XLOOKUPとINDEXMATCHと構造化参照

前提
上記2つの記事を踏まえた内容です。
INDEXMATCHとXLOOKUP
オプションの材料
前の記事では、INDEX関数とMATCH関数を組み合わせた検索抽出方法を紹介しました。そこでは、INDEX関数の材料が、
データを取り出す範囲
範囲での縦番号
範囲での横番号
であるのを利用して、2番目と3番目の材料にMATCH関数を入れる事で柔軟な検索と抽出が可能であるのを示したのでした。
ここで改めて、INDEX関数の材料を見てみましょう。

列番号とは、横番号を示します。調べたい範囲について、縦方向に串を刺していったとして、抽出したいデータが左から何番目の串に刺されているかを数える、というようなイメージです。
よく見ると、列番号は角括弧で括られています。既に説明したように、角括弧がついているのはオプション、つまり、入れなくても良い材料を示します。であれば、INDEX関数は、横番号は入れなくても機能します。これは、
探す範囲の幅が1セルであれば、縦番号だけで抽出できる
のを意味します。やってみましょう。
幅1セルのINDEX関数

まず1番目の材料、つまり、取り出したいものが入っている範囲です。以前は、表のデータ部分全体を示しましたが、今回は、抽出部分に絞る、つまり、単価が記載されている範囲のみを指定します。いまで言うとH2セルからH9セルの範囲です。単価の縦並びなので、範囲の幅は1セルです。
次に、

MATCH関数を2番目の材料に入れます。INDEX関数の2番目の材料は縦番号でしたので、ここでは、うにがネタ並び、つまりI2からI9までのセル範囲の何番目にあるかを探せば良いです。単価並びとネタ並びは同じ表のデータで、セル範囲の長さが同じですから、ネタ並びの縦番号が取得できたら、1番目の材料で指定した範囲での同じ場所にある単価を抽出してくる、という寸法です。

列番号、つまり横の番号はオプションでした。1番目の材料は幅が1セルで横番号の情報は必要ありませんので、オプションは入れずに閉じましょう。
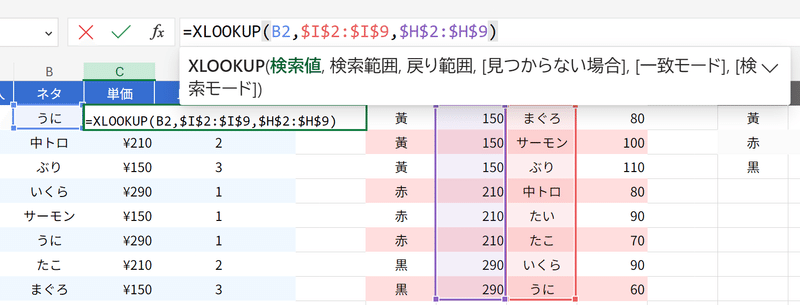
=INDEX($H$2:$H$9,MATCH(B2,$I$2:$I$9,0))
成功しました。このように、INDEX関数は、横番号(列番号)を指定しなくても、データを取得する事ができます。
XLOOKUP関数と似ている
この、INDEX関数とMATCH関数を組み合わせた数式の構造、何かに似ていませんか? そうです、XLOOKUP関数です。XLOOKUP関数は、
検索したいもの
検索に行く範囲
抽出する範囲
この3つの材料が最小限のものでした。先ほどのINDEX関数は、オプションを除くと
抽出する範囲
縦番号
でしたが、縦番号はMATCH関数で取得し、MATCH関数の材料は

