正規表現は今日から使おう(初級編)

前置き
この記事は、フライパン職人という珍妙なハンドルネームを名乗る正規表現大好き謎制作者(@1220oz_an)が、主に謎制作者向けに書く記事である。「謎解き問題に使えそうな単語を辞書ファイルから検索する方法」が延々と出てくるため、ITエンジニアが一般的な知見を得るのには到底適していない。万が一それを期待した人は回れ右してQiitaの記事でも漁ること。
なるべく正確な表現を心がけるが、伝わりやすさのために厳密には正しくない説明を織り交ぜる場合がある。許してほしい。
「初級編」「中級編」「上級編」の3部構成の予定だ。「自分は正規表現分かってるぜ」って人には「初級編」は多分易しすぎるが、「中級編」まで来ると徐々に有益なナレッジを提供できるだろう。「上級編」は脱落者が大量発生する可能性がある。「上級編」まで読むと何ができるようになるのか、という内容については中盤に用意した実力診断テストで示す。とりあえずそれだけはやってみよう。高得点だったらドヤろう。
前置きはここまで。続いて、正規表現講座に入る前に、まずは前提のお話から。
「旅に出ます 探さないでください」
謎制作者はよく旅に出る。「謎において必要な制約を満たす単語」を探すための、果てしない言葉探しの旅だ。制約が厳しくなるほど人力でやるのは難しいし時間もかかる。辛いし死にたくなる。頼むから殺してくれ。
謎制作は99%の言葉探しの旅と1%の謎制作で出来ている
— イリ (@Iri_No77) February 6, 2019
言葉探しの旅が終わった……あとは実装するだけ……
— フライパン職人 (@1220oz_an) July 11, 2020
ここ数年の謎制作ツールの発展は目覚ましく、言葉探しの旅が昔より圧倒的に早く終わるようになった。嬉しい。
これはごく少数のツール制作者たちの尽力のおかげであり、焼肉をn回奢っても足りない。深く深く感謝したい。
高度な謎を作るには検索ツールをより高度に使いこなすスキルが必要なのだが、そのために習得しておきたいものがある。
「正規表現」だ。
「正規表現ってよく聞くけれど正直何者か分かってないんだよね~」
「正規表現、覚えなきゃって思っているけれど永遠に覚えられない……」
謎解き界隈に居ると、そんな声をしばしば聞く気がする。正規表現の教材はこの世に無限にあるのだが、学習のとっかかりを見つけにくいのかもしれない。
確かに正規表現の勉強はした方がいいかもと思ったけどどの教材を使えば良さそうかわからん
— fumi (@hassi_kt) September 15, 2022
覚えられないという苦手意識が先行し、余計に避けるようになってしまっている人もいるのかもしれない。
ぶっちゃけ学習する良いきっかけが無かっただけという人も多くいることだろう。
そんな人でも、大丈夫。
大事なのは、正規表現をただ覚えることではなく、とにかく使ってみること。
なので、「とりあえず使える」ようになることを目指す。
暗記はひとまず後回し、覚えていないものは調べながら。
謎制作をする上でどう役立つのかイメージしながら、その便利さを実感しながら。練習問題をこなしながら。
正規表現を今日から使おう。
明日からではなく、今日から使おう。
正規表現とは言語である
正規表現がそもそも何か分かっていない人の中に、検索するツールか何かのことだと誤解している人がいる気がする。誤解したまま読み進めるのは理解の妨げになるので、一応整理しておこう。
正規表現とはその名の通り「表現」する手段であり、もっと言えば言語であると思って良い。
……どういうことか?
謎制作者はある時突然に、
「しりとり謎を作るのに必要だから、"『あ』で始まる、5文字または6文字の、末尾は『ー』『ん』以外であるような単語"を探したいよ〜」
と思うことがある。
かと思いきや、
「"『き』『ど』『あい』『らく』を羅列するだけで作れるような単語"を使って、『21=土器』『33=アイアイ』『14=?』みたいな法則謎(答えは『気楽』)を作りたいよ~」
と思うこともある。
この「~な単語」というのは、日本語で表現すると長くなるし、曖昧で伝わりにくくなる。
これが正規表現だと、1つ目は ^あ.{3,4}[^ーん]$ 、2つ目は ^(き|ど|あい|らく)*$ といった風に、簡潔かつ明確に表現できる。
このように、「ある性質の文字列の集合」を、簡潔かつ明確に表現することに適した言語が正規表現だと思えば良い。
正規表現に対応した辞書検索ツールを使えば、条件にマッチする単語をたくさん探せて嬉しい。正規表現に対応した文字列置換ツールを使えば、色々と便利で嬉しい。
そういった便利なツールとコミュニケーションを取るために、相手に伝わる共通言語を使えるようになることが、この記事における目標だ。最初からスラスラ喋れなくてもOK、文法を調べながらゆっくり読み書きできれば構わないのだから。
要するに、今からやることは言語習得だ。
大前提(ツールの使い方と基本姿勢)
「謎解き単語検索β」という、白猫さんによって開発されたツールがとても便利だ。これを使いこなすことを当面の目標とする。このページは、謎制作者であれば今すぐブックマークしてほしい。今すぐだ。
使い方は、shiwehiさんによる紹介記事がとても分かりやすく、読みやすい。謎解き単語検索βは正規表現検索以外の機能(特に「カスタム」にある機能)も超絶便利で、この機能を使いこなしていれば覚えずに済む正規表現が大量にある。
今回の記事ではあえて「カスタム」は使わず正規表現の力だけで頑張ることにするが、「カスタム」の機能は一通り知っておくべきなので、詳しくない人は後で必ず紹介記事を読もう。
「謎解き単語検索β」について最低限、以下の点だけ覚えてほしい。
「正規表現」タブから、正規表現を用いた検索ができること。
辞書ファイルは「豚辞書」「一般語」「英語」があり、デフォルトで「豚辞書」が選ばれていること。(この記事では、特に指定しない限り「豚辞書」のままで良い)
「豚辞書」「一般語」は日本語の単語がひらがなで収録されているため、検索条件はひらがなで入れる必要があること。
「豚辞書」は文字の大小の区別が無いが、「一般語」は大小の区別があること。


辞書ファイルについて詳しく知りたい人はわんどさんの記事「謎解きで使える言葉の一覧を集めたかった話 」参照。
また、謎制作目的の正規表現解説は、わんどさんと白猫さんが分かりやすくまとめたページが既にあるが、今はまだ読まなくて良い。
この記事を読んで以降、正規表現について色々と思い出したくなった時に、このまとめページを見て自力で解決する癖をつけていこう。その「自力で調べる癖」さえつければ、正規表現の暗記なんてまったく要らない。なお、このまとめページのブックマークは必須ではない。何故なら、謎解き単語検索βからリンクが貼られているからだ。
うわっ……私の正規表現力、低すぎ……?
この記事は正規表現を全然知らない初心者が脱落しにくいよう、なるべく丁寧に書くつもりだ。
ただ、そうすると「記事のレベル低すぎww」と思った人が早々に読むのをやめる可能性がある。
この記事では最終的はかなりハイレベルな内容まで触れたいと思っているので、正規表現が得意な人こそ最終的にこの記事のターゲットになると言っても過言ではないので、早期離脱されるのは悲しい。
なので、この記事が扱う範囲を事前に示しておく。以下の実力診断テストとして挙げた25問を見て、「自分はこの正規表現を書けるか」を自己採点してみてほしい。読み進めれば後々出る内容なので、ここには解説は無い。
※2022/12/28 Q20を訂正
参考:「ルーク語」という命名の初出ツイート
参考:「2-回文」という命名のおそらく初出ツイート
さて、25問の内、何問分かっただろうか。
解ける問題の数で雑にレベルを見積もるなら、正直こんな感じだと思う。
0〜1問:これから一緒に頑張ろう
2〜4問:正規表現を少しは分かっている
5〜7問:既に基本は十分できている
8〜10問:正規表現が使いこなせると胸を張ろう
11〜13問:正規表現で困ることはほぼない
14〜16問:ITの現場にいると非常に重宝される
17〜19問:正規表現スキルをもう持て余している
20〜22問:正規表現マニア
23〜25問:一緒に「謎制作のための正規表現」の研究をしましょう、リプライかDMをください
この初級編をマスターすれば15問目まで、中級編をマスターすれば20問目まで分かるようになる。逆に言えば、15問目まで分かる人は中級編が出たら、20問目まで分かる人は上級編が出たら戻ってきてほしい。そこまでは読み飛ばしてもらって構わない。
なお、今後、先ほどのようなスライドを定期的に挟むことにする。
・知識の紹介
・それを使った練習問題スライド
という構成で進め、今後の問題にはすべて解説を載せる。
練習問題はなるべく自力で考えてほしいし、実際にその単語検索をやってみてほしい。考えて分からなければ答えを見てしまって良いが、後々その復習をして、最終的にすべての問題に自力で答えを出せる状態を目指してほしい。
正規表現講座1(基本)
まずは基本から。この内容は最低限知っておくべきだし、早めに覚えておきたい内容たちだ。
【事実1】謎解き単語検索βの正規表現検索は、「部分一致するもの」を出力する
完全一致検索ではなく、部分一致検索になる。例えば「かうんと」で検索すると、「かうんと」以外に「あかうんと」「かうんとだうん」等もヒットする。(もちろん、「かうんと」そのものもヒットする)
【事実2】「正規表現で特殊な意味を持つ文字」と、「そうでない普通の文字」がある。とりあえず日本語(ひらがなカタカナ漢字)やアルファベット(abc……xyzやABC……XYZ)は普通の文字であり、それらは素直に「その文字自身」を表す
今後読み進めると、特殊な意味を持つ記号がたくさん登場して、それらはその文字自身を意味しないことが多い。例えば「3$」という文字列は、「2022年9月時点で3$は約430円だ」という文字列の「3$」の部分にマッチしそうに見えるが、$が特殊な意味を持ち、$という文字そのものを表さないせいで、マッチしない。
一方で、「サンドル」は「アレクサンドル・デュマの小説が好きだ」という文字列の「サンドル」の部分に素直にマッチする。
「具体的に何が普通の文字なの?」と気になるかもしれないが、その厳密な定義は今は省略する。とりあえず、「日本語(というか、全角文字全部)」と「a~z」「A~Z」は普通の文字だと知っておけば今のところはOKだ。
【事実3】^は「文字列の先頭」にマッチする
【事実4】$は「文字列の末尾」にマッチする
早速特殊な意味の文字が現れた。^ と $ は文字にではなく、「場所」にマッチする記号だ。
^あか は「(先頭)あか」にマッチするため、「あか」「あかうんと」「あかり」にマッチするが、「つめあか」「てあか」「つきあかり」にマッチしない。
あか$ は「あか(末尾)」にマッチするため、「あか」「つめあか」「てあか」にマッチするが、「あかうんと」「あかり」「つきあかり」にマッチしない。
当然だが、あか^ とかやると、マッチするものは何もない。「あか(先頭)」という状況はあり得ないので、当たり前だ。あ$か とかも同じ。
^ と $ を両方使えば、「完全一致」の検索が可能になる。^あか$ で検索すれば「あか」だけが出てくるだろう。
【事実5】.は「任意の1文字」にマッチする
. は、どんな文字にでもマッチする、ワイルドカードになる。^…..$ であれば5文字の単語すべてにマッチするわけだ。
練習問題part1 (全5問)
ここまで習った内容を使って、「この条件の単語」を検索する正規表現を考えてみよう。どんな謎に使えるか、例示以外にも色々イメージできるとgoodだ。
まだ非常に簡単な内容ばかりだったかもしれない。では、続きのお勉強に進もう。
【事実6】{n} は直前の文字がちょうどn個ある場合にマッチする
【事実7】{m,n} は直前の文字がm個以上n個以下ある場合にマッチする
{n} と書いてあったら「×n」の意味で、{m,n} と書いてあったら「×m~n」の意味だと理解すれば良い。これらは単独で意味を持たず、「直前の文字に条件を足す」という力を持つ。
^かた{3}き$ は、「かた×3き」なので、「かたたたき」にマッチする。
^かた{1,3}き$ は「かた×1~3き」なので、「かたき」「かたたき」「かたたたき」にマッチする。
^お{1,2}かみ$ は「お×1~2かみ」なので、「おかみ」「おおかみ」にマッチする。
ここで、「"ちょうど"n個」という条件と、部分一致検索とは実は混乱しやすいので、要注意だ。
例えば、た{2} は「た×2」=「たた」に等しいわけだが、「かたたたき」にもマッチする。(3個だからちょうど2個ではないのに!)
例えば、お{1,2}かみ は、「おおおかみ」にマッチする。(3個だから2個以下ではないのに!)

これは、「かたたたき」には た{2} が含まれているし、「おおおかみ」には お{1,2}かみ が含まれているからだ。部分一致検索というのはそういうことなので、くれぐれも混乱しないようにしたい。
ちなみに、た{2} だったら流石に「たた」と書けば良くない? と思うかもしれない。それはその通りで、この程度なら好きな方を使えば良い。
ただし、た{100} みたいなことをやりたくなったり、もっと複雑な条件を指定したくなった時、{n}みたいな書き方は楽で嬉しいのだ。これは徐々に実感できるはずだ。
なお、{m,n} のように「m個以上n個以下」を条件指定したい場合もあれば、「n個以下」「m個以上」の片方だけを条件指定したい場合もあるだろう。その場合は {,n} や {m,} のように、片方を空欄にすることで実現できる。
つまり、
【事実8】{,n}は{0,n}と同じ、{m,}は{m,∞}と同じ
ということだ。
ただ、この {,n} の記法は環境によって使えない時があるので注意。正規表現には方言があるので、通じる場合と通じない場合があるのだ。仕方ない。
{,n} がダメな時は {0,n} と左のゼロを省略せず書くことでうまく対処してほしい。{m,} の方はほとんどの環境で使えるので大丈夫。まあ、謎解き単語検索βは {,n} にも対応しているので、当分は心配要らない。
^かた{,3}き$ は かた{0,3}き と同じなので「かき」「かたき」「かたたき」「かたたたき」にマッチする。
^お{1,}かみ$ は「おかみ」「おおかみ」「おおおかみ」「おおおおかみ」……等々にマッチする。(もちろん「おおおおかみ」という単語は無いので検索でそれがヒットすることはないが、もしあればヒットする)
なお、{n} とか {m,n} とか {,n} とか {m,} とか の直前に置くのは文字じゃなくても良い。例えば、^.{3,4}$ と書けば「(任意の文字)×3〜4」なので、「3文字または4文字の文字列」すべてにマッチする。
少し後で紹介するテクニックを使うと、^(あい){1,2}$ は「(あい)×2」なので「あい」「あいあい」にマッチする。
^[あいうえお]{2,}$ は「(あorいorうorえorお)×2~」なので「うえ」「あおい」等の「母音だけで構成された2文字以上の文字列」にマッチする。
おっ、なんか、どんどん謎制作に使えそうな気がしてきたぞ。
【事実9】?は直前の文字が0個or1個ある場合にマッチする
【事実10】*は直前の文字が0個以上ある場合にマッチする
【事実11】+は直前の文字が1個以上ある場合にマッチする
これらの記号はすべて、{m,n} の特殊な場合だと思えば良い。
? は {0,1} と同じで、* は {0,} と同じで、+ は {1,} と同じだ。
これらは {0,1} とか {0,} とか {1,} とか書くのすら面倒なくらいに頻繁に使うので、この表記はとてもありがたい。実際、 ? とか * とか + とかはめちゃくちゃ使う。
特によく使うのは .* が任意の文字列(0文字以上)にマッチする事実だろう。
また、? が「その文字が1個現れるor現れない」にマッチする事実は、「特定の順に文字を拾うことで作れる単語」を探すのに適している。どういうことかは、練習問題で学んでみよう。
練習問題part2 (全8問)
少しずつ難しくなってくるから頑張ろう。
ここまでできればとりあえず「基本」は終わり。
少し発展的な内容に進もう。
正規表現講座2(基本+α)
この辺の内容だと、IT企業の人でもちゃんと覚えてないことは普通によくある。ただ、まだまだ超重要な内容ばかりなので、最終的には覚えることを目指すつもりで、定着するまで反復したい内容だ。
【事実12】[…]は、[ と ] の間に羅列された文字のどれか1文字にマッチする
【事実13】[^…]は、[^ と ] の間に羅列された文字"以外"1文字にマッチする
【事実14】(文字列1|文字列2|…|文字列n)は、| で区切りながら羅列された文字列のどれかにマッチする
ここで、…(三点リーダ)は実際にそう入力してほしいのではなくて、「ここに色々な文字を入れてね」というつもりで書いている。察してほしい。文字列1、文字列2、…も同様だ。
これらは要するに、「or条件」と「not条件」を使うための記法だと思ってほしい。
[あいうえお] は「あorいorうorえorお」という意味になり、母音(あいうえお)のどれか1文字にマッチする。
[がぎぐげござじずぜぞだぢづでどばびぶべぼ] は濁音のどれか1文字にマッチする。
[^あいうえお] は「not(あorいorうorえorお)」という意味になり、「『あいうえおのどれか』以外」=「あいうえおのどれでもないもの」にマッチする。
この使い方の時の ^ については、既に学んだ「先頭」の意味は持っていない。[^…] で一つの表現なのだと思ってしまおう。また、 ^ は必ず [ の直後に置いてほしい。[あ^いうえお] みたいな書き方はできない。
ここで注意したいのが、[…] や [^…] の間に羅列できるのは「1文字の文字列たち」だけだということだ。
例えば、[きどあいらく] と書いた時に「きorどorあいorらく」とはならず、「きorどorあorいorらorく」と解釈されてしまう。
「2文字以上の文字列のor条件も欲しい!」と当然思うだろう。大丈夫、そのための記法がある。
先程の例の場合、(き|ど|あい|らく) と書けば「きorどorあいorらく」と解釈してくれる。嬉しい。
ここで、orの意味を持つのは | であり、実は () で括る必要は無いのだが、一旦 () で必ず括るものと決めつけて覚える方が色々と楽だ。() については少し後で説明する。
ちなみに、2文字以上の文字列のnot条件もできるか気になるだろう。例えば「あか」を含まない文字列を、似た正規表現で表せるのだろうか?
しかし、その期待は打ち砕かれる。これはそう簡単にはできない。
[^あか] は「『あ』『か』以外」にマッチしてしまうし、(^あか) みたいな表現は無い(これは先頭にある「あか」にマッチするだけ)。
2文字以上のnot条件は「否定先読み」という高度なテクニックが必要になるので、中級編にて扱う予定だ。
そうそう、必須知識ではないが、(き|ど|あい|らく) は ([きど]|あい|らく) と書いてしまっても良い。「(きorど)orあいorらく」という意味になるが、結局は同じだ。このように、1文字のものだけ を […] でまとめることができる。
きどあいらくの場合はそんなに嬉しくないかもしれないが、([どれみそらし]|ふぁ) の場合だと、(ど|れ|み|ふぁ|そ|ら|し) と書く時より結構楽になる。嬉しい。
練習問題part3 (全8問)
お待たせ。待ち遠しかった?
正規表現講座3(やや発展)
この記事で学ぶのもあと2つ。() が持つ「グループ化」「キャプチャ」という2つの機能について学んでいこう。
【事実15】() で括られたものをひとまとまりのものとみなすことができる
先ほど「きorどorあいorらく」は (き|ど|あい|らく) と書けることを学んだ。実は「きorどorあいorらく」だけであれば、き|ど|あい|らく と書けば良く、() は要らない……のだが、() で括ることで「ひとまとまりにみなす」という効果が働いている。
どういうことか?
ここで、「『き』『ど』『あい』『らく』を羅列するだけで作れるような単語」の検索はどうすれば良いかを考えてみる。
この答えはシンプルで、^(き|ど|あい|らく)*$ と書くだけで良い。既