
NTech Predictが挑戦したKaggleの「M5 Forecasting – Accuracy」②

■はじめに
記事は3回に分けての報告になります。
1回目 Kaggleのコンペ「M5 Forecasting – Accuracy」について
2回目 NTech Predictでどうやって結果を出していったか?の経過
3回目 NTech Predictでやったらどうなったのか?「最終結果」までの経過
今回は2回目になります。
NTech Predictでどうやって結果を出していったか?の経過
■NTech Predict仕様の問題
コンペ「M5 Forecasting – Accuracy」では5つのcsvファイルが提供されます。
※コンペ「M5 Forecasting – Accuracy」については前回の記事を参照して下さい。
売上:各店舗・各商品における過去5年間の日別販売数量
カレンダー:宗教行事やスポーツ等のイベント開催日とSNAP(連邦栄養補助プログラム)が利用できる日
価格:店舗ごと・商品ごとの日単位の販売価格
提供されたcsvファイル
calendar.csv -各店舗・各商品における過去5年間の日別販売数量.
sell_prices.csv - 店舗ごと・商品ごとの日単位の販売価格
sales_train_validation.csv - 製品および店舗ごとの過去の日次販売単位データ
sales_train_evaluation.csv - 製品および店舗ごとの過去の日次販売単位データ
sample_submission.csv – 提出用のテンプレート
前回の記事でも書いたようにコンペ自体は締め切りとなっているためsales_train_validation.csvは使わないことにしました。つまり既に答(sales_train_evaluation.csv)が開示されてしまっているためです。したがって使うデータはcalendar.csv, sell_prices.csv, sales_train_evaluation.csvの3つでsample_submission.csvを出力して提出するという流れになります。
ここで1つの課題が出てきます。NTech Predictの仕様上の問題でバラバラに提供されるデータを時系列データとしてマージする作業はツール内ではできません。単純なマージであれば機能として提供できるのですがデータの内容は千差万別で単純なロジック一発で都合よく整形する機能は難しいため少なくともデータ整形は手作業で行っておく必要があります。
それとNTech Predictでは縦形式のテーブルデータ(時間方向が行)を想定しています。提供されるデータは横形式のテーブルデータ(時間方向が列)でした。従ってこの整形も必要です。

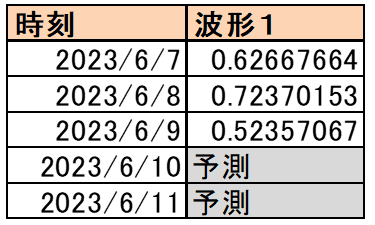
無事、データマージと縦形式に整形したところで第2の課題にぶつかりました。
■NTech Predictではできないんじゃない?
大問題です。というか最初からこの課題は分かっていました。NTech Predictはver2.1から単変量時系列予測に加えて多変量にも正式に対応する計画です。しかし、このコンペは多変量とは言っても超多変量という状態です。
そこで30490系列の超多変量を30490個の単変量にして30490個のモデルをNTech Predictで生成してしまえという単純発想です。
この考えは良くなかったことが後でわかりますが少なくともこの時点ではNTech Predictが持つ自動特徴量設定という機能が旨くやってくれるだろうという甘い読みがありました。
投入csvデータの合計サイズは12.2ギガバイトです。1ファイルが約420キロバイトなので大したサイズではありませんが30490個を処理するということになります。
※NTech Predictは全てGUI操作なので一個一個操作していくのは流石に辛いのでNTech PredictのAPIでバッチ実行させました。
結果はこうなりました。

このグラフはスコアとそのスコアになった挑戦者の数をヒストグラムで表した図になります。
データを NTech Predict 放り込んで自動でやった結果は世界ランクTop50%でした。
冒頭でKaggleから支給されるデータについて話しましたが何もせずに、つまり予測モデルを作って予測するということを一切せずにsample_submission.csv – 提出用のテンプレートをそのまま提出してもScore: 5.39065になります。
想像の域を超えませんがスコアが5.39~203くらいの挑戦者170名程は何らかの形で成果を提出した結果ではないかと想像します。スコアの分布をみると良い悪いに分離しつつもその中間スコア出している参加者が居ることが分かります。また多くの挑戦者はスコアが5以上で約2450人以上もいることが分かります。つまり挑戦者の約半数はTop50%からは程遠いランクになってしまっているという点です。
これは逆に言えば技量のあるデータサイエンスチームで挑戦しても良いスコアを出すことが困難な課題であることが予測できます。実際このコンペにはチーム(複数人または複数のチーム)で挑戦していることが挑戦者リストからわかります。

一方でスコア203以上を叩き出した強者も居ます。グラフで赤い部分(末端)ではスコア5300413.62339という値を叩き出しています。

念のためですがこのコンペではスコアが小さい方ほど順位が上になります。
以前、聞いたことがある話ではあえて超絶最下位を取りに行くという裏コンペをやっているデータサイエンティストも居るらしいです。先ほども述べましたが何もしなくてもスコアは5.4程度です。
どうやれば5300413.62339という値を出せるのか逆に凄さを感じます。(やったことが無いのでこれも想像です)。
Kaggleの採点がちょっと面白いのは提出前に自前で採点ができないところです。つまりKaggleに提出することでKaggle独自の評価基準で採点されるため提出してみないとスコアが分からない点です。
結果としてどこを間違えたのかもわからないので何度も提出して誤りを訂正するといったインチが不可能な点です。これは前回の記事で書いたようにNTech Predictの客観的な評価としては最適な条件です。
■結局、NTech Predictはどうなの?
自動モデリングなのでこれはこれで良い結果なのか?予測結果の一部を見てみると
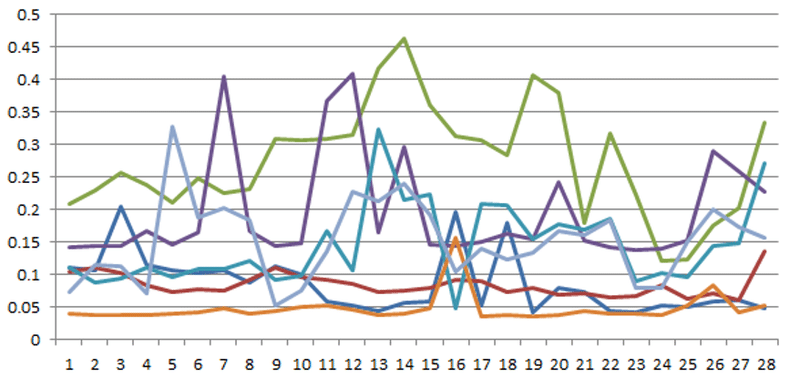
こんな感じです。直感的にこの予測結果はベストではないと分かります。少なくともデータを放り込んで後は放置しただけでも結果は出ました。
NTech Predict内では自動特徴量エンジニアリングで自動モデリングしてくれています。整形を除けば完全に自動化されているのは良いことだと思いますがNTech Predict開発メンバーの誰も満足する結果では無いのは明らかです。ちなみに計算時間は概ね3日掛かっています。
ポジティブな見方としてはデータ整形後のデータであったとしても営業とかがpythonとかRでこの結果を出せるか?まず出せないでしょう。
今回、この結果は実は想定外でした。実際はTop30%には軽く行くだろうととう想定でした。ただその想定も運が良ければという読みはありました。なぜかと言えばNTech Predictでは自動特徴量設定という機能でデータサイエンティストが時間を掛けて何度も試すということを自動でやってくれるメリットがありますが多変量ではその機能が多変量ならではの課題から一部制限を受けてしまうからです。
つまり、NTech Predictでは自動特徴量設定という機能に強く頼ったためでした。
そもそも多変量のデータを分解して単変量として扱った点がやはり不味かったと思います。多変量データの良い所はある目的変数に注目したときに別の目的変数が説明変数になりえる点(重みの調整役)です。例えば一つの波形で予測モデルを作るのは難しいですが複数ある場合は他の波形が説明変数の役割を担う可能性があります。
この辺りは説明が難しいので端折った説明になってしまいましたが早話、多変量データの予測モデルは多変量予測モデルを使うべきということです。当然といえば当然ですが一方で多変量データのどの目的変数も完全に独立したものなら単変量に分けて予測モデルを作ることはあながち間違いではないかもしれません。
次回は多変量データ予測モデルとしてNTech Predictによるコンペ参戦の続きを報告したいと思います。

この記事が気に入ったらサポートをしてみませんか?