検索したいもの
検索に行く範囲
でしたので結局、必要な材料は
抽出する範囲
検索したいもの
検索に行く範囲
となる訳です(MATCH関数の検索条件は省いています)。
これを見れば解るように、幅が1セルの範囲を指定したINDEXMATCHとXLOOKUP関数は、同様の構造を持っています。ただし、材料を投入する順序が異なります。
前に言及したように、XLOOKUP関数は比較的新しいものなので、Office2019までのExcelには搭載されていません。業務上では様々のバージョンを使用する可能性があるので、2021かMicrosoft 365を使うのが確実で無い場合は、INDEXMATCHの組み合わせを使うのが無難です。
エラーハンドリング
XLOOKUP関数で便利なのは、見つからない場合の出力が指定できる所です。処理の結果がエラーの場合におこなう処理をエラーハンドリングと言いますが、XLOOKUPにはエラーハンドリングが組み込まれているのが重要です。INDEXMATCHにはエラーハンドリングがありませんから、IFERROR関数などで挟んで処理する必要があり、少し複雑になります。そういう訳ですので、使えるのならXLOOKUP関数を使ったほうが良いでしょう。
構造化参照
名前参照
ここまでの説明は、セルアドレス(A1やH9など)を書いて範囲を指定しました。INDEXやMATCH、LOOKUP系関数のように、見に行く(参照する)範囲を固定する場合、$をつけてずれないようにする必要があります。これを絶対参照と言うのでした。しかし、絶対参照はつい忘れますし、単純に読みにくいです。そこで、いまから表をテーブルにしていきます(テーブル化の操作説明は省く)。
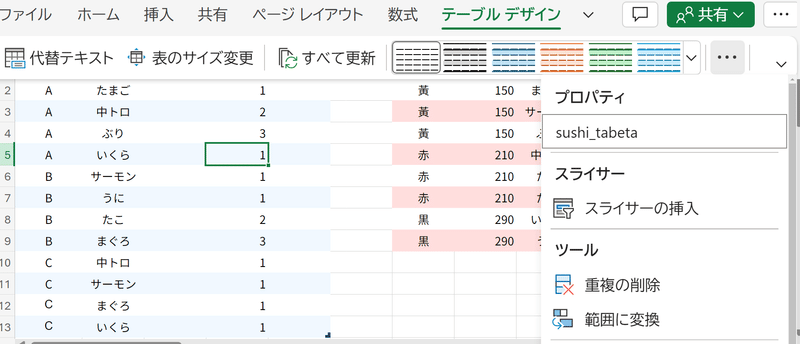
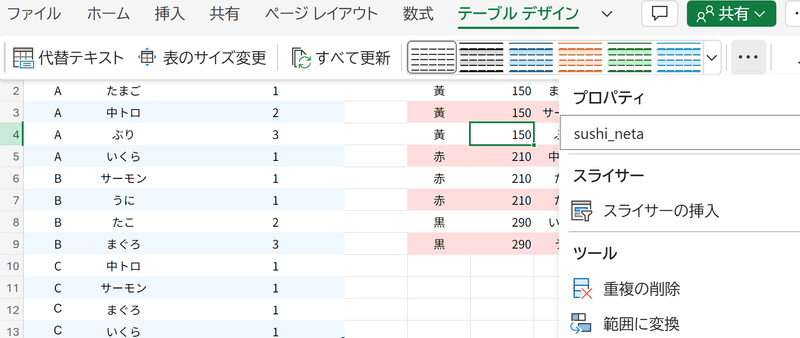
ここでは、左側の表をsushi_tabetaテーブル、右側の表をsushi_netaテーブルと定義しました。こうする事によって、範囲を名前で指定するのが可能となります。
セル範囲の名前については、

