INDEX関数とMATCH関数の組み合わせによるデータ取得のしくみ

はじめに
前回の記事では、データを縦に探して行って、見つかったら真横にあるデータを返すVLOOKUP関数のしくみを説明しました。
そこで説明したように、VLOOKUP関数には、探す範囲の縦並びが左端に無ければならない、などの弱点があります。そういう事情から、VLOOKUP関数を説明する流れで、もっと便利なやりかたとして、
INDEX関数
MATCH関数
この関数を組み合わせたものに言及される場合があります。本記事では、そのしくみについて説明をおこないます。
注意事項
今回はExcelを使います。
VLOOKUP関数の性質
前回の記事で作ったのと同じような表を用意しました。

前回は、左の表の単価の所をVLOOKUP関数で探すしくみを、説明したのでした。
おさらいすると、見つけたいもの、たとえば"中トロ"について、真ん中の表の左端の縦並びを探して行って、見つかったら、同じ横並びにあるデータ、いまは、左から3番目の210を返してくる、というのがVLOOKUP関数です。
左端しか探せない
VLOOKUP関数には、左端の縦並びからしか探せない制限があります。この場合、たとえば左端に別のデータを並べたりすると、VLOOKUP関数で探しに行く範囲を変更する必要があります。

上図の真ん中の表は、左端に番号の並びがあります。番号は最初に入れる事が普通ですが、他のデータが後から追加される場合もあるでしょう。その時には、関数で見つけに行く範囲を変更する必要があります。
このようなケースでは、後から範囲を変更すれば良いので、ちゃんと働くように適応出来ます。
取り出したいものが左にあったら
問題は、
取り出したいものが、見つける範囲より左側にある
場合です。

上図では、単価がネタの左にあります。VLOOKUP関数では、取り出す所の番号を指定するのでした。これは、1以上の整数の必要があります。探したい縦並びを1と基準にして、そこまたは右側しか指定できないからです。
他の関数などでは、基準より右側を正の数、基準より左側を負の数で表す場合があります。数学のグラフを思い浮かべてください。それならば、1つ左側には、-1を指定すれば良さそうですが…

