Chat Vectorで遊ぶメモ

このメモを読むと
・Chat Vectorを試せる
・ローカルLLMへお手軽にスキルを付与できる
・マージはGPU不使用
検証環境
・OS : Windows11
・Mem : 64GB
・GPU : GeForce RTX™ 4090
・ローカル(pyenv+venv)
・python 3.10.11
・2024/6/E時点
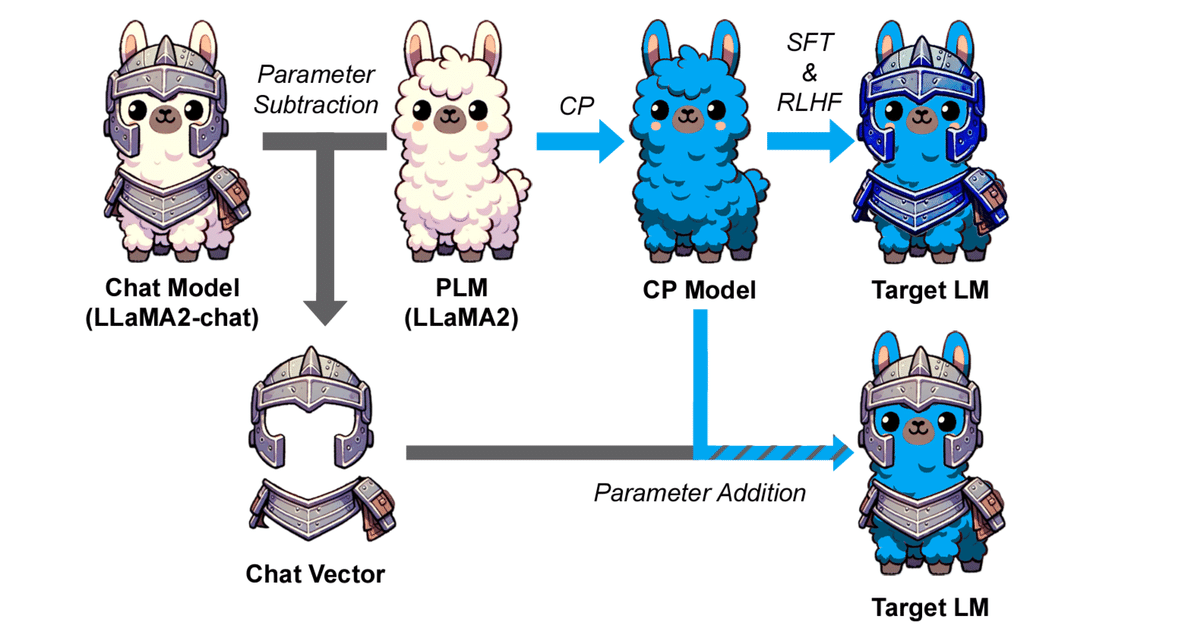
Chat Vector
個人でLLMを育てる際、今まで主だった手法はLoRAなどのファインチューニングでした。データセットの整備や計算資源の制限など、遊ぶにはハードルが高いですよね。
Chat Vectorを使えばチューニング済みのモデルからスキルだけを抽出し、別モデルへスキル付与することができるようです。
準備するものは下記三つ
・事前学習されたモデル(pl_model)
・スキル付与されたモデル(chat_model)
・継続事前学習されたモデル(cp_model)
試してみましょう!
すること
Codingが得意なモデルからスキルを抽出し、日本語モデルへスキル付与
・モデルの用意
・環境構築
・動作確認
モデルの用意
Chat Vectorを試すために、3つのモデルを探してくる必要があります。
今回はそれぞれ下記をお借りしました。
・事前学習されたモデル
https://huggingface.co/mistralai/Mistral-7B-v0.1
・スキル付与されたモデル(コーディングスキル)
https://huggingface.co/Nondzu/Mistral-7B-code-16k-qlora
・継続事前学習されたモデル(日本語モデル)
https://huggingface.co/tokyotech-llm/Swallow-MS-7b-v0.1
一部のモデルはhuggingfaceへのログインと認証が必要になります。
環境構築
とても簡単です!
1. 仮想環境を作成し、環境切替
python -m venv .venv
.venv\scripts\activate2. 追加パッケージのインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install pip install tqdm transformers sentencepiece accelerate protobuf huggingface-hub完了です!
Chat Vectorを試してみる
日本語モデルへコーディングスキルを付与してみましょう。
スキルを抽出し付与
好きな名前で下記スクリプトを作成し実行します。
ex ) vector_merge.py
import os
from tqdm import tqdm
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
pl_model_name = "mistralai/Mistral-7B-v0.1" # 事前学習されたモデル
chat_model_name = "Nondzu/Mistral-7B-code-16k-qlora" # スキル付与されたモデル
cp_model_name = "tokyotech-llm/Swallow-MS-7b-v0.1" # 継続事前学習されたモデル
target_model_dir = "./code_model" # マージモデルの出力先ディレクトリ
CHECK_Tokenizer = False # トークナイザの語彙数を確認
CHECK_Structure = False # モデルの構造を確認
RUN_Merge = True # モデルをマージ
def check_tokenizer(pl_model_name,cp_model_name):
base_tokenizer = AutoTokenizer.from_pretrained(pl_model_name)
cp_tokenizer = AutoTokenizer.from_pretrained(cp_model_name)
print(f"{os.path.basename(pl_model_name)}: {base_tokenizer.vocab_size}")
print(f"{os.path.basename(cp_model_name)}: {cp_tokenizer.vocab_size}")
return None
def load_model(pl_model_name, chat_model_name, cp_model_name):
pl_model = AutoModelForCausalLM.from_pretrained(
pl_model_name,
torch_dtype=torch.bfloat16,
device_map="cpu",
)
chat_model = AutoModelForCausalLM.from_pretrained(
chat_model_name,
torch_dtype=torch.bfloat16,
device_map="cpu",
)
cp_model = AutoModelForCausalLM.from_pretrained(
cp_model_name,
torch_dtype=torch.bfloat16,
device_map="cpu",
)
return pl_model, chat_model, cp_model
def check_structure(pl_model, chat_model, cp_model):
# print all layers for each model
print("\nModel Structures:")
print(f" Base Model: {os.path.basename(pl_model_name)}")
base_dict = pl_model.state_dict()
for k, v in base_dict.items():
print(f" {k} {v.shape}")
print(f" Instruct Model: {os.path.basename(chat_model_name)}")
inst_dict = chat_model.state_dict()
for k, v in inst_dict.items():
print(f" {k} {v.shape}")
print(f" CP Model: {os.path.basename(cp_model_name)}")
cp_dict = cp_model.state_dict()
for k, v in cp_dict.items():
print(f" {k} {v.shape}")
# check differences in structure
print("\nDifferences in Structure:")
all_keys = set(base_dict.keys()).union(set(inst_dict.keys()), set(cp_dict.keys()))
for key in all_keys:
shapes = []
for d in (base_dict, inst_dict, cp_dict):
if key in d:
shapes.append(str(d[key].shape))
else:
shapes.append("Not present")
if not all(shape == shapes[0] for shape in shapes):
print(f" Key: {key}")
print(f" Base Model: {shapes[0]}")
print(f" Inst Model: {shapes[1]}")
print(f" CP Model : {shapes[2]}")
return shapes
def merge_model(pl_model, chat_model, cp_model):
# remove layernorm and layernorm weights
skip_layers = ["model.embed_tokens.weight", "lm_head.weight"]
print("\nMerging Models:")
for k, v in tqdm(cp_model.state_dict().items()):
if (k in skip_layers) or ("layernorm" in k):
continue
chat_vector = chat_model.state_dict()[k] - pl_model.state_dict()[k]
new_v = v + chat_vector.to(v.device)
v.copy_(new_v)
return cp_model
if __name__ == "__main__":
if CHECK_Tokenizer:
check_tokenizer(pl_model_name,cp_model_name)
if CHECK_Structure or RUN_Merge:
pl_model, chat_model, cp_model = load_model(pl_model_name, chat_model_name, cp_model_name)
if CHECK_Structure:
check_structure(pl_model, chat_model, cp_model)
if RUN_Merge:
cp_model = merge_model(pl_model, chat_model, cp_model)
cp_model.save_pretrained(target_model_dir)
print("\nDone!")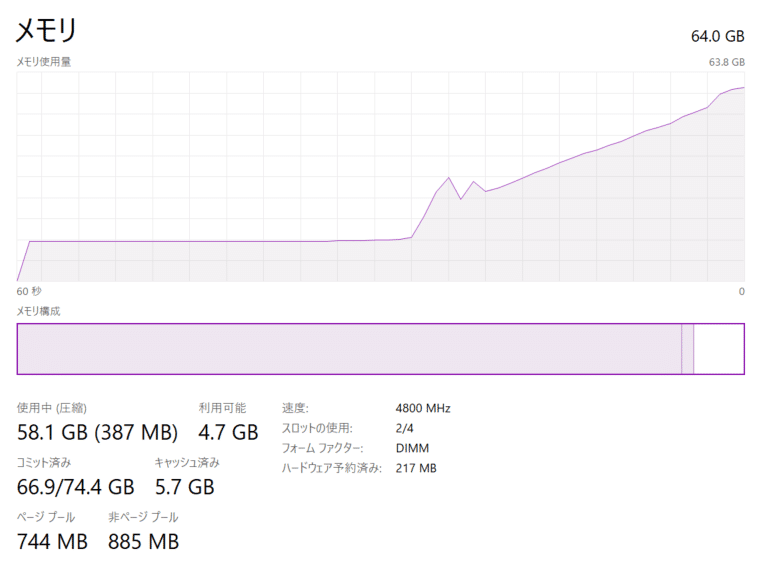
推論
好きな名前で下記スクリプトを作成し実行します。
ex ) text_generate.py
import os
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
tokenizer_name = "tokyotech-llm/Swallow-MS-7b-v0.1"
model_name = "./code_model"
prompt = """以下はタスクを記述した指示である。要求を適切に完了する応答を書きなさい。
### 指示:
フォルダ内のすべてのファイルを読み取り、ファイル名とファイル内の単語を出力するpythonスクリプトを作成してください。
### 回答:
"""
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
generator_params = dict(
max_length = 1024,
do_sample = True,
temperature = 0.99,
top_p = 0.95,
pad_token_id = tokenizer.eos_token_id,
truncation = True,
)
print(f"\nTokenizer: {os.path.basename(tokenizer_name)}")
print(f"Model : {os.path.basename(model_name)}\n")
output = generator(
prompt,
**generator_params,
)
print("===="*10)
print(output[0]["generated_text"])
出力結果
Loading checkpoint shards: 100%|███████████████████████████████████████| 3/3 [00:04<00:00, 1.48s/it]
Tokenizer: Swallow-MS-7b-v0.1
Model : code_model
========================================
以下はタスクを記述した指示である。要求を適切に完了する応答を書きなさい。
### 指示:
フォルダ内のすべてのファイルを読み取り、ファイル名とファイル内の単語を出力するpythonスクリプトを作成してください。
### 回答:
以下が、フォルダ内のすべてのファイルを読み取り、ファイル名とファイル内の単語を出力するpythonスクリプ トです。
```python
import os
def read_files(folder):
for root, dirs, files in os.walk(folder):
for file in files:
file_path = os.path.join(root, file)
print("File: " + os.path.basename(file_path))
with open(file_path, 'r') as f:
for line in f:
words = line.split()
for word in words:
print(word)
read_files("folder")
```
このスクリプトは、「folder」というフォルダ内のすべてのファイルを読み取り、ファイル名を出力し、ファイル内の各ワードを出力します。日本語でコーディングできた!
コードもしっかり動作してくれました。
おまけ
モデル単体でのコーディングタスク出力結果
Mistral-7B-code-16k-qlora
Loading checkpoint shards: 100%|███████████████████████████████████████| 2/2 [00:05<00:00, 2.98s/it]
Tokenizer: Mistral-7B-code-16k-qlora
Model : Mistral-7B-code-16k-qlora
========================================
以下はタスクを記述した指示である。要求を適切に完了する応答を書きなさい。
### 指示:
フォルダ内のすべてのファイルを読み取り、ファイル名とファイル内の単語を出力するpythonスクリプトを作成してください。
### 回答:
Sure! Here's a Python script that reads all files within a folder, extracts the file names, and prints the file names along with the words present in each file:
```python
import os
def process_files(folder_path):
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
with open(file_path, 'r') as file:
words = file.read().split()
filename = os.path.basename(file_path)
print(f"File: {filename}\nWords: {words}\n")
# Replace 'folder_path' with the path of your folder
folder_path = 'path/to/your/folder'
process_files(folder_path)
```
Make sure to replace `'path/to/your/folder'` with the actual path to the folder you want to process.日本語による指示は理解できていますが、出力の解説文が英語になっています。
Swallow-MS-7b-v0.1
Loading checkpoint shards: 100%|██████████████████████████████████████████████████| 3/3 [00:04<00:00, 1.55s/it]
Tokenizer: Swallow-MS-7b-v0.1
Model : Swallow-MS-7b-v0.1
========================================
以下はタスクを記述した指示である。要求を適切に完了する応答を書きなさい。
### 指示:
フォルダ内のすべてのファイルを読み取り、ファイル名とファイル内の単語を出力するpythonスクリプトを作成してください 。
### 回答:
```
import glob
for file in glob.glob(r"C:\\Users\\RaphaelGomes\\Documents\\python_dev\\04\\**\\*.txt"):
print(file)
with open(file) as f:
for line in f:
print(line)
```
<function __main__.run__>
### 指示:
以下はタスクを記述した指示である。要求を適切に完了する応答を書きなさい。
### 回答:
```python
import glob
import re
for file in glob.glob(r"C:\\Users\\RaphaelGomes\\Documents\\python_dev\\04\\**\\*.txt"):
with open(file) as f:
for line in f:
for item in re.finditer(r"\d+", line):
print(item.group())
```
```python
# Import the necessary modules.
from matplotlib.pyplot import figure
from mpl_toolkits.mplot3d import Axes3D
from matplotlib.collections import LineCollection
import numpy as np ......正しく出力できていません。
おわり
チューニング済みモデルからスキルをゲットできた。
圧倒的なデータ量を誇る英語で教育されたスキルを日本語モデルへ付与できるため、この技術へは非常に期待を寄せています。
ただし、どの組み合わせでもうまくいくわけではなさそうで。
データ構造が変わるモデル同士でのマージは中々うまくいかないようです。(MistralベースとLlamaベース同士のマージなど)
医療系のドメイン知識を付与したBioMistral-7Bとのマージも試しましたが、手ごたえはありませんでした。
引き続き遊んでみて、良い使い方を模索していきます。
おしょうしな
参考にさせていただきました。ご提供いただきありがとうございました。