数式ボックスの左にある名前ボックスに名前を入れれば直接、セルに名前でアクセスできるようになりますが、
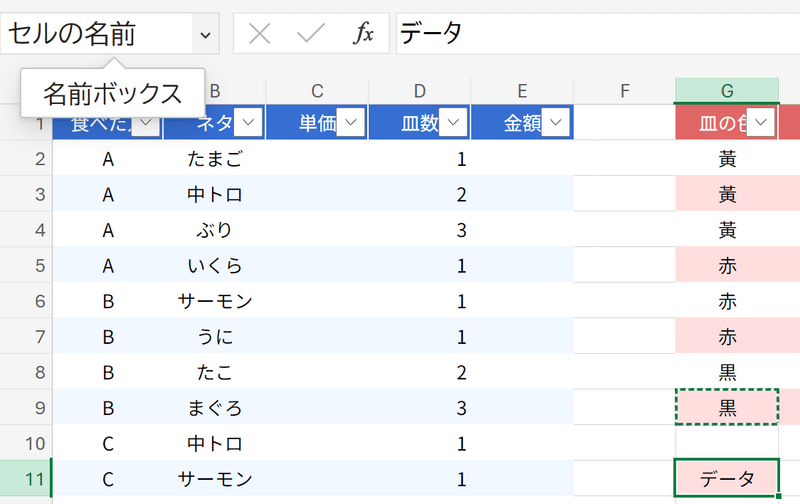
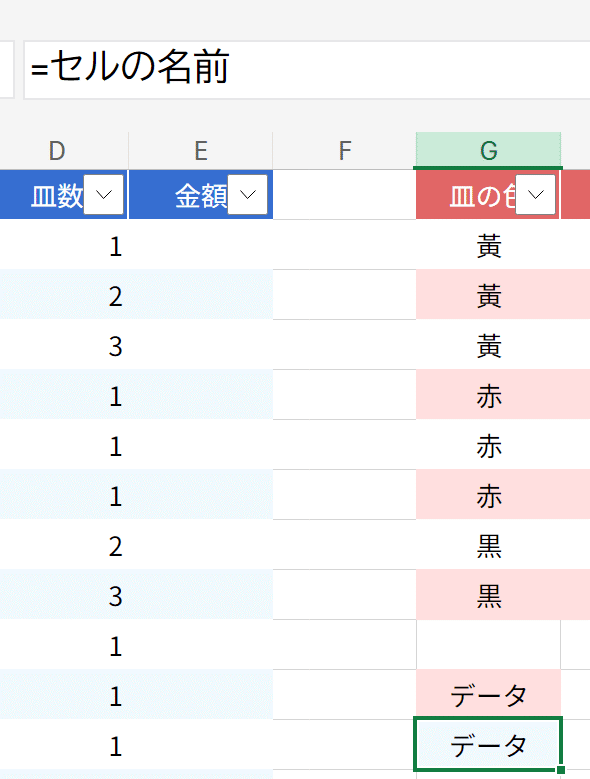
テーブル化することで、
見出し範囲
データ範囲
縦並びのデータ範囲
などの名前指定が自動的に追加されます。
構造化参照


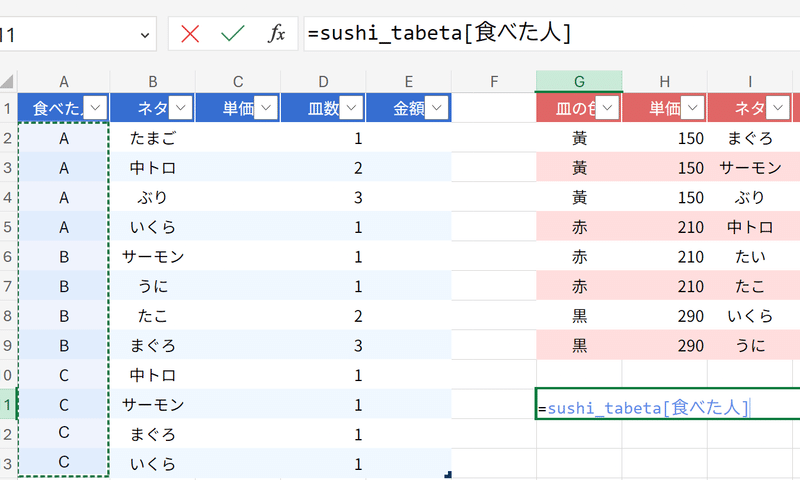


そして、このようにテーブル化して得られた、テーブル名と縦並び名を組み合わせてセル範囲を参照するのを
構造化参照
と言います。これは、Excelにおいて極めて強力な機能です。では、構造化参照を使って数式を書いてみましょう。