このように、エラーが発生します。これは、VLOOKUP関数が、
範囲の左端から探して、それより左側からは取り出せない
ように定義されているからです。左端しか探せないから、それより左側は、どうやっても範囲外になります。
柔軟性に欠ける
いまの例であれば、ネタから単価を探すだけなので、その並びを変更すれば済みます。しかし、実務においては、もっと大きな表を扱いますし、検索をするバリエーションも増えて行きます。したがって、取り出したいものが探したい所より左側になるケースは大いにあり得ます。
そういったシチュエーションの場合だと、VLOOKUP関数は使えません。もちろん、だからと言って、VLOOKUP関数が役に立たないとかそういうものではありません。弱点とは書きましたが、これはあくまで、こういう事をやりたい時には使えない、との話であり、使う場面が限られているので使い所を見極めるのが重要です。
INDEX関数とMATCH関数の組み合わせ
交差した点
真ん中の表(図では左。以後、3つの表を前提として表現)に着目します。
いま見つけたいのは中トロの単価、選択セルの210です。VLOOKUPは、縦に中トロを探して、見つかったら左から3番目の210を返したのでした。では今度は、
縦の並びと横の並びを同時に見る
のを考えましょう。
INDEX関数
対象の範囲はキリ良く、表のデータ部分(見出しを除いた部分)とします。その範囲で中トロの単価を、縦並びと横並びを同時に考慮して表現すると、
上から4番目で
左から3番目
となります。つまり、数学の座標の表現で表すと$${(4,3)}$$です。ただし、Excelのような表計算アプリケーションでは、下に行くほど数字が増えます。そして、このような観点で対象を検索する関数が、INDEX関数です。
INDEX関数のしくみ
INDEX関数のしくみはこうです。おさらいですが、関数とは、材料を渡して結果を返してもらうしくみの事したね。
=INDEX(探しに行く範囲またはデータの配列, 縦並びの番号, 横並びの番号)1番目の材料は、探しに行く範囲またはデータの配列です。範囲はもちろんセルの集まりです。配列というのは、データ自体が2方向に並んだものを言いますが、ここでは省きます。2番目と3番目の材料は、先ほど書いた、縦並びと横並びの番号です。実際に書いてみましょう。
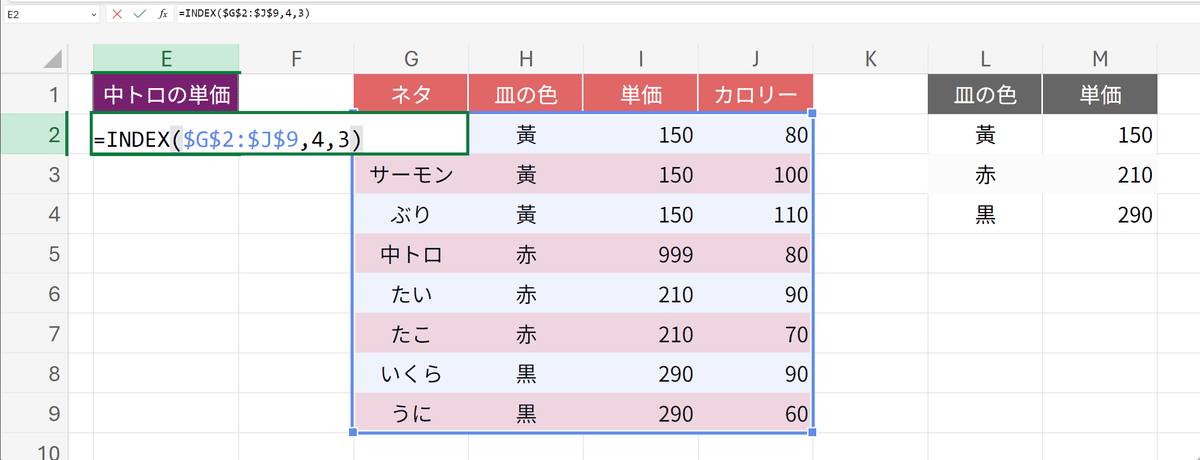
