
NTech Predictが挑戦したKaggleの「M5 Forecasting – Accuracy」①

■はじめに
記事は3回に分けての報告になります。
1回目 Kaggleの「M5 Forecasting – Accuracy」について
2回目 NTech Predictでどうやって結果を出していったか?の経過
3回目 NTech Predictでやったらどうなったのか?「最終結果」までの経過
今回は1回目になります。
Kaggleの「M5 Forecasting – Accuracy」について
■動機
今回はM5 Forecasting – Accuracyとはどんなコンペティション(以下コンペ)なのかを紹介したいと思いますが、その前になぜNTech Predictでやってみようと思ったのかについて簡単に話したいと思います。
弊社ではNTechシリーズ製品を開発販売させていただいています。その中でも肝いりの製品がNTech Predictという製品で
時系列予測
因果探索
予知保全向け異常予測
の3つの機能が利用可能なツールになっています。製品の開発は弊社の1部門でもある3Dエンジニアリングソリューション部という部門が行っています。この部門、もともとは3D CAD/CAM/CAEの研究開発を軸とする部門でしたが2012年を境にデータサイエンス領域もやりはじめた社内でもチャレンジングな部門なのです。と言いたいのですが実際は2010年頃からCAD/CAM/CAE製品が海外から流入してきており国内ではインフラ化しつつありました。実際CAD/CAM/CAEの開発は激減しており保守やカスタマイズといった仕事が多くなってきています。
そういう意味では2012年にデータサイエンス領域にも拡大したのは正解だったと思って居ます。
幸いにもCAD/CAM/CAEの研究開発メンバーが中枢に居たため理数系に強い部門だったことも動機でもありました。
NTech Predictをリリースしたのは2022年8月ですがありがたいことに多くのユーザー様に試用、利用して頂いています。多くは予知保全向け異常予測機能、因果探索機能をメインに活用して頂いていて時系列予測については残念ながら一部のユーザー様にしか利用していただいておりません。
そこで開発部門内でもっと目を引くPRをすべきじゃないのか?という声もあり最終的にはKaggleのM5 Forecasting – Accuracyというコンペに挑戦してみたら?ということになりました。
目論見はこうです。M5 Forecasting – Accuracyは
データが大規模
超多変量の時系列予測になるため難易度が高い。
データサイエンティストにとっても極めて難しい課題。
これをNTech Predictにデータ投入してポチポチとボタンを押して結果がでるのであれば「凄い!」ってなるよね。しかもデータサイエンティストやそれを目指す人にとってM5 Forecasting – Accuracyを知らない人は居ないテーマでもあります。
つまり、データサイエンティストが居なくても相応の結果が出せるというのは魅力的な性能だと思うよね?
というのが目論見です。
ここで多変量、単変量という単語ですが意外と曖昧な扱いになっている場合があるので整理しておきます。

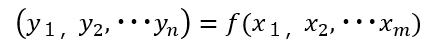
時系列モデルでは過去の情報も参照するため

と複雑になります。多くの場合は周期(季節)やトレンド、特異日などのイベントの情報が説明変数になるためさらに複雑なモデルになります。
それと若干反則にはなるのですが、このコンペは既に締め切りとなっており参加しても非公式な成績となります。ですが結果の評価自体は現在もKaggleで自動的に行われるため評価結果自体は客観的な評価で1企業内の評価、ブラックボックス評価でPRするのとは事情が異なる点には注目して欲しいと思って居ます。しかし結果自体は客観的な評価ですが「こういう結果だった」ということを外から見ることができないためその点においてはブラックボックス評価にはなってしまいます。
■Kaggleコンペ:M5 Forecasting – Accuracyとはなにか?
やや前置きが長くなりましたがM5 Forecasting – Accuracyをご存じない方も多くないと思いますのでデータサイエンティストやそれを目指す人以外の方にもどんなコンペなのかを紹介してみたいと思います。
タスクとしてはWalmartの売上個数の予測です。実際の販売データに与える複雑な影響などがあり、非常に困難で難しいコンペになっています。主催は予測研究者の Spyros Makridakis が率いるチームで初回はM-Competition と名付けられ、1982 年に 1001 のデータ ポイントのみで開催されました。その後はデータが膨大となり「M5 Forecasting - Accuracy」は5回目のコンペティションで2020年3月から6月に開催され約101ヵ国5558のチームが挑戦しました。
米国 (17%)、日本 (17%)、インド (10%)、中国 (10%)、ロシア (6%) からであり、残りの 40% はその他の 96ヵ国からの参加者でした[1]。
既にコンペは終了していて最終評価で結果を提出できたチームは5582チームでした。
コンペは2011年〜2016年のWalmartの売上個数データを使って販売数量を予測するタスクになります。これは10店舗における3049種類の商品ごとにこの先4週間の日々の販売数量を予測するという30490系列の超多変量の時系列予測になります。
提供されるデータは米国3州(カリフォルニア州、テキサス州、ウィスコンシン州)にあるウォルマートの合計10店舗、商材は食材(FOODS)、おもちゃ(HOBBIES)、日用品(HOUSEHOLD)の3つのカテゴリで3049種類の商品の販売数量等のデータでデータの最終日以降の商材別の販売数量を4週間(28日間)の予測を行うという形です。
コンペの評価は2段階でpublic(Validation Phase)とprivate(Evaluation Phase)に分けたコンペでコンペ終了1ヶ月前にpublicの正解が公開されてさらに4週間(28日間)を予測するprivate(Evaluation Phase)という形式です。
提供されるデータは以下の3つの情報が書き込まれたCSVファイルです。
売上:各店舗・各商品における過去5年間の日別販売数量
カレンダー:宗教行事やスポーツ等のイベント開催日とSNAP(連邦栄養補助プログラム)が利用できる日
価格:店舗ごと・商品ごとの日単位の販売価格
※SNAP:最大の連邦栄養補助プログラムでElectronic Benefits Transferカードを介して、適格な低所得の個人や家族にメリットを提供します。
public (Validation Phase)
2011年1月29日から2016年4月24日までの約5年分の売上データから後の4週間(2016年4月25日から5月22日)の売上(販売数量)を予測します。


private (Evaluation Phase)
2020年6月1日からEvaluation Phaseとなり、2016年4月25日から5月22日の販売数量が公開され、後の4週間(2016年5月23日から6月19日)の販売数量を予測します。これが最終的な順位となります。

■問題の難しさ
30490系列の超多変量の時系列予測になるという点もありますがそれ以外には例えば各商品は多くの日で全く売れていない日があったり、売れている商品(概ね10個ぐらい)でも、長期間(数カ月)全く売れていない期間が存在したりしています。

つまり、ゼロ値が相当あるようなデータになっている点です。
次回は「2回目 NTech Predictでどうやって結果を出していったか?の経過」の予定です。

この記事が気に入ったらサポートをしてみませんか?