正規表現は今日から使おう(中級編)

ここまでのあらすじ
「正規表現は今日から使おう(初級編)」を読む
↓
謎制作が効率的になる
↓
高度な謎が作れるようになる
↓
身体はさらなる正規表現を求める
↓
「正規表現は今日から使おう(中級編)」が出る
というわけで、中級編のはじまりはじまり。
なお、もしも以下の①と②の内容で分からないものがあれば「正規表現は今日から使おう(初級編)」を読み復習してから臨むことを推奨する。
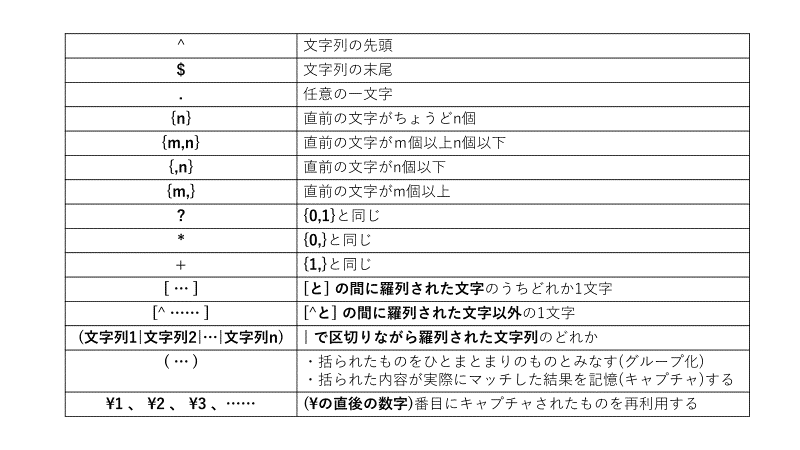
①「初級編」で学んだ正規表現の記法について
以下の画像にまとめた。これらの内容は一通り分かっておきたい。
②「謎解き単語検索β」の使い方について
謎解き単語検索βという、一般公開されているとても便利なツールを使って単語検索をすることを推奨している。以下を理解していれば記事の内容を実践する上で支障は無い。
「正規表現」タブから、正規表現を用いた検索ができること。
辞書ファイルは「豚辞書」「一般語」「英語」があり、デフォルトで「豚辞書」が選ばれていること。(この記事では、特に指定しない限り「豚辞書」のままで良い)
「豚辞書」「一般語」は日本語の単語がひらがなで収録されているため、検索条件はひらがなで入れる必要があること。
「豚辞書」は文字の大小の区別が無いが、「一般語」は大小の区別があること。
前置き
「初級編」でも述べたように、これは「謎制作という目的のために正規表現を活用する」というマニアックな記事だ。普通のITエンジニア向けに書いていない。それを期待した人はQiitaを漁ろう。
「初級編」を読んでいるか、上で挙げた①②を分かっていることを前提とする。暗記レベルで分かっている必要は無いが、「書いている内容がちんぷんかんぷん」な場合、この記事はかなり辛いだろう。自信が無い、という人は「初級編」を適宜読み返しつつこの記事を読むのもアリだ。
この章の内容はかなり難しい。「難しい」と思ったならば、あなたの理解力不足ではなく、ただ単に難しいのだ。どうかくじけないでほしい。
この章では「先読み」「置換」というとても重要なものに触れる。「先読み」は正規表現検索の可能性を飛躍的に広げてくれるし、「置換」を使いこなせることは人生をはるかに豊かにしてくれる。「頑張って時間をかけて理解する」の心持ちで、どうか頑張ってほしい。
なるべく正確な表現を心がけるが、伝わりやすさのために厳密には正しくない説明を織り交ぜる場合がある。許してほしい。
正規表現講座5(肯定先読みの話)
ここではまず「先読み」について学ぶ。
「先読み」には「肯定先読み」「否定先読み」の2種類があり、どちらも重要だ。
先読みの最大のメリットは「判定をする時に文字を読み進めない」ことであり、その副産物として「複数条件の重ねがけ」ができる。
……と、いきなり言われてもよく意味が分からないだろう。
今回は、正規表現がやっていることを何となく理解しながら、「先読み」が何をしているのか、実際にイメージしてもらうことを目指す。これまで何となく「先読み」を使えていた人も、これを機に本質を整理してみてほしい。
一旦、これまで学んだテクニックを使って、以下の2パターンの条件を満たす単語をそれぞれ検索することを考えよう。
(パターン1) 3文字の単語
(パターン2) 『ん』をちょうど1つ含む単語
これらを正規表現で表すには、
(パターン1) ^.{3}$ または ^…$
(パターン2) ^[^ん]*ん[^ん]*$
等と書けば良い。
さて、突然だが、これらの正規表現を与えられてチェック処理を行う機械の気持ちになってみよう。
以降、この機械を「正規表現エンジン」と呼ぶことにする。
正規表現エンジンは、正規表現にマッチするか判定したい対象文字列がある場合に、その対象文字列を読み進めながら判定を行う。次のスライドを見てイメージを持ってみよう。
何となく動きのイメージは持てた気がする。
「今の位置について判定をする(^や$)」または
「この先にある文字を読み進めつつ判定する」
のどちらかを繰り返しつつ、最終的に「判定前の正規表現」を無くすことができれば「マッチする」し、何をどうやっても無くせなければ「マッチしない」。
よし、ではこの正規表現エンジンの気持ちを考えながら、
「文字数が3文字の単語」「『ん』をちょうど1つ含む単語」
の両方の条件を同時に満たす単語を検索できるかを考えたい。
……のだが、困った事実に遭遇する。
「1.の条件をチェックし終えた状態」から追加で2.の条件をチェックしようとしても、既に「対象の文字列を読み終えてしまっている」のだ。
逆に「2.の条件をチェックし終えた状態」から追加で1.の条件をチェックしようとしても、既に「対象の文字列を読み終えてしまっている」のだ。
既に末尾位置にいる状態だと、「$ にマッチするかどうか」くらいしか判定できることがない。やれることが無い!
そう、「複数の条件を同時に判定したい」という願望は、「対象の文字列を読み進めながらチェックをする」という正規表現エンジンの挙動と非常に相性が悪いことが分かる。
これは困った……
まあ、実は今やりたいことだけなら「ん●●」「●ん●」「●●ん」の5パターンのどれかであることをチェックできればOKなのだから、
^(ん..|.ん.|..ん)$
のように「全部のあり得るパターンをOR条件でつなぐ」ことで検索は可能ではある。
今回の場合は3パターンなのでそんなに手間じゃないが、8文字で検索したければ8パターン書く必要があるし、今後もっと複雑な条件同士を組み合わせたくなることもあるだろう。
どうにかして、「対象の文字列を読み進めないようにしつつ、『今読んでいる位置より先』の情報を先読みして、条件に合致しているか判断したい」。
その方法がある。それが「先読み」というものだ。
【事実17】(?=~) と書いた時、「この直後に~が現れる位置」にマッチする。もし ^(?=.*~) という風に「先頭位置の直後」になるように書いて差し支えない状況であれば、その方が分かりやすく書けるため、そう書いてしまうことを推奨する。
「位置にマッチする」という文言は、過去にも目にしている。^ と $ で、それぞれ「先頭という位置」「末尾という位置」にマッチするものだった。それは正直分かりやすかった。今回は何をやるのかが分かりにくい。
分かりにくいのでまずは実例を見よう。今の記法を使って
文字数が3文字の単語
「ん」をちょうど1つ含む単語
をそれぞれ検索する場合、
^(?=.{3}$) または ^(?=…$)
^(?=[^ん]*ん[^ん]*$)
ということになる。なんじゃこれは。これが何をやっているのか、正規表現エンジンの気持ちになって確認してみる。
さて、正規表現エンジン目線で見ると、「先読み」を使った場合の挙動で、使わない時と比べて大きな違いが1つある。それは、条件をチェックし終えた時点で、まだ「文字列の先頭の位置」を読んでいるということだ。
これはつまり、他の条件のチェックを今から追加で実行できるということ。
何なら、先読みであれば何度でも繰り返し行える。嬉しい。
ならば2つの条件を適切に書き並べてあげれば1.と2.を同時に満たす単語を検索することができる。具体的には、
^(?=.{3}$)(?=[^ん]*ん[^ん]*$)
と書けば良い。
この時、「先頭の直後に …$ があるかをチェックして」「先頭の直後に [^ん]*ん[^ん]*$ があるかをチェックする」ということをやっている。
結果的に、2つの条件を両方ともチェックできる。
(1.→2.の順で書き並べたが、2.→1.の順で書く ^(?=[^ん]*ん[^ん]*$)(?=.{3}$) でも何ら問題は無い。チェックする順が違うだけだ)
先読み記法は、「文字を読み進めることなく、『それ以降の文字の情報を先読みする』」という性質を持つ。
その結果として、「複数条件の重ねがけ」を行うのに非常に適しているのである。
もう少し実例を見てみよう。
例えば、
(パターン1) 「あいうえお」のどれか1つを含む単語
(パターン2) 「かきくけこ」のどれか1つを含む単語
(パターン3) 「さしすせそ」のどれか1つを含む単語
(パターン4) 「3文字の単語」
を検索する場合を考えよう。
それぞれバラバラに検索するなら、
(パターン1) [あいうえお]
(パターン2) [かきくけこ]
(パターン3) [さしすせそ]
(パターン4) ^.{3}$
で良いはずだ。
しかし、これらをすべて同時に満たす単語を検索するのは、先読みを使わないと非常に面倒だ。何故ならば、
[あいうえお][かきくけこ][さしすせそ]
[あいうえお][さしすせそ][かきくけこ]
[かきくけこ][あいうえお][さしすせそ]
[かきくけこ][さしすせそ][あいうえお]
[さしすせそ][あいうえお][かきくけこ]
[さしすせそ][かきくけこ][あいうえお]
のように、登場する順番は6通りすべてを考慮する必要があり、これら全部を書き並べる必要があるからだ。
上記の6つを全部組み合わせて ^(1行目|2行目|3行目|4行目|5行目|6行目)$ と書けば条件は満たせる。
3文字の並べ替え(6通り)ならまだ頑張れそうだが、4文字なら24通り、5文字なら120通りになる。それを書くのは今後流石に辛そうだ。
というわけで、まずは上記の条件を先読みで書く方法を考える。
(パターン1) (?=.*[あいうえお]) または ^(?=.*[あいうえお])
(パターン2) (?=.*[かきくけこ]) または ^(?=.*[かきくけこ])
(パターン3) (?=.*[さしすせそ]) または ^(?=.*[さしすせそ])
(パターン4) ^(?=.{3}$)
となる。パターン1~3は括弧内に $ が書かないことに注意。例えばパターン1で $ を書くと、「末尾に [あいうえお] が登場する」場合に限定してしまう。どの位置でも良いのだから、$ は付けてはならない。
これらを組み合わせることで、
^(?=.*[あいうえお])(?=.*[かきくけこ])(?=.*[さしすせそ])(?=.{3}$)
とパターン1~4のすべての条件を重ねがけして検索することができる。
ちなみに、今これは文字を1度も読み進めていない(全部先読みだけで済ませた)書き方をしているが、1回は文字を読み進めることができるはずだ。つまり、大半は先読みで書かないといけないが、1つだけは先読みじゃない書き方にしても良い。
例えば、
^(?=.*[あいうえお])(?=.*[かきくけこ])(?=.*[さしすせそ]).{3}$
みたいな書き方が可能だ。
これは.{3} 部分を先読みではなくした例。
これは好みだし、正直どう書いても良い。
ただ、「どちらでも良い」と分かっておくことは嬉しい場合がある。
例えば、「同じ文字が3度出る単語」が欲しくて
^.*(.).*\1.*\1.*$
みたいな検索をかけた後のことを考えよう。
「思ったよりたくさん出たから、検索結果を6文字以下の単語に絞りたいなあ」と思ったら
^(?=.{,6}$).*(.).*\1.*\1.*$
とできるし、
「『ん』を含む単語に絞りたくなったなあ」と思ったら
^(?=.*ん).*(.).*\1.*\1.*$
とできる。
謎制作では試行錯誤しながら検索条件を足し引きしたいことは多く、こんな風に後付けで気軽に条件を追加削除できるのは非常に嬉しい。
そういえば、1つだけ大切な補足があった。上記の例を見た時、注意力のある人ならば
「あれれ、(?=.{,6})がキャプチャされてこれが\1になるから、(.)は\2になるんじゃないの?」という疑問を持ったかもしれない。鋭い。
だが、実はこれはそうならないので大丈夫だ。一旦今の時点では、以下の通り覚えてしまってほしい。
【事実18】() の冒頭に ? が来るような特殊な記法では、キャプチャの対象とならない
練習問題part5 (全4問)
なお、大切な注意事項が1つある。
先読みの条件重ねがけは万能ではなく、「複数の条件を同時に満たせるケース」で破綻する場合があることに気をつけてほしい。
特に、「~を含む」という条件の重ね掛けをする場合に影響を受けがちだ。
例えば、「わん」「つー」「すりー」から1文字ずつ拾ってできる3文字の単語を探したい場合を考える。「つりわ」「つわり」等が期待だ。
この時、これまでと同様であれば
^(?=.*[わん])(?=.*[つー])(?=.*[すりー])...$
等とすれば良いはずだが……
実際にやってみると「こーん」「わーど」等、明らかに正しくない単語が大量に出てくる。
これは、「ー」を含む単語が「『つー』のどれかを含む」と「『すりー』のどれかを含む」の両方を同時に満たしてしまうことに原因がある。
これはつまり、「『わん』のどちらかを含む」かつ「『-』を含む」場合、「あと一文字は何でも良い」ことになってしまっているのだ。
これを根本的に解決する正規表現でのうまい書き方は(おそらく)存在しない。細かい場合分けを全部書き下すくらいしか無く、面倒だ。
これが何とかなれば謎制作は大きく進歩するはずだと思い続けており、過去にわんどさんに相談したところ……