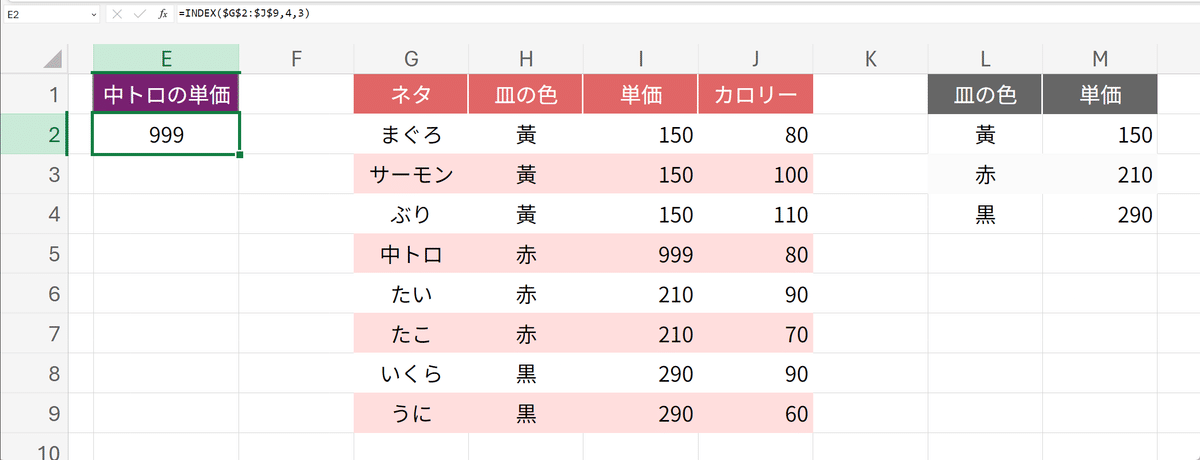
=INDEX($G$2:$J$9,4,3)同じ単価が複数あるので、ここでは中トロの単価を999と入れてあります。このように、INDEX関数を使えば、ある範囲内での縦横の番号を指定して、交差した所にあるものを取得できるのです。
直接数値を指定しても…
INDEX関数を使えば、数値2つの組み合わせで位置を指定して範囲内から取り出す事ができる、つまり座標的に指定するアプローチができます。こうすれば、範囲内であればどこでも対象にできます。
しかしです。このままだとINDEX関数は使い物になりません。と言うのは、いまは縦横並びの数値を直接書いたからです。これだと、INDEX関数の中の数値2つを、食べたネタの分だけ書いて行かなくてはなりません。そんな事をするくらいなら、単価を直接書いたほうが良いのは言うまでもありません。だから、INDEX関数を目的に合わせて運用するなら、
縦の並びを自動的に取得する
方法が必要です。縦に限定するのは、いまの例だと、単価が横の3番目にあるのは判っているからです(横並びについては、後で改めて言及します)。
MATCH関数
対象にしているのは中トロです。そして、関数とは、材料を渡して結果を得るものです。ですから必要なのは、
"中トロ"を渡したら4が返ってくる関数
です。その役割を担うのがMATCH関数です。
MATCH関数のしくみ
MATCH関数のしくみを見ます。
=MATCH(見つけたいもの, 見つけに行く範囲または配列, 見つけかた)1番目と2番目の材料は、VLOOKUP関数と同じです。つまり、いまの例では"中トロ"が1番目です。2番目も同じですが、MATCH関数では、範囲の方向は、縦でも横でも構いません。いまは縦並びを探しているので、縦範囲を入れましょう。
3番目の材料、VLOOKUPに似ていますが異なります。0(FALSE)が完全一致なのは同じですが、MATCH関数の場合は、他に2つあり、
1:見つけたいもの以下で最小の値
-1:見つけたいもの以上で最大の値
を返します。要するに、近いものを探す(近似一致)という意味です。VLOOKUP関数でもそうでしたが、あらかじめ範囲を、小さい順や大きい順で並べておく必要があります。もちろん、いまは中トロに完全に一致するのを探すのが目的なので、0を入れます。中トロに近い何かの単価を返されたら堪りません。実際に書きましょう。