=INDEX(sushi_neta[単価],MATCH([@ネタ],sushi_neta[ネタ],0))数式はこのようになります。セルのアドレスは1つもありません。これを分解すると、
sushi_neta[単価]→sushi_netaテーブルの単価データ範囲
[@ネタ]→数式を入れるセルと同じテーブルにある真横のセル。横並びは行と表現され、@は同じ行を表す
sushi_neta[ネタ]→sushi_netaテーブルのネタデータ範囲
こうです。名前で指定しているので、セルのアドレスで指定するよりも、どこを指定しているのかが明白となっています。では数式を確定しましょう。

あれ、データが見つかりませんね……ああそういえば、この前に、ネタをたまごに書き換えていたのでした。であれば、sushi_netaテーブルにはたまごがありませんから、見つからないのは当然です。では、sushi_netaテーブルに、たまごを追加してみましょうか。
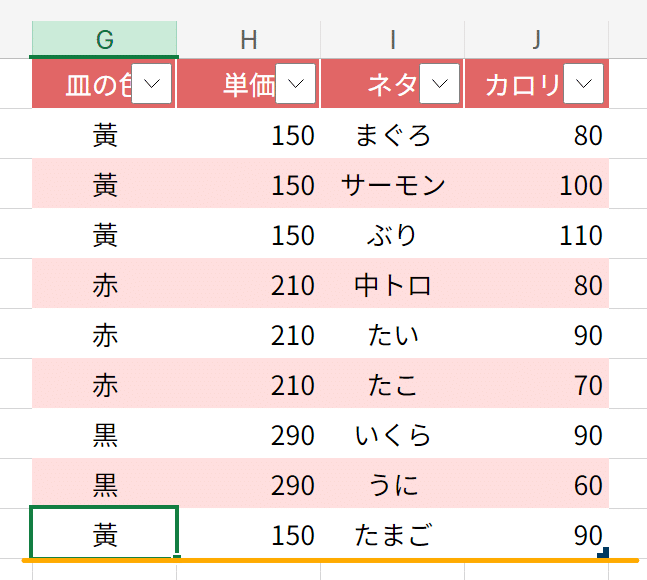

たまごを追加する事で、上手くネタを検索できました。……あれ、よく考えたら、いまやったのは、sushi_netaテーブルの一番下に、たまごのデータを追加しただけです。INDEX関数の範囲もMATCH関数の範囲も変更していません。セルアドレスで指定した時は、範囲を固定して絶対参照したので、その範囲をいちいち広げる必要があります。けれどいまは、たまごを追加しただけで、自動的に範囲が広がったようです。

実はこれが、構造化参照の威力です。構造化参照は、範囲をテーブル化した事による、自動的に設定される名前を使用した参照を言うのでした。そこでは、データ部などを名前で指定します。アドレスを直接書いてH2からH9までの範囲、とするのでは無く、sushi_neta[単価]とする事で、
sushi_netaテーブルの単価データの所
という風に名前で示している訳です。そして、そのデータ部の範囲が変化すれば、INDEXやMATCHで参照している範囲も自動的に変化するというしくみです。テーブルは、標準の設定では、一番下にあるデータの真下に入力すると、自動的に範囲が拡張されるようになっていますから、構造化参照にもそれが反映されるのです。よくできています。
たとえば、組織におけるメンバーを指定する際に、名簿のここからここまでの人、と指定するのでは無く、◯◯部署の人、と指定すれば、◯◯部署の内部でメンバーの入れ替えがあったとしても対応できますね。構造化参照はそういうものだと考えれば良いでしょう。
構造化参照によるXLOOKUP
XLOOKUP関数を構造化参照で書きます。
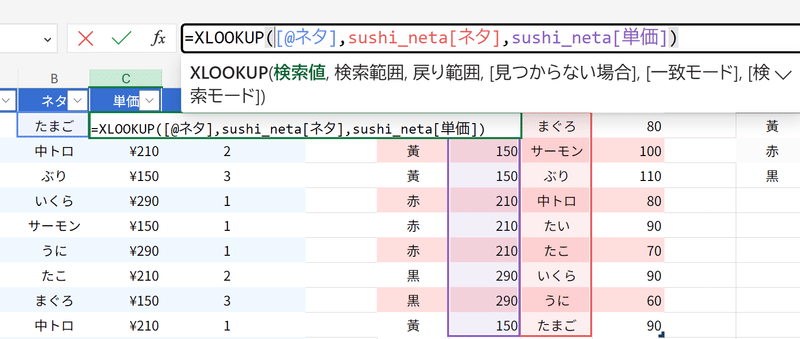
INDEXMATCHは数式が入れ子になっていたのでいくらか複雑ですが、XLOOKUP関数を構造化参照で書くと、実に解りやすいですね。アドレスでは無く、テーブル上での名前で指定するので、数式の意味が直感的に把握しやすくなりますし、範囲の拡張に柔軟に対応できるのは、先ほど紹介した通りです。
そういえば、テーブルで金額の所を入れるのを忘れていました。入力しましょう。
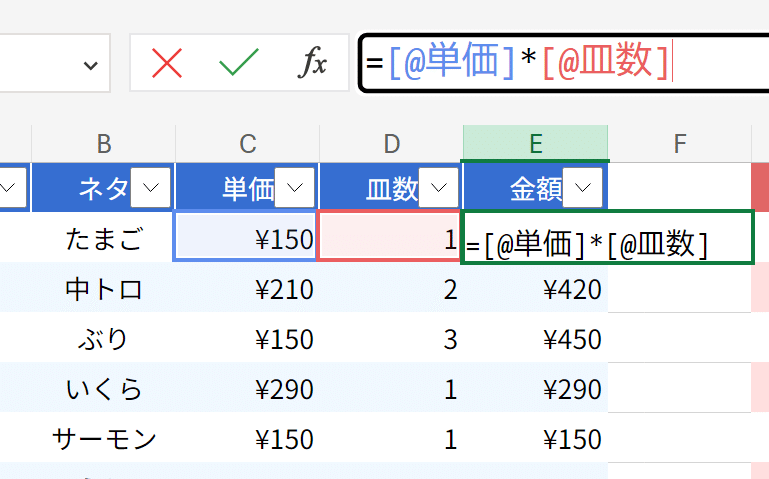
何と何を計算に使っているかが明確ですね。同じテーブルの同じ横並び(行)にある単価と皿数をかける、という意味をそのまま表現できます。ちなみに、標準の設定では、1つだけ数式を入れれば、縦並びに同じ数式が入ります。数式には@があるので、全く同じ数式でも異なる場所が計算されるのです。@は、数式があるセルと同じ行を指すからですね。XLOOKUPの1番目の材料も同様です。
ここも構造化参照の強みです。

テーブル化と構造化参照のすすめ
ここまで紹介したように、構造化参照は、
範囲を名前で指定できる
テーブル構成の変更に動的に対応できる
全く同じ数式で異なる行の計算に対応できる
という特徴があります。これは、数式を書く時にも直感的ですし、絶対参照などに気を遣う必要も少なくなります。同じ数式で良いのは可読性を高め、数式の管理がしやすいです。
動的な対応は他に、入力規則のリストの定義や、FILTER関数の参照範囲の自動拡張にも対応できて便利です。FILTER関数はスピルされますが、参照する範囲がテーブルで構造化参照すれば、テーブルの拡張に応じてスピルも自動的に拡張されます。
私は、他者が作成したブックをそのまま使用して使わなくてはならないという要件が無い限り、データを入力する表については、必ずテーブル化します。テーブルは1つのデータベース的な領域となって、数式の作成や他からの参照に適した構造を有します。テーブル領域の自動拡張や、数式の一括反映も便利です。
また、地味なようで大きなメリットとして、テーブル内ではセルの結合が許されません。結合が受け付けられなくなるので、データ領域としての整然とした構造を維持させる事ができるようになります。セルの結合は、帳票出力などアウトプットの最終段階で実施するべきものであって、データ入力時にはおこなわないほうが良いものですが、それをあらかじめ制限できる訳ですね。
まだ使ったことがないとか、テーブルは単にレイアウトや書式を一括設定できるようにするだけだと思っていたかたには、是非おすすめしたい機能です。
参考資料
この記事が気に入ったらサポートをしてみませんか?