
二値分類の過学習対策 AIを使って日経平均株価の予測に挑戦 学習データマシマシ編 Part 2

日経平均株価が上がるか下がるかを予測する二値分類を行うAIモデルの作成を再開
しばしの間、AIモデル用の学習データおよび評価データを作成するPythonプログラムのコーディングを行っていました。
そのPythonプログラムもとりあえず完成しましたので、日経平均株価が上がるか下がるかを予測する二値分類を行うAIモデルの作成を再開します。
2層Affine構造のAIモデルを使用して学習および評価を実施
様々な学習データおよび評価データを簡単に用意できるPythonプログラムを作ったので、アレコレ試してみたいと思います。
アレコレ試す対象のAIモデルは、下記の2層Affine構造のAIモデルとします。
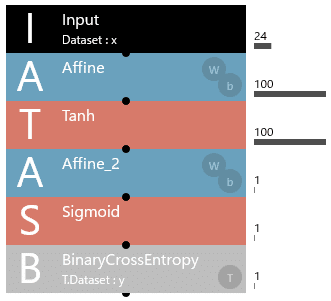
先ずは、学習データおよび評価データを作成するPythonプログラムを実行します。
作成したPythonプログラムを保存したファイル名をfilename.pyとした場合、最も単純な実行方法は下記の通りです。
> python filename.py
Start day: 1986-01-01
End day: 2024-01-31
[*********************100%%**********************] 1 of 1 completed
Training data element: SMA, BB, MACD, ICHIMOKU, RSI, STOCH
Number of rows for validation data: 250
Training data period: 1986-04-24 00:00:00 - 2022-12-16 00:00:00
Validation data period: 2022-12-19 00:00:00 - 2023-12-21 00:00:00
Training data csv file: training.csv
Validation data csv file: validation.csv
Done.上記の実行により、ローソク足データ、SMA, ボリンジャーバンド、MACD, 一目均衡表、RSIおよびストキャスティクスを含み、かつ、標準化された学習データおよび評価データが作成されました。
学習データおよび評価データの作成に使用するローソク足データの期間は1986年1月1日以降~2024年1月31日以前までです。
実際に、学習データに含まれる期間は1986年4月24日~2022年12月16日まで、評価データに含まれる期間は2022年12月19日~2023年12月21日までとなっています。
SMA(75日)や一目均衡表(遅行スパン)の影響で、有効なデータが削られてしまうのは避けられません。
学習データが保存されたファイル名はtraining.csv, 評価データが保存されたファイル名はvalidation.csvです。
この2つのcsvファイルを使って、2層Affine構造のAIモデルに対する学習および評価を実行するのですが、その前に一つだけ条件を明確化しておきます。
今回は、Neural Network Consoleにおける学習データのシャッフル機能を無効化してAIモデルの学習および評価を行います。
その理由は、これまでの結果から、その方が若干良い結果が得られると期待できそうだからです。
先ずは、学習曲線を以下に示します。

学習曲線は、これまでの結果とあまり差はなく、相変わらずValidation Errorが右肩上がり状態の過学習が進んでいることが確認できます。
また、Validation Errorの最高値が0.900を若干超えており、少し高めの印象です。
続いて、混同行列を以下に示します。

Accuracyが60%ですが、過去の最高値が62%程度だったので、悪くはないと思います。
今回は、かなり説明変数(学習データの要素)を増やしたので、結果が改善することを期待していたのですが、その点は残念です。
標準化を行わないとどうなるか再確認
単なる思い付きですが、標準化を行わないとどうなるのか、再度確認することにしました。
> python filename.py --nostd
Start day: 1986-01-01
End day: 2024-01-31
[*********************100%%**********************] 1 of 1 completed
Training data element: SMA, BB, MACD, ICHIMOKU, RSI, STOCH
No standardization!!
Number of rows for validation data: 250
Training data period: 1986-04-24 00:00:00 - 2022-12-16 00:00:00
Validation data period: 2022-12-19 00:00:00 - 2023-12-21 00:00:00
Training data csv file: training.csv
Validation data csv file: validation.csv
Done.学習データおよび評価データの標準化を行わない場合は、Pythonプログラムの実行時に--nostdオプションを指定すれば良いです。
実行結果には、「No standardization!!」と出力されます。
以下に、標準化を行わない場合の学習曲線を以下に示します。

学習データおよび評価データの標準化を行わない場合、COST, Training ErrorおよびValidation Errorは水平となり、全く学習が進まないことが確認できました。
続いて、標準化を行わない場合の混同行列を以下に示します。

学習が進まないので、y'=0(翌営業日の日経平均株価が下がると予測)の列がゼロとなっています。
つまり、AIモデルが常にy'=1(翌営業日の日経平均株価が上がると予測)を出力してしまっている状況です。
BatchNormalization層による標準化を行った場合の結果を確認
Neural Network Consoleが用意したBatchNormalization層を使って標準化した場合にどうなるかを確認してみました。
下記に、Input層の直下にBatchNormalization層を追加した構造のAIモデルを示します。
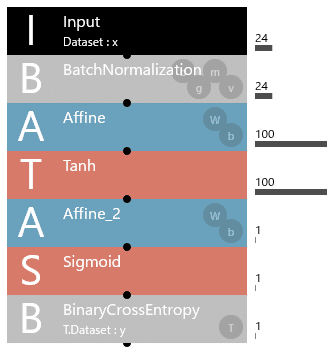
そして、下記が標準化を行わない学習データを使用した場合の学習曲線となります。

COSTは徐々に低下していますが、Training ErrorとValidation Errorはほぼ水平か、あるいは、若干上昇しているようにも見えます。
続いて、混同行列を確認します。

Accuracyは52%に低下してしまいましたが、AIモデルがy'=0(翌営業日の日経平均株価が下がると予測)を出力するようになったのは改善点です。
一方で、Pythonプログラムによる標準化を行った場合と比べるとAccuracyが低いため、標準化はPythonプログラムで行う方が良いことが確認できました。
4層Affine構造のAIモデルを使用して学習および評価を実施
最初に作成した標準化を行った場合の学習データおよび評価データを4層Affine構造のAIモデルに適用し、結果を確認します。
以下に、4層Affine構造のAIモデルを示します。
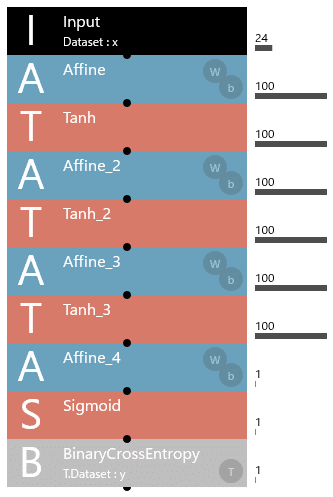
続いて、4層Affine構造のAIモデルにおける学習曲線を以下に示します。

4層Affine構造のAIモデルにおける学習曲線は、COSTおよびTraining Errorが低下する一方で、Validation Errorは大幅に上昇しており、過学習がより進む方向にあることが確認できました。
以下に、4層Affine構造のAIモデルにおける混同行列を示します。

Accuracyが61.2%となり、2層Affine構造のAIモデルと比べて弱冠精度が向上しました。
LSTM構造のAIモデルを使用して学習および評価を実施
続いて、LSTM構造のAIモデルに学習データおよび評価データを適用した場合にどうなるかを確認します。
以下に、LSTM構造のAIモデルを示します。

ちなみに、Neural Network ConsoleのRNN(リカレントニューラルネットワーク)向けに学習データおよび評価データを作り直す必要があります。
> python filename.py --rnn 2
Start day: 1986-01-01
End day: 2024-01-31
[*********************100%%**********************] 1 of 1 completed
Training data element: SMA, BB, MACD, ICHIMOKU, RSI, STOCH
RNN params: 2
Number of rows for validation data: 250
Training data period: 1986-04-24 00:00:00 - 2022-12-15 00:00:00
Validation data period: 2022-12-16 00:00:00 - 2023-12-20 00:00:00
Training data csv file: training.csv
Validation data csv file: validation.csv
Done.今回は、--rnnオプションで2を指定しています。
また、AIモデルは--rnnオプションに合わせて、下記のパラメータを設定しています。
AIモデルのパラメータ設定
Reshape層: OutShapeパラメータ 2, 24
OutShapeパラメータの2が--rnnオプションで指定した数字と同じになる必要があります。
また、OutShapeパラメータの24はInput層のSizeパラメータで指定した48を2で割った数字を指定します。
早速、学習曲線を確認します。

Validation Errorが勢い良く上昇していることが確認できます。
次に、混同行列を確認します。

Accuracyが50.4%と山勘レベルまで低下してしまいました。
結果の考察
今回の結果について、次のようなことが言えると考えます。
結果の考察
AIモデルの構造について
単純な構造のAIモデルの方が日経平均株価の二値分類には適していそう
2層Affine構造と4層Affine構造では、弱冠、4層Affine構造の方が予測精度(Accuracy)が高くなる
LSTM構造のAIモデルは過学習となりやすい
過学習について
学習データにローソク足データ、SMA, ボリンジャーバンド、MACD, 一目均衡表, RSI, ストキャスティクスのテクニカル分析指標を与えても過学習の問題を解決できない
とりあえず、日経平均株価の二値分類を行う場合は、単純な構造のAIモデルを使用するのが良さそうだということが確認できました。
しかし、現状の予測精度(Accuracy)は60%強のレベルです。
山勘レベルよりは高い精度ですが、正直、もう少しという想いがあります。
どうすれば過学習を抑えられるのか、もう少し考えてみたいと思います。
別の問題発生、一目均衡表の遅行スパンについて
ここまでAIモデルの学習および評価を行ってきましたが、さらにもう一つ、別の問題に気がついてしまいました。
それは、一目均衡表の遅行スパンに関するものです。
一目均衡表の遅行スパンとは、当日の終値を26日遅行させた、つまり、26日だけ日足チャートの左方向にずらしたものです。
言い換えれば、未来の終値を26日前に表示している状態です。
このため、本日から25日前までの日足チャートには、遅行スパンを表示することができません。
私が作成したPythonプログラムでは、遅行スパンのデータが存在しない日は削除しています。
この場合、仮に過学習問題が解決し、予測精度の高いAIモデルが出来上がったとしても、未来の日経平均株価を予測できません。
なぜなら、遅行スパンの影響で本日を含む25日前までの評価データを用意できないからです。
これは大問題です。
この点についても検討が必要です。
この記事が気に入ったらサポートをしてみませんか?