=MATCH("中トロ", $G$2:$G$9)返ってくるのは位置です。値ではありません。中トロを探して中トロを返すのでは、少なくともいまの用途では使えません(存在確認などでは使えます)。こうして、ネタの位置を自動的に取得する事ができました。これを、寿司食べた表に追加すると、このようになります。
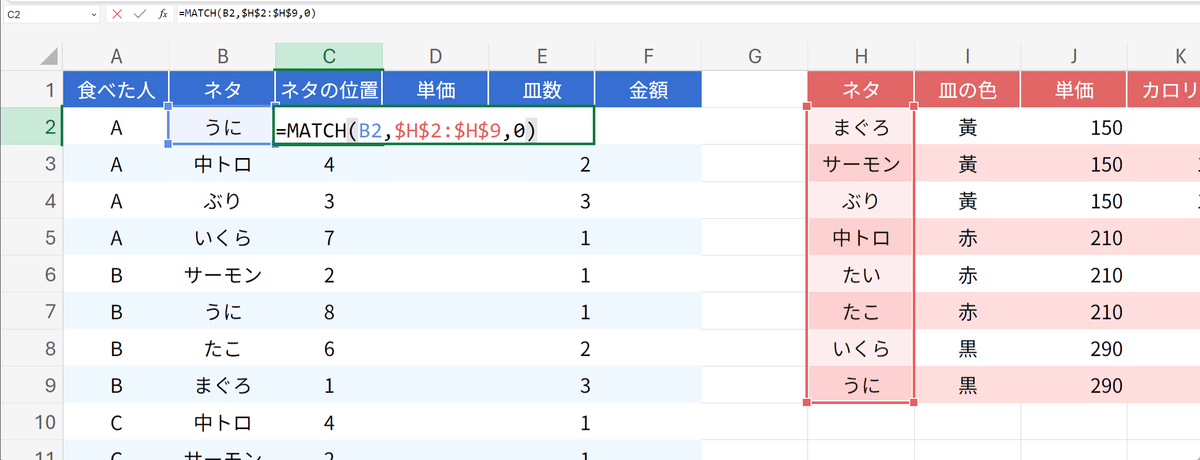
真ん中の表のネタ並びの何番目であるかを、取得できていますね。
再び、INDEX関数
INDEX関数に直接数値を入れても、それでは使い物にならないのでした。しかしいま、縦並びをMATCH関数によって取得しました。後は、これを組み合わせれば、単価が取得できるはずです。
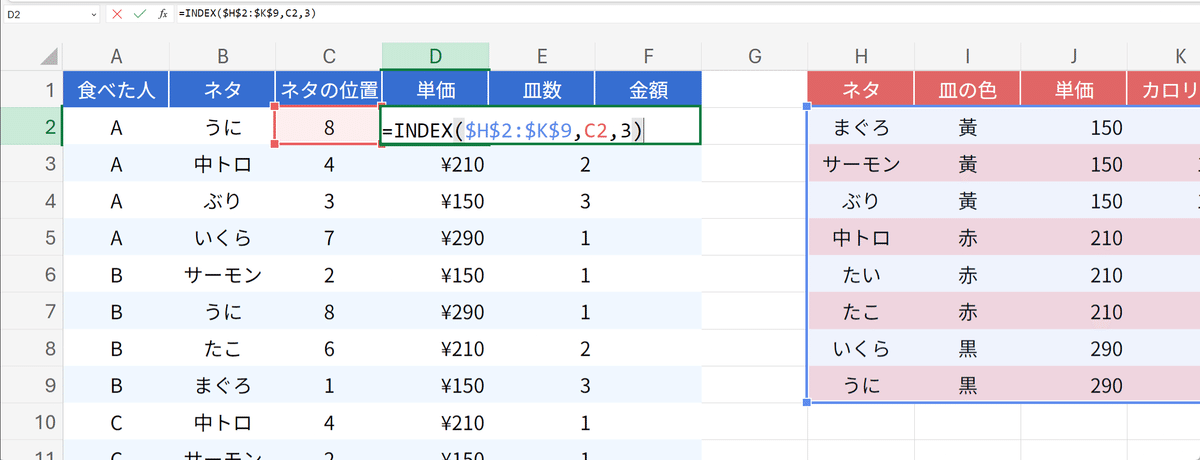
上手く行きました。ネタの位置はCの所で取得してあるので、それをINDEX関数の材料として入れ込めば、ちゃんと目的の単価を返してきてくれるという寸法です。
左にあっても取れる
VLOOKUP関数の弱点は、探したい所より左側のものを取得できない所でした。しかし、INDEX関数では、範囲内で好きな所を座標で指定できます。先ほどは、取得する横番号を3にしましたが、もし単価がネタより左側にあっても、この番号を変更するだけで済みます。
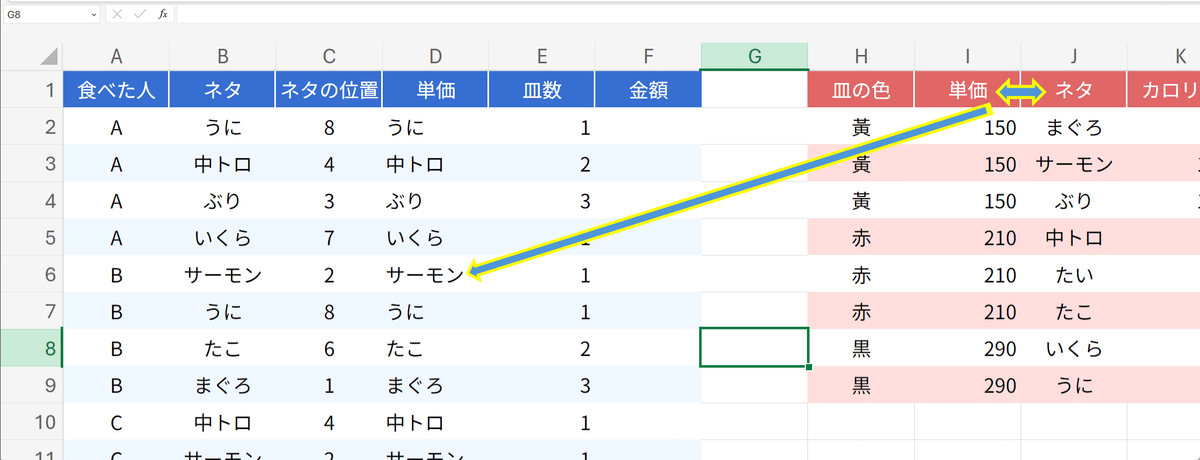
上図をご覧ください。真ん中の表で、ネタと単価を左右入れ替えました。そうすると、左の表での単価がネタになっているではありませんか。これは、INDEX関数の横番号で3を指定したからです。真ん中の表でネタと単価を入れ替えたら、左から3番目にあるのはネタなので、INDEX関数でネタが取得されてしまった訳です。ですから、この数値を2にすれば上手く行くでしょう。

