target.」とありました。翻訳すると「属性数:13数値/カテゴリー予測。通常、中央値(属性14)が目標です。」と言っています。「print(boston.feature_names)」としたときに13個の要素しかありませんでした。「属性14が目標です」と説明にあります。これはデータセットの中にあった「target」のことを指しています。つまり説明にある「MEDV Median value of owner-occupied homes in $1000's」とは「target」のことです。
相関係数で相関関係を確認する
RM(平均部屋数)とMEDV(住宅価格の中央値(1,000単位))に相関関係があるか確認しましょう。
まず DataFrameに「target」の列と値を追加しましょう
dframe['MEDV'] = boston.targetとした後に
dframe.head()で確認すると
一番左端の列に「MEDV」が追加されているのが確認できます
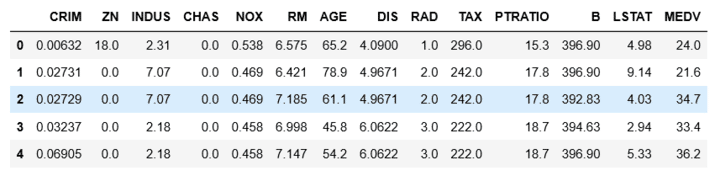
dframe[['RM','MEDV']].corr()とすると
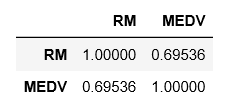
となります。
相関関係係数のだいたいの目安は下記です
0.2 → ほとんど相関はない
0.4 → 弱い正の相関
0.7 → 正の相関
結果は「0.69536」だったので正の相関があることがわかります。
つまり、1住居当たりの部屋数が増えると、相関して住宅価格の中央値(1,000単位)は上昇するということです。
相関関係をプロットして視覚的に考えてみましょう
boston = datasets.load_boston()
dframe = DataFrame(boston.data)
dframe.columns = boston.feature_names
rm = dframe['RM']
medv = boston.target #medv = dframe['MEDV']
plt.scatter(rm, medv)
plt.title('title')
plt.xlabel('X_RM')
plt.ylabel('Y_MEDV')
plt.grid()
plt.show()とするとプロットされます。X軸の部屋数が増えると、Y軸の住宅価格の中央値も上昇傾向にあることが視覚的にわかります。
視覚と数値その両方で捉えることで、相関関係があるかどうかを確認していきました。
線形回帰モデルを作る
room_training = DataFrame(dframe['RM'])とすると指定した列のみが抜き出されます
print(room_training)確認すると
RM
0 6.575
1 6.421
2 7.185
(以下略)
同じようにtargetの情報もDataFrame化しましょう
prices_training = DataFrame(boston.target)「print(boston["target"])」で確認したデータは
[24. 21.6 34.7 33.4 36(以下略)でした
print(prices_training)で確認すると
0
0 24.0
1 21.6
2 34.7二次元の表になっていることが確認できます
モデルを作る
さて、抜き出した「RM」のデータと「target」のデータを使ってモデルを作っていきましょう
LinearRegression = LinearRegression()
LinearRegression.fit(room_training,prices_training)学習させたモデルを描画してみます
plt.scatter(room_training, prices_training, color = 'blue')
plt.plot(room_training, Linear_Regression.predict(room_training), color = 'red')
plt.show()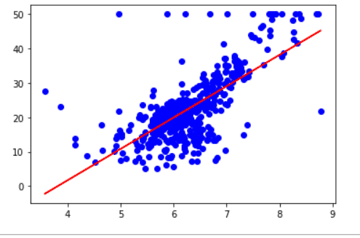
この記事が気に入ったらサポートをしてみませんか?