即日解決した。なんで?
この数日後に「文字拾いツール」という名前で、有償のツールとして公開されている。自分にとっては払って得られる対価がでかすぎるので、迷わず購入して頻繁に利用させてもらっている。
興味ある人は【わんど工房】語群から拾ってできる単語を調べたいを参照。
単語探しをよくする制作者であれば購入する価値は十分にある、非常におすすめのツールだ。
正規表現講座6(否定先読みの話)
先ほど出てきたのは「肯定先読み」だったが、逆にここで学ぶのは「否定先読み」となる。
【事実19】(?!~) と書いた時、「この直後に~が現れない位置」にマッチする。もし ^(?!.*~) という風に「先頭位置の直後」になるように書いて差し支えない状況であれば、そう書いてしまうことを非常に強く推奨する。
肯定先読みの逆の意味を示すのが否定先読みだ。
この否定先読みの記法を使って、
(パターン1) 「あいうえお」の内いずれも含まない単語
(パターン2) 「ー」を2個以上含まない単語(つまり、0~1個含む)
(パターン3) 「ぱん」という文字列を含まない単語
(パターン4) ローマ字で書く時に「ki」を含む(つまり、「ゃ」「ぃ」「ゅ」「ぇ」「ょ」の直前以外の場所にある「き」を含む)単語
を検索する場合を考えてみよう。
それぞれ
(パターン1) ^(?!.*[あいうえお])
(パターン2) ^(?!.*ー.*ー)
(パターン3) ^(?!.*ぱん)
(パターン4) き(?![ゃぃゅぇょ])
となる。※パターン4が役立つのは「一般語」辞書の場合なので注意
パターン1は ^[^あいうえお]*$ 、パターン2は ^[^ー]*ー?[^ー]*$ と書いても良いのだが、パターン3と4は否定先読みを使わないとおそらく正規表現では書けない。
なお、パターン1~パターン3では ^(?!.*~) という書き方をしたが、この ^ を省略してを (?!~) と書いてはいけないことに注意してほしい。
例えばパターン3を (?!.*ぱん) と書いてはならない。
逆に、パターン4に ^ をつけて ^き(?![ゃぃゅぇょ]) と書いてはならない。
このような、期待と違う結果になってしまうのだ。
「登場しないような場所が一箇所でもあればマッチする」というのは相性が悪い場合が多く、想定外のマッチが起こって事故りかねない。
事故らないために、^(?!.*~) という書き方にすることを非常に強く推奨する。せっかくなので、問題ない場合は肯定先読みも ^(?=.*~) と書くことに統一してしまおう。分かりやすいので。
否定先読みは肯定先読みの時と同じで、「条件の重ねがけ」が可能だということも見逃せないし、後付けでの条件追加も容易い。
肯定先読みと否定先読みをミックスすることだってできる。嬉しい。
練習問題part6(全5問)
肯定先読みと否定先読みを組み合わせてできるテクニックは非常に奥深く、その片鱗に触れてほしい。
この練習問題からあえて省いたものがいくつかあるので、それは「上級編」で紹介したい。
練習問題part6のQ36は「小さい文字を考慮した上で、母音がaの文字」が
([あかさたなはまやらわがざだばぱ](?![ぁぃぅぇぉゃゅょゎ])|.[ぁゃゎ])
と表現できるということを紹介している。
この事実をうまく組み合わせていくことで、ナゴマ氏によって書かれた以下の記事に紹介された「母音の並びが特徴的な単語」の検索に役立つことは容易に想像がつく。応用先は広い。
参考:孤独の音語・折り込み読み語・ファイブ音語(エグゾディア)・母音ペア完成語
他にも、実はルーク語(五十音表上をチェスのルークの動きで移動することで拾える単語)は、「否定先読み」の知識を使えば既に検索が可能である。
ただ、ルーク語の検索を工夫なく行うには非常に手間がかかるため、自分がやる時はExcelを用いて効率的に正規表現を生成するという手順をとっている。これについては上級編で詳しく説明することにする。
ここまでが前半。ここから後半。
良いテキストエディタ選びは人生を豊かにする
後半で「置換」に触れるための下準備のため、しばらく話題が変わる。
突然だが、PCで文章を打つ時に使うテキストエディタは何を使っているだろうか?
良いテキストエディタを選ぶことは本当に重要であり、いくらでも語るべきなのだが……とりあえず今は「正規表現を扱うためのテキストエディタ選び」という観点で考えてみることにする。
Windowsユーザは「サクラエディタ」を使おう
メモ帳を使っているという人。今すぐやめよう。メリット無いぞ。
とりあえずこの記事では「サクラエディタ」というテキストエディタを推奨する。メリットをいくつか挙げていくと……
無料である
軽い
利用者が多く、ノウハウの検索に困らない
正規表現を用いた検索・置換機能がある
タブ表示や画面分割機能(左右・上下)や指定行ジャンプ等、便利な機能が多い
「ソート(行の辞書順並べ替え)」「重複する行の削除」等の高度なテキスト整形機能が多い
「ひらがな→カタカナ」「カタカナ→ひらがな」「大文字→小文字」「小文字→大文字」等の痒い所に手が届く一括変換機能が多い
その他、「矩形選択」「キー操作の割り当て」「フォルダを対象としたGrep検索」「マクロ機能」等の便利機能が多く、拡張性が高い
「ソフトを勝手に入れるのは禁止だがサクラエディタなら使える」という場面がITの現場で結構あり、職種によっては使用機会が多い
等々。上記以外にも便利な機能が非常に多く、それだけで別途記事を書きたい気分だが、それはまた別の話。
便利なテキストエディタはこの世に無数にあるが、プログラミングをする人でも小説を執筆する人でもなければ「サクラエディタで十分」な可能性は高い。
というわけで、「サクラエディタ インストール方法」とかでググって今すぐインストールしましょう。
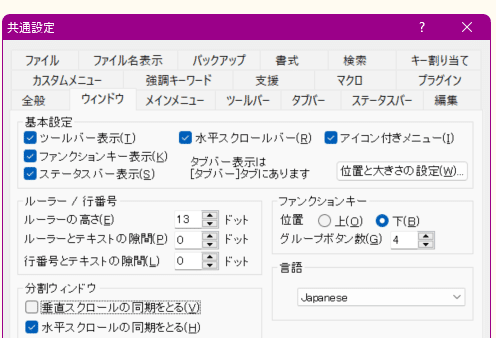
インストールしたら、上部バーの「設定」→「共通設定」から、以下の設定を変更することを推奨する。
「タブバー」と書かれたタブを選択
→「タブバーを表示する」にチェックを入れる
→「ウィンドウをまとめてグループ化する」にチェックを入れる

「ウィンドウ」と書かれたタブを選択
→「基本設定」配下のチェックボックスすべて(ツーバー表示、水平スクロールバー、等々……)にチェックを入れる
→「垂直スクロールの同期を取る」のチェックを外す
なお、基本的に最新版を正しくインストールできていれば「正規表現検索ができずエラーになる」ということはまず起こらないはずだが、もしかしたらbregonig.dllという必要なライブラリが正しくインストールできておらずエラーになる場合があるらしい。その場合は「bregonig.dll インストール」とかでググってうまいこと対処してほしい。
ここまでできたWindowsユーザか、他環境の人は次へ進もう。
Macユーザは「CotEditor」が良いらしい
筆者は詳しくないのだが、Macユーザにヒアリングすると「CotEditor」というテキストエディタが正規表現を用いた検索・置換ができるらしく、オススメする人が多かった。とりあえずこれをインストールしてもらうと以降の内容が理解できるはずだ。
なお、以下の設定がオススメだというありがたい情報をいただいたので是非設定しておいてほしい。
・[設定]>[表示]>[不可視文字] から、 [不可視文字を表示]をチェック
今後説明する「タブ文字」等が表示されるようになり、非常に都合が良い。種別ごとに表示/非表示が選べるらしいが、できれば全部表示に設定しておきたい。好みで調整しても良いが、「タブ」「全角スペース」は表示設定を推奨する。空白がある時にタブか全角スペースか半角スペースか一目で区別がつくのは非常に嬉しい。
・[設定]>[表示]>[フォント]で、「Osaka-等幅」等の等幅フォントを選択
CotEditorはデフォルトのフォントが等幅でなく、縦に揃いにくいらしい。最終的には好みの問題ではあるが、等幅フォントだと文字列を扱う上で都合が良いことは多そうなので、おすすめさせてもらいたい。
他環境の人はよく分からないごめん
正直全然分からない……申し訳ない……
この記事の今後の読み方
基本的にサクラエディタまたはCotEditorを想定した記事になる。
手順の説明はサクラエディタの使用例を画像を交えながら書く。
他の人は適宜察しつつ理解を深めてほしい。
サクラエディタ特有の機能はこの記事では扱わないようにする。
例えば、サクラエディタでは置換の時に「挿入」「追加」「削除」という特殊な置換機能が選べて超便利だが、この記事では普通の置換だけで頑張ることにする。
さて、では早速インストールしたテキストエディタを使って置換の勉強を……と行く前に。
申し訳ないのだが、少しコンピュータの内部的なお話のお勉強を挟ませてほしい。
真面目なお勉強タイム
こういうのはなるべく誤魔化して、「コンピュータの知識」を得なくても読めるようにしたかった。
ただ、どうしても説明しておきたいものがあったので、「タブ文字」「改行コード」「エスケープ」の3つだけ、説明させてほしい。
タブ文字とは
【事実20】キーボードにあるTabキーを押すと、「タブ文字」というものが1個入る。「タブ文字」は「キリの良いサイズの空白」として振る舞うため、文字の位置を縦に揃えて見栄えを良くするのに使える。
Tabキーを1度でも使ったことある人には自明な内容だろう。大抵のキーボードにあるTabキーを押すと、以下画像の場合では「スペース1個分~4個分」の中からその場所にとって一番都合の良いサイズで振る舞い、タブの次の位置を縦に揃えやすくしている。助かる。

なお、メモ帳ではタブ文字は目に見えないが、サクラエディタではタブ文字が見えるように表示を工夫してくれる。サクラエディタに同じテキストを貼るとこうなる。

タブ文字は「位置揃え」するのに非常に役に立つ。
プログラムを書くときは「意味のかたまり」ごとに先頭行を揃えると見やすい場合が多く、昔はタブ文字を積極的に使って位置揃えをしていた。
なるほどタブ文字は「位置揃えに便利なもの」らしい。ただ、それだけではない。
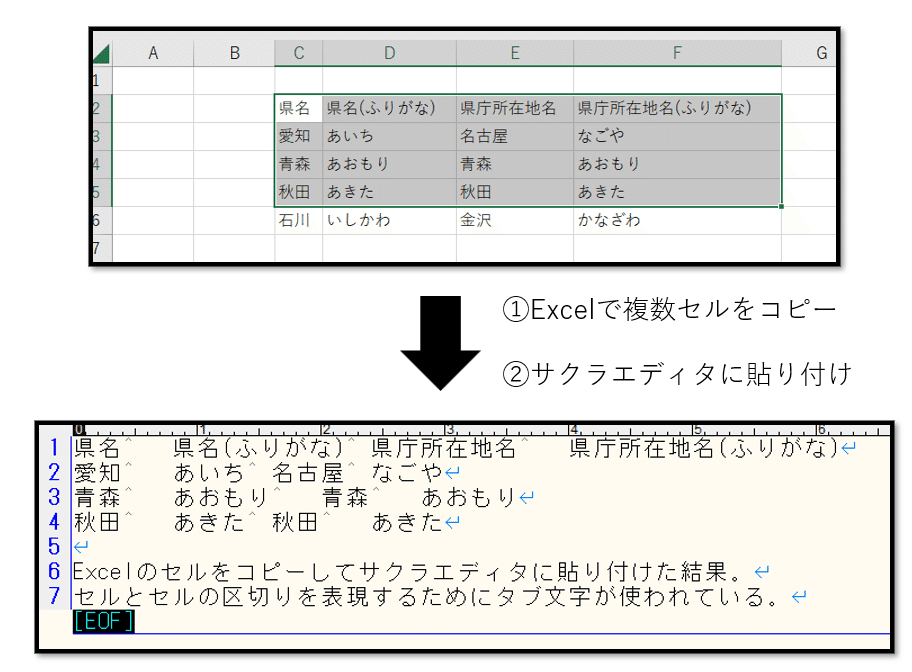
【事実21】「タブ文字」はテキストの文字位置揃え以外に、「区切り」という意味合いでいろんな機会で登場することがある。例えばExcelやWebページの表をコピーしてテキストエディタに貼りつけると、セルやマスの区切りがタブ文字になっている場合が多い。
実際にやってみよう。例えばExcelのセルをコピーする場合。
(この記事ではExcelで説明をするが、googleスプレッドシートでも基本同じ)
同様に、Webサイトの表からコピーしてきたものをテキストとして貼り付けるとどうなるか。とりあえずWikipediaの都道府県のページにある表を持ってこようか。

「なんかよく分からんけど急にタブ文字が出てくる場合があるんだな」と分かっただろう。その理解で大丈夫だ。
あともう一つ、知っておきたいことがある。それは、
【事実22】\t は「タブ文字」にマッチする
ということだ。
試しにサクラエディタで「\t」で検索をしてみる。
Ctrl+F を押すか、上部バーの[検索]→[検索]と選ぶと、下記のダイアログが表示される。
CotEditorの場合は ⌘+F を押すか、上部バーの[検索]→[検索]で「検索と置換」が開ける。


\t のtはそのまんまtabのtなので覚えやすく、ありがたい。
タブ文字を正規表現で表して嬉しいことあるの? と思うかもしれないが、ちゃんとある。期待しておいてほしい。
タブ文字の学習はこれで終わりだ。
・タブ文字は「イイカンジの区切り」であり、意外と出会う機会が多い
・タブ文字を表す正規表現は「\t」
ということをここでは学んだ。
改行コードとは
改行が何かは流石に知っている。Enterキーを押すと次の行の先頭に移動する「アレ」だ。
【事実23】キーボードにあるEnterキーを押すと、「改行コード」というものが1個入る。「改行コード」がある位置では改行が行われ、「次の行に移動+先頭位置に移動」が行われる。
改行されている場所には「改行コード」というものがあるのだ、と思っておけば良い。メモ帳では「改行コード」は見えないが、サクラエディタでは見える。見てみよう。

急に2種類の改行コードが出てきた。
色々な事情により、Windows環境とMac環境(等)では改行コードがコンピュータ内部で異なっている。の辺は歴史の話になるので、背景を理解する必要は無い。興味があればググってほしい。
これら改行コードにマッチする正規表現を知っておこう。
【事実24】\r\n は「Windows環境の改行コード」にマッチする。
\n は「Mac環境(等)の改行コード」にマッチする。
Windowsユーザは \r\n で、Macユーザ(等)は \n で覚えておこう。
タブ文字の時と同様にサクラエディタで検索した例を示しておこう。
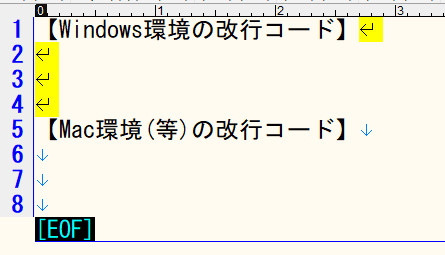

上の画像では2種類の改行コードが混在しているが、これはわざわざいじって混在させたものなので、普通に入力したら自分の環境の改行コードしか入らないことがほとんどであり、混在のリスクを意識する必要はほぼ無い。多分、
・「Macで作ったファイルを貰ってWindowsで開く場合」やその逆の場合に作成元環境の改行コードが入ってくる場合
・Excelやスプシで、1つのセルの中で改行をしている場合に、Windows環境でも\nの改行コードになってしまう場合
みたいなケースが大半だろう。
上記の場合は少し意識しておきつつ、普段は改行コードの違いを意識する必要はあまり無い。
※この世には「Windows環境で作った設定ファイルをLinuxサーバにアップロードして作業する人」みたいな人々が割といるのだが、そういう人々は元々改行コードの違いに敏感だから問題ない。ここでは無視する。
改行コードの学習はこれで終わりだ。
総合すると、
・改行がある場所に「改行コード」というものがある
・「Windows環境の改行コード」を表す正規表現は「\r\n」
・「Mac環境(等)の改行コード」を表す正規表現は「\n」
ということをここでは学んだ。
エスケープとは
脱出ゲーム大好きなみんなには聞き飽きた単語だろう。
エスケープ(escape)という単語は「脱出」等の意味だが、今は「正規表現として解釈されてしまう状況からの脱出」とでも思っておこうか。
どういうことか?
さっきのテキストに対して、「Mac環境(等)」という文章を検索することを考える。


これは正規表現として検索していることに原因がある。
正規表現において (~) というのは「グループ化」「キャプチャ」という特殊な意味を持っているため、括弧そのものを意味しない。
「Mac環境(等)」で検索をした場合、「Mac環境等」という文字列に対してマッチしようとしてしまうのだ。
同様の例で、
「3$」で検索しても、「末尾にある3」にマッチするが、「2022年12月時点で3$は約400円だ」にはマッチしない。
「^o+」で検索しても、「先頭にある1個以上のo」にマッチするが、この変な顔文字にはマッチしない。
さっきの例であれば「正規表現検索」のチェックを外せば良いのだが……
正規表現検索をしつつ、こういう記号の検索をしたい場合がある。
その時に「エスケープ」をし、「これはその記号そのものです」という意味を表現することが必要なのだ。
【事実25】\ を記号の直前に書くことで、「その直後に現れる記号」の特殊な意味を打ち消し、「その記号そのもの」を表すようにすることができる。
例えば、さっきの例であれば「Mac環境\(等\)」とか「3\$」とか「\^o\+」とかで書けばイケる、ということだ。
エスケープが必要な記号は以下の通り。個別に覚える必要は無くて、「正規表現で意味を持つやつはエスケープが必要」と思っておけば良い。
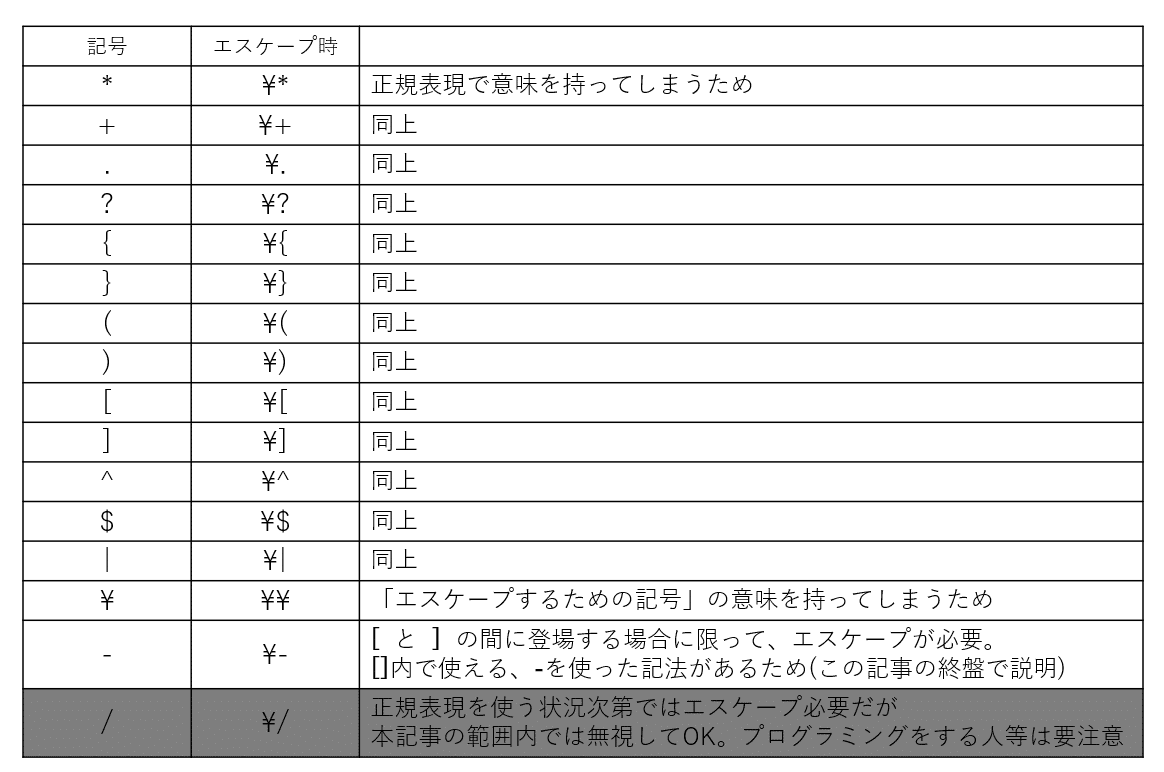
\ 自身もエスケープが必要なのが面白い。
確かに、万が一「\*」という文字列そのものを検索したくても、「\*」で検索すると、エスケープされた結果、ただの * にマッチする。
「\\*」とエスケープすれば良いのか? いや、これは「エスケープされた \ の後ろに*」となり、後ろの*は正規表現で解釈されるので、「0個以上の\」にマッチする。
「\\\*」とエスケープすれば、「エスケープされた \ と エスケープされた*」になるので、「\*」という文字列にマッチする。
複雑だ!
説明しておいて何だが、エスケープが必要な状況は、今日はたまたま出てこない。
ただ、今後置換を使いこなしていく中で、すぐにつまずくポイントだと思う。そういう注意点があることを知っておこう。
よし、これでエスケープの学習……というか、お勉強タイムは終わりだ。
・正規表現で意味を持つ記号は「エスケープ」することでそれそのものを表すことができる
・エスケープするには、直前に \ をつける
ということをここでは学んだ。
それではいよいよ「置換」について学ぼう。
正規表現講座7(置換の話)
置換とは、文字列を他の文字列に置き換えることだ。
・「日付を別の日付に修正する」
・「『様』を『さん』に変える」
みたいな、「何個も出てくる文字を一括で置き換えたい」という場合があり、日常で置換が役立つ機会は実は多い。
これが、さらにテクニカルな使い方を考えてみれば、例えば
・Webページ等から取得した情報を扱いやすく整形する
・Excelやスプレッドシートで処理しやすいように文字列を加工する
・文字列を加工して正規表現を生成する
なんて使い方をすることだってできる。便利そうな気がしてきたぞ。
サクラエディタにおける「置換」はCtrl+Rまたは上部バーの[検索]→[置換]と選択して呼び出すことができる。

CotEditorの場合は検索をする時に開いた「検索と置換」画面で置換も可能だ。(⌘+F で開ける)
サクラエディタと大体同じで、「置換」を押すと最初に見つけた文字列Aを文字列Bに置き換える。「すべて置換」を押すと、すべての文字列Aとを即座に置き換える。
ちなみに、「置換前」に書く記号が記号そのものを表したい時はエスケープが必要だが、「置換後」に書く記号では、ほとんどエスケープ不要だ。
それもそのはずで、「置換前」に正規表現を使うことはあっても「置換後」で正規表現を使いたいことは無いからだ。
正規表現は使わないが…… \r\n (改行コード) とか \t(タブ文字) とかで「\を使って表せる特殊なもの」は使えるので、 \ 自体を表す場合はエスケープが必要となる。あと、$1とか$2とか書く記法がある(後々紹介する)ので、この場合の「数字が直後に来る$」もエスケープが必要だ。
正規表現を使わない置換
置換そのものに慣れるために、正規表現を使わない置換の例を1つ示す。
同じ作業を繰り返し行うのが面倒な場合、「途中まではサボって、最後にまとめて一括置換する」というスタンスを取ると楽なことがある。
例えば、「濁音をちょうど2つ含む単語」を検索したい時。
^[^がぎぐげござじずぜぞだぢづでどばびぶべぼ]*[がぎぐげござじずぜぞだぢづでどばびぶべぼ][^がぎぐげござじずぜぞだぢづでどばびぶべぼ]*[がぎぐげござじずぜぞだぢづでどばびぶべぼ][^がぎぐげござじずぜぞだぢづでどばびぶべぼ]*$
という正規表現ということになる。長い。
正規表現は試行錯誤しながら組み立てることが多い。そんな時にわざわざこれを打つのは、コピペを駆使しながらでも面倒だ。
一時的に短い文字で代用してスッキリ整理しよう。
^[^d]*[d][^d]*[d][^d]*$
という風に正規表現の構造を組み立てて、一番最後に
「d」を「がぎぐげござじずぜぞだぢづでどばびぶべぼ」に置換
すれば良いのだ。


正規表現を使った置換(その1)
2つの実例を示しながら、「正規表現を使った置換」のよくあるケースを学んでいこう。たった2つの例を示すだけだが、その過程は非常に学びが多い。書いてあることを真似するだけでOKなので、実際にやってみてもらいたい。途中でわざと失敗例も載せているが、それも含めて体験すると良い。
突然だが、謎制作者はふと「都道府県名を名前に含む単語をいっぱい集めたいよ~」と思うことがある。
これは、
(あいち|あおもり|あきた|……|わかやま)
という正規表現さえ書けば検索できそうだ。
ただ、47個列挙するのは流石に面倒くさすぎる……
要領良くやりたい。欲を言えば2分以内にやりたい。
楽にやる方法を、置換を使いながら考えよう。
「都道府県」で検索して、とりあえずWikipediaの「都道府県」のページに辿りついてみよう。
(※普段なら「都道府県 ふりがな」で検索して出るもっと扱いやすい別サイトを使うのだが……こんな例に使うのもサイト様に申し訳ないので、今回はWikipediaを使ってみる)
取得してきた情報をもとに何らかの処理をしたい場合、
①選別するのは後回しで、とりあえず情報をガサっと取る
②不要な行を消す
③必要部分だけピックアップする
④必要な加工をする
という流れを踏むと良い場合がある。説明していこう。
①選別するのは後回しで、とりあえず情報をガサっと取る

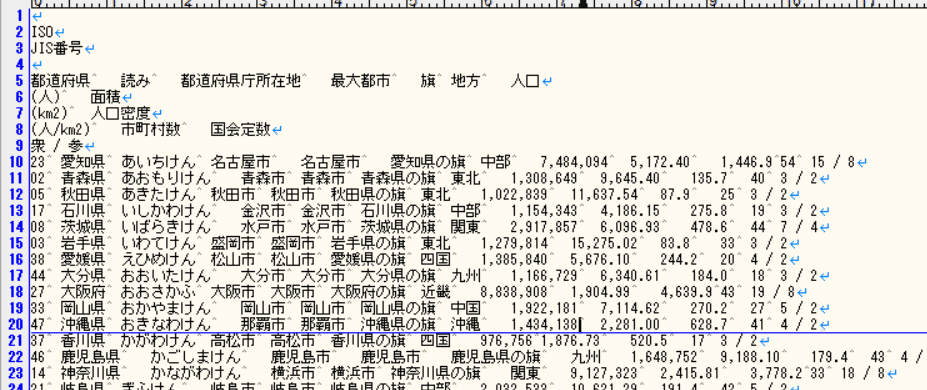
②不要な行を消す
今回は上にある数行を消すだけなので、正直手動でやれば良い。
ただ、場合によっては消すべき行が大量にある時がある。今回は、あえて正規表現を活用して不要な行を消してみよう。
「消したい行」「残したい行」の持つ特徴が無いかを探してみよう。
例えば、今回はたまたまだが、
「先頭に数字のある行を残したい」「他はいらない」
ということが分かる。
つまり、
「先頭が数字以外から始まる行」を「」(空文字列)に置換する
ことをやれば良さそうだ。やってみよう。
「先頭が数字以外」というのは ^[^0123456789] で書ける。
これは実は ^[^0-9] と書いても良い。(説明が地味に難しく、詳細は補足に回す。今は「ハイフンで範囲指定できる」という漠然とした理解でOK)
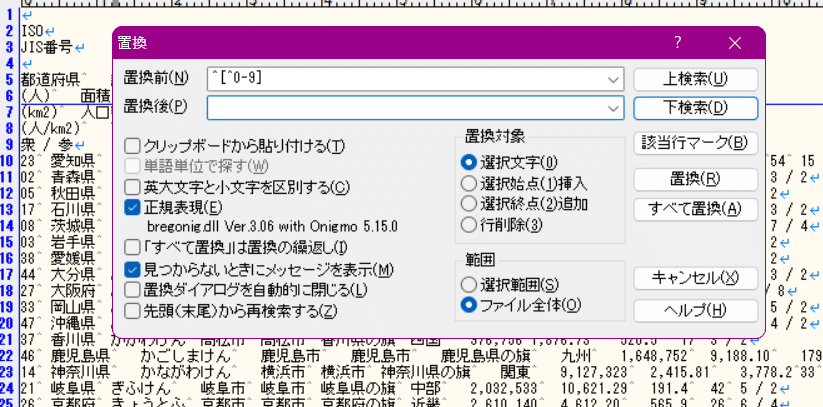

期待通りいかなかった。
置換する時は、「マッチした部分だけ」が置き換わるので気をつけてほしい。行全体が置換されるわけではない。行全体を置換したい場合、行全体にマッチする正規表現を指定する必要がある。
というわけで、例えば
「^[^0-9].*$」を「」に置換
してみようか。

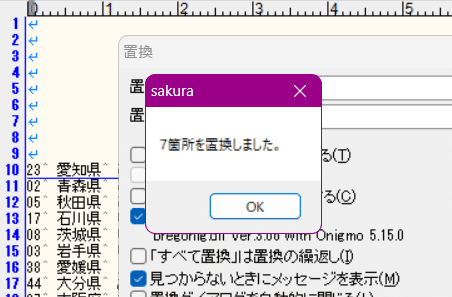
置換はできた。ただ、何もない空行が残った。
これを削除するにはどうしようか?
ずばり答えは
「^$\r\n」を「」に置換 (※Windows以外なら^$\n)
することだ。
^$ は先頭の直後に末尾がある、つまり何も文字が無いことを意味する。
そして、\r\n (改行コード) も置換対象にすることで改行ごと消し去るのだ。
これはよく使うド定番パターンなので是非覚えたい。
実際にやってみよう。

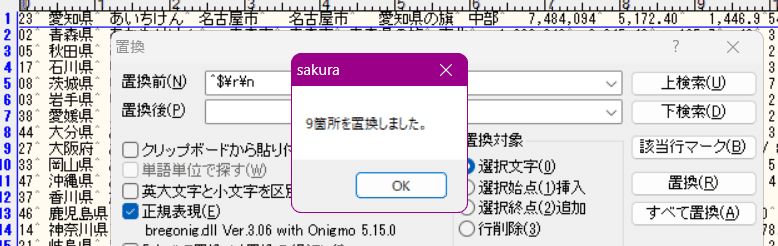
なお、分かりやすいよう段階を経て説明したが、
「^[^0-9].*$\r\n」を「」に置換
とすれば実は最初の一発目の置換で一気に解決できた。参考までに。
とりあえず、このようにすればまず「都道府県」を含む行だけを残すことができる。
今回はたまたま先頭が数字だったからラッキーだったが、そうでなければ特徴をうまく見極めて条件を考える必要がある。
ただ、今回の場合例えば「都道府県」を含まない行を消せばほぼ絞れそうな気がするから……
「^(?!.*[都道府県]).*$\r\n」を「」に置換
なんてやり方もあるいかもしれない。「否定先読み」は「~を含まない行」の検索に非常に役に立つ。
③必要部分だけピックアップする
必要行をピックアップした後は、その中の必要部分だけピックアップしよう。

いろんなやり方があるが、ここでは2案紹介しよう。
(案1) 2度に分けて置換を行う。
1回目:「先頭からタブ文字2つ目」までを置換で削除する。
2回目:「タブ文字以降すべて」を置換で削除する。
1回目の置換は……「^.*\t.*\t」を「」に置換すればできるだろうか? やってみよう。


これは、これまで説明していなかったが、これまで紹介してきた「個数に自由度を与える記法」には「最長マッチ」という性質があることに起因している。
【事実26】* と + と ? と {n} と {m,n} と {,n} と {m,} は、「可能な限り長い文字列にマッチ」しようとする。
最短マッチさせる記法も実はあるが、それを覚えるのはもっと熟練してからで良い。
「^.*\t.*\t」で「検索」をしてみるとよく分かる。下記の画像のように、「先頭から最後のタブ文字まで」がまるまるマッチしていたことが分かる。

こういう時の対処法はド定番のものがあり、.* (任意の文字列)で書いていた部分を、[^\t]* (タブ文字以外)にしてしまえば良いのだ。
つまり、
「^[^\t]*\t[^\t]*\t」を「」に置換
してやれば、「先頭から2番目のタブ」までを置換することができる。

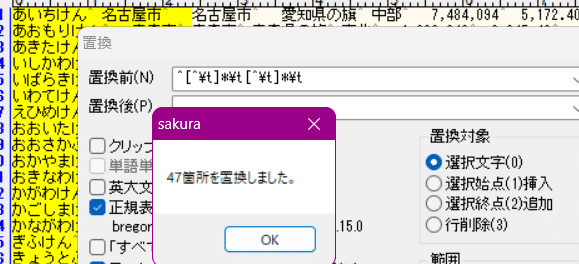
これで「都道府県名のよみがな」を先頭に持ってくることができた。
残りは、「タブ文字以降すべて」を消し去ってしまえば良いので、


ここで、「\t.*」を置換するだけで「行末まで全部」が置換されているのは、.* が最長マッチしているおかげだ。(不安ならば \t.*$ と書いても良い)
さて、これで(案1)の方法で「都道府県名のよみがな」の羅列を手に入れることができた。ここで、とても重要な(案2)もこのまま紹介してしまおう。
(案2) キャプチャを活用して、必要部分を抽出する
ここで大事な事実の紹介をする。
【事実27】() で括ってキャプチャされた内容は、「置換後」の箇所でも再利用することが可能。サクラエディタとCotEditorでは $1 、 $2 ……等で再利用ができる。
サクラエディタの場合は \1、\2、……でも可能だが、CotEditorではこれは不可能らしい。というわけで、$1、$2 ……で慣れた方が良さそうである。以後、筆者の過去の癖により \1、\2、……の表記で登場するが、近々修正しようと思うので、 $1、$2、……と書いてあるものと読み替えてもらいたい。読者は $1、$2、……で習得してほしい。
この事実はとても重要で、これを使えば「必要部分の抽出」ができるのである。

この状況で、
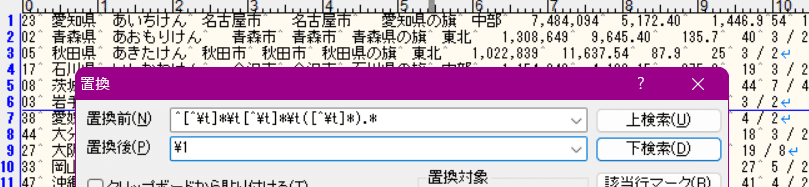
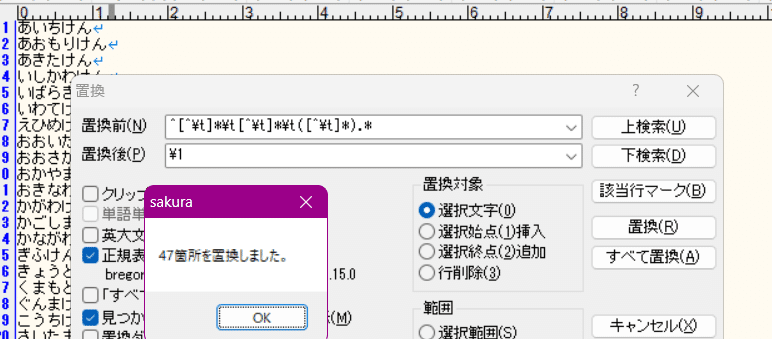
「^[^\t]*\t[^\t]*\t([^\t]*).*」を「\1」に置換
するとどうなるか。
タブ以外、タブ、タブ以外、タブ、(タブ以外)、それ以降
の、(タブ以外)部分をキャプチャして、\1 で参照できるようにしている。
その後、行全体を \1 に置換するので……各行を、キャプチャした(タブ以外)だけ残して他を消すことに等しい。
つまり、行の内「3番目の項目」だけが残る。
「列全体にマッチはさせつつ、必要箇所だけキャプチャで囲って、キャプチャ部分に置換する」という手法は、「必要箇所の抽出」をする時にとても便利だ。覚えておきたい。
とまあ何やかんやで、案1やら案2やらの方法で
「都道府県名のよみがな」が並んだ47行を作ることはできた。
④必要な加工をする
残りやりたいことは2つ。
・まず、「都道府県」を表す文字を消したい(「ぎふけん」→「ぎふ」等)
・次に、正規表現の完成形を作りたい
「ほっかいどう」を「ほっかい」にするのは少し気持ち悪いが、今は気にしないことにしょう。
「と」「どう」「ふ」「けん」を置換すれば良いが、「とやまけん」の「と」や「ふくいけん」の「ふ」が置換されると困る。
ただ、これはとても簡単で、今回なら
「(と|どう|ふ|けん)$」を「」に置換
すればOKだ。
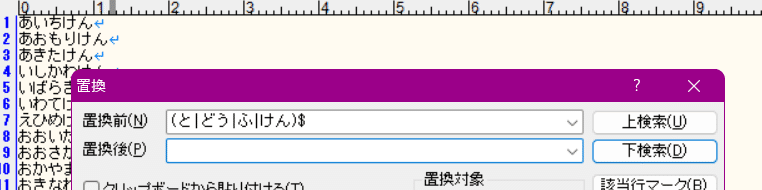

さて、後はこれらを | 区切りで一行で並べることでOR条件の正規表現にしたい。
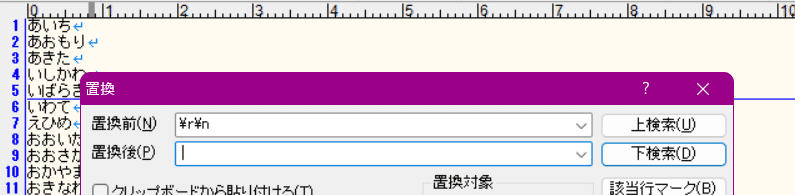
簡単だ。改行コードを置換すれば良い。
「\r\n」を「|」に置換 (※Windows以外なら\n)
すれば、改行コードが消えると同時にそれが | 区切りになる。

これで期待通り、
(あいち|あおもり|あきた|……|わかやま)
という正規表現を作ることができそうだ。前後を () で括ってあげれば完成だし、「括らなくても実は今回は問題ないよね」 の理解があれば、このまま完成として検索窓に突っ込んでしまって問題無い。
このように、様々なテクニックを駆使しながら、「都道府県名を名前に含む単語」の検索を効率的に行うことができた。
ここで得たテクニックはすべて応用性が非常に高いものばかりだ。
今回の説明は割と要領良く進め、少ない置換回数で実現している。
ただ、実際に置換で必要情報をピックアップする時は、無理に効率良く処理できなくても大丈夫だとを心得ていてほしい。
「まずはこれが要らないから取り除く、次にこれを消す、……」と、段階的に何度も置換を繰り返せば良い。
また、途中で手動でやれる部分を置換で頑張った部分があったが、その必要も無い。「数行消すだけ」みたいな、大した手間で無い作業なら、手動でさっさとやるほうが断然速いことは多い。よく見極めよう。
最終的にお目当てのものが手に入れば、その過程はどうだって良いのだ。
ただ、「手間な作業」「同じ作業の延々繰り返し」な状況であれば、正規表現の力を借りて積極的に楽することを考えよう。
正規表現を使った置換(その2)
正規表現を使って嬉しい例をもう1つ見てみよう。それは、初級編の練習問題でも出てきた「単語を構成する文字が五十音順に登場する単語」だ。
これを表す正規表現は
^あ?い?う?え?お?か?き?く?け?こ?さ?し?す?せ?そ?た?ち?つ?て?と?な?に?ぬ?ね?の?は?ひ?ふ?へ?ほ?ま?み?む?め?も?や?ゆ?よ?ら?り?る?れ?ろ?わ?を?ん?$
というものになる。これを全部書くのは割と面倒だ……
楽にやろう!
今回の場合、
①「あいう……わをん」という文字列を作る
②各文字の直後に ? を挿入する
③前後を ^ と $ で括る
ができればOKだ。
やってみよう。
①「あいう……わをん」という文字列を作る
・実は、筆者は過去記事「辞書登録は侮るな」でも述べたように「あいう……わをん」は辞書登録している。なので一瞬で文字列が作れる。謎制作者には辞書登録をオススメする。
・辞書登録していない場合、「こういうので検索してる輩がいそうだな」という謎の期待と共にgoogleの検索窓に打ち込んでみると、割と序盤の時点で「あいう……わをん」がサジェストされることが分かる。

とりあえず、何やかんやで「あいう……わをん」という文字列を作ることができた。
②各文字の直後に ? を挿入する
「元の文字列を残しつつ、新しい文字を挿入する」のは、これまた置換の出番だ。学んだばかりの「キャプチャした文字列をを置換後も呼び出せる」ことを使うと、
「(.)」を「\1?」に置換
することで解決する。
すべての文字を「元の文字」から「元の文字&その直後に?」に置換する。
これは要するに、各文字の直後に ? を挿入することに等しい。


③前後を ^ と $ で括る
流石にそれくらい手動でやれば良い。
正規表現に取り憑かれてきたら
「^(.*)$」を「^\1$」に置換
とか、
「^」を「^」に置換した後、「$」を「$」に置換
なんて方法を思いつくかもしれない。好みで好きな方を選べば良い。
①~③まで、筆者であればトータル10秒以内でできる。
これは別に筆者が特別速いからというわけではなく、①の辞書登録をしている前提で良ければ、みんなそれくらいでできるようになる。
練習問題part7 (全7問)
あり得そうなシチュエーションの、あり得そうな置換をやってみる例題を用意してみた。具体的なテクニック自体も大切だが、「こういう場合には置換を活かせば効率化できるんだな」という、使い所をひらめくセンスを養えると嬉しい。
様々な例を通じて、置換の便利さを伝えてきたつもりだが、伝わっただろうか?
置換による文字列加工という手段が日常的に選択肢にあるか無いかで、あらゆる物事のスピードが段違いに変わってくる。習得できるととても嬉しい。
余談:謎制作とはガチャである
「この単語が答えの謎を作りたいけれど、この順に含む単語は無いかな? 順不同で含む単語はあるかな? こういう特徴をプラスするとどうなるかな?」等々、謎制作には「検索」がつきものだと思う。
ツールを使わずに脳内であれこれ考える行為も含めて、広い意味での「検索」は恐らく謎制作に不可欠だ。
「何か良いの来い!」と思いながらひたすら検索をすることは多く、私は検索をよくガチャに例える。
良い謎ができた時、それこそ奇跡と呼べるような偶然の産物に出くわす時、まさしく「ガチャが当たった」ような感覚になる場合がある。色々と試し続けていたら、唐突に大当たりが出てきた。そんな時だ。
奇跡を人より多く見つける謎制作者がいる。
頻繁にUR報告をしてTwitter上を騒がせている。羨ましい。
ただ、そういう人々は決して運が良いわけではなくて、
・当たりの出やすいガチャを回している
・ガチャを回す回数が多い
・当たりが出た時に見逃さない
の3つを兼ね備えている可能性が高いと思っている。
そもそも面白くなかったり、極端に実現可能性の低かったりすることを検討しても、「当たり」が出る確率は低い。そのバランスをうまく見抜きつつ、面白くて起こり得る可能性を模索し、丁度良いガチャを回している。だから当たりが見つかる。
「ガチャを回す時間の短縮」と「ガチャ結果の見極め時間の短縮」をあらゆる手段で実現し、短時間で1回のガチャ試行を終える。すぐに次のガチャを回す。結果としてガチャを回せる回数が多い。だから当たりが見つかる。
せっかく当たり(と呼べる面白いもの)を引き当てても、その面白さに気付けなければ意味が無い。言葉のあらゆる特徴に敏感になり、その面白さを素早く見抜き、初めて見る当たりが出た時にもそれを決して見逃さない。だから当たりが見つかる。
……中には、「当たりに気付く感度」を常時高めることで、日常生活で出会うすべてがガチャになっている人もいるだろう。
謎制作にかけられる時間は有限で、大抵の制作には締切がある。ネタには旬があるし、流行りも人々の興味もすぐに移ろっていく。人生は短い。
ガチャを回せる時間は限られている。
「当たりの出やすいガチャを回す方法」や「当たりが出た時に見逃さない方法」はセンスに依存するところも多く、ノウハウ化しにくい。
一方で「ガチャを速く回す方法」はノウハウ化しやすく、再現性が高い。
効率的にガチャを回すために、この記事が少しでも活かされてくれると嬉しい。
次回予告
やめて!
Excelの特殊能力で作る全列挙型クソ長正規表現を説明されたら、noteを読んでる読者の精神まで燃え尽きちゃう!
お願い、死なないで読者!
あんたが今ここで倒れたら、肯定後読みや否定後読みやEnigma Studioとの約束はどうなっちゃうの?
ライフはまだ残ってる。ここを耐えれば、正規表現に勝てるんだから!
次回「読者死す」noteスタンバイ!
補足
補足1
途中でちゃんと説明しなかった事実を、ここで補足しておこう。
【事実28】[ ] の中で、 文字-文字 と書くと、その文字間の範囲指定を意味する。
[^ ] の中でも同様の範囲指定の書き方が可能である。
前後に使う文字は数字かアルファベットであることが多い。
説明がふわふわしているので、さっさと具体例を見よう。
[0-9] と書くと、これは [0123456789] と同じだ。
[3-7] の場合は [34567] と同じだ。
[^1-4] の場合は [^1234] と同じだ。
[a-z] の場合は [abcde……vwxyz] と同じだし、
[A-Z] の場合は [ABCDE……VWXYZ] と同じだ。
[^a-g] の場合は [^abcdefg] と同じだ。
なお、書き方は他と組み合わせて良く、
[0-9a-f] と書けば [0123456789abcdef] だし、
[0-357ai-kx] と書けば [012357aijkx] を表せる。
[a-zA-Z] の場合は 大文字小文字含めたすべてのアルファベットだ。
厳密には文字コード順で「間」を判定しているので、数字やアルファベット以外も可能だ。ひらがなの場合は [ぁ-ゔ] と書けば濁音半濁音拗音や「ゐ」「ゑ」「ゔ」も含めた範囲指定ができる。[あ-ん] と書きたくなるところなのだが、ひらがな部分文字コードの羅列が
・「ぁあぃいぅう……」で始まる
・「……わゐゑをんゔ」で終わる
という並びになっているので、厳密に書くならば[ぁ-ゔ] が正しい。
ひらがなの文字コードは直感的な順に並んでいないので、十分に注意してほしい。
特に、「清音だけ」をこの記法で表現することはできない。
これは「……かがきぎくぐ……」のような順で並んでいるせいだ。
「数字」「アルファベット」は直感的に扱いやすいが、他を扱う場合は相当慎重にやらないと事故りやすい。十分気をつけてほしい。
補足2
難しい話になるし、この内容のより詳しい説明が「上級編」にも登場するので、興味のある人以外は読まなくて良い。練習問題part6でQ33として登場した、「同じ文字がちょうど3度出てくる、6文字以下の単語」について話をしておこう。
元々、6文字以下という条件が無くても
^(?=.*(.).*\1.*\1)(?!.*\1.*\1.*\1.*\1)
という正規表現が検索可能だと筆者が脳内で誤解をしていた。
\1 の登場回数について、1つ目の肯定先読みが「3つ以上」という条件を足してくれて、2つ目の否定先読みが「4つ未満」という条件を足してくれると思ったのだ。
ただ、これは厳密には正しくなかった。
正規表現において2つの先読みの括弧は独立していて、それらを同時に検討はしてくれない。
最初に (?=.*(.).*\1.*\1) について検討がなされ、この時に
「3回以上登場するような文字」の内、「最後に登場するもの」が \1 にマッチする。
何故「最後に登場するもの」なのか?
それは、.* の部分が最長マッチしようとするからだ。
その後、(?!.*\1.*\1.*\1.*\1) で \1 が4回登場しないことの判定を行う。
つまりこれは、
「最後に現れる『3回以上登場するような文字』が、ちょうど3回登場する」
ような単語を検索してくれるのだが、当初の条件を満たしていないのである。
例えば……
豚辞書には載っていないが、「ねるねるねるね」という単語は
上記の正規表現でマッチしない。
「ねるねるねるね」の「後ろから3番目の『ね』」が \1 としてキャプチャされるためだ。
その後、\1が4回以上現れるかのチェックをすると、現れてしまうのでマッチ失敗となる。
正しく「る」を \1 でキャプチャできれば良かったのだが……
色々検討してみたが、本質的にこの問題を解決する手段は無さそうに思えた。
(「ねるねるねるね」をマッチさせることはできるかもしれないが、別のNG例を生む可能性がある)
本質的に解決するには「上級編」で登場する「後読み」を使えば良いのだが、実行環境の問題だと思うが謎解き単語検索βは「後読み」に少し弱い。
具体的には、「長さが確定していない文字列を後読みで使おうとする」場合にエラーとなってしまうのである。
そのため、問題を訂正させてもらうことにした。頑張って考えていた人は申し訳無い。
なお、先日わんど氏によって公開されたEnigma Studioは長さが確定しない複雑な後読みにも対応している。これについての記事を中級編で書く予定だったが、既に2万字を超えており入る余地が無かった……上級編を期待してもらいたい。