横もMATCH
探す範囲で、取得したいものが左側にあっても、INDEX関数で対応できる事が解りました。また、左右の並び替えが起きても、INDEX関数材料の横番号を変更すれば、上手く対応できます。
しかし、横番号をいちいち、変更に応じて入れ直すのも今ひとつです。どうしましょうか。
そういえば、MATCH関数では、
探す範囲が横方向でも良い
のでした。となれば、後は簡単です。

上図のように、真ん中の表の見出し(横並び範囲)での、"単価"の場所をMATCH関数で取得してやります。そして、

このように、自動取得した縦番号と横番号をINDEX関数に入れれば、見事に目的が達せられました。めでたしめでたし。
実務での使いかた
1つにまとめる
このように、INDEX関数とMATCH関数を組み合わせれば、対象の範囲内の、好きな位置のデータを取り出す事ができます。これはかなり強力です。
この応用として、関数を1つにまとめるのも可能です。やってみましょう。

上手く取得されていますね。数式を示します。
=INDEX($G$2:$J$9,MATCH(B2,$I$2:$I$9,0),MATCH("単価",$G$1:$J$1,0))…長いですね。
可読性
このように、複数の関数を1つの数式にまとめれば、表を拡張せずに済みます。しかし、数式にあまり詰め込むと、このように長くなってしまい、ぱっと見では意味が解りにくくなります。つまり、可読性を損ないます。これは、実務において、保守する際などに問題になります。充分にしくみを理解しない人が引き継いだりする場合、メンテナンスが困難になったりします。そういう羽目になるのであれば、最初にやったように、数式を関数ごとに分けておいて、セルを見に行く(参照と言うのでした)ようにしてまとめたほうが、作業しやすいしメンテナンスも容易です。また、このように、業務上で必要なデータでは無いが、数式での参照で使用するような縦並びの集まりを、作業列などと言います。
関数を新しく習得して行くと、ついそれを詰め込んでしまいがちです。でも、数式は、まとめれば良いというものではありません。数式をどのように構成して行くかは、チームのメンバーの習熟の度合い、表にどれくらい作業列を追加するのが許容されるか、など色々の条件が関わってくる、ケースバイケースのものです。
可読性を高める工夫
もし1つの数式に複数の関数を組み合わせて入れる場合、次のような工夫ができます。

一般にプログラミング言語では、
適宜、改行を入れる
数式が入れ子になっていれば、空白を入れて揃える:インデント
このように工夫をして、可読性を高める事ができます。Pythonのように、インデントそのものがプログラムの構造と密接に関わるものもありますが、それは措いておきます。
上図の数式では、Altキーを押しながらEnterキーを押す事による、数式内改行を使って、スペースでインデントを入れています。知らないかたも結構あると思いますが、実はこうしても、ちゃんと関数は働くのです。
ちょっと長くなった数式は、このような工夫によって、格段に可読性を高められます。上のINDEX関数では、範囲・縦番号・横番号の区別がつきやすくなりました。
もっとも、あまり長くなると今度は、数式ボックスを大きく広げないといけなくなり、それが煩わしくなります。シートの表示部分も小さくなってしまいます。やはり、長い数式を無理に入れずに、作業列を使うのを検討しましょう。
適宜使い分ける
ここまで説明してきた、INDEX関数とMATCH関数の組み合わせは、
範囲のどの場所でも柔軟に取得できる
処理が早い
などのメリットがあります。しかし、先ほど言ったように、数式が長くなり可読性が落ちたり、作業列を増やす必要が生じたりする事もあります。VLOOKUP関数の処理が重いという話もありますが、速度は改善されていますし、実務上で扱うデータの規模で、あからさまに速度低下が業務に支障をきたすのは、それほどありません。縦並び数十万にも達するようなデータであれば、そもそも無理にExcelで処理する必要も無いです。つまり、こういうのは、要件に合わせて選択して行けば良いのです。
おまけ
前回の記事では、
なお、Excelなどには、このような失敗を少なくし、数式を格段に読みやすくできる構造化参照なる強力な機能がありますが、
ここはVLOOKUPの欠点として挙げられる事があります。そして、それを解消するために別の方法を使ったり、新しい関数が生まれたりした
このように書きました。ここで、上記の方法を使ったやりかたを紹介しておきましょう。おまけなので、詳しい説明は省きます。こういうのもありますよ、くらいでお読みください。
その内に説明するかもしれません……。
INDEX関数を使う
表は全てテーブル化しておきます。説明と判別のため、テーブル名に_tableが入っています。

=INDEX(
neta_table,
XMATCH([@ネタ],neta_table[ネタ]),
XMATCH(history_table[[#見出し],[単価]],neta_table[#見出し])
)ネタテーブルのデータを参照し、XMATCHで行番号、列番号を取得しています。構造化参照しているので、番地を書いての絶対参照は不要です。名前参照でありテーブルの拡張にも自動的に対応します。XMATCHの一致モードのデフォルトは0なので、明示不要。
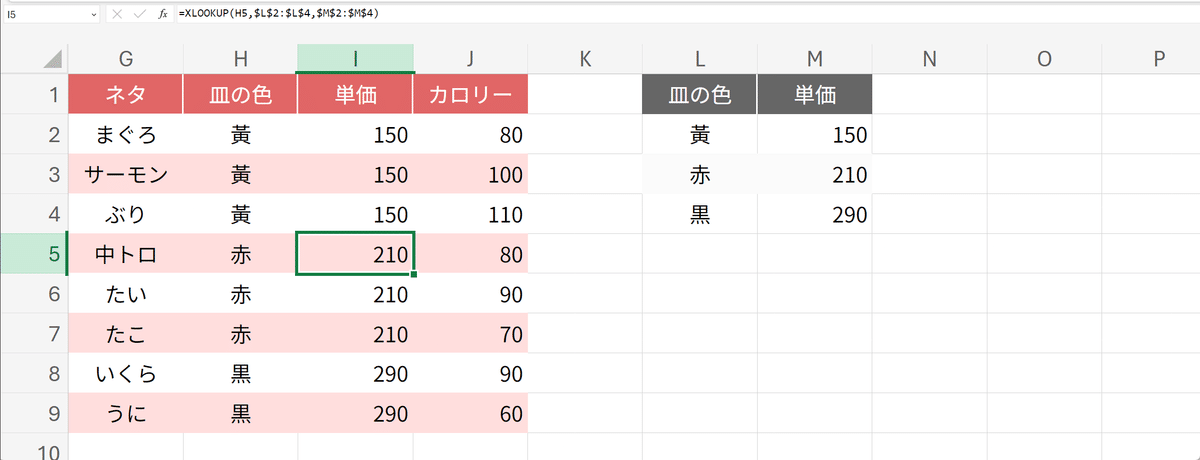
XLOOKUP関数を使う

実に簡潔ですね。
=XLOOKUP([@ネタ],neta_table[ネタ],neta_table[単価])構造化参照を使っているので明瞭です、
同じ行のネタを、ネタテーブルのネタ列に見に行って、そのテーブルの単価列から返す
これだけです。
実際の所、XLOOKUPがあれば、INDEXとMATCHの組み合わせは、実務上はそれほど必要無いと思われます。数千行くらいなら、速度低下など気にもなりません。実際に私は、Office 2019までで書いたINDEXMATCHを見つけたら、XLOOKUPに書き直しています。もちろん、使用者が2021以降を使うのが判っている場合に限り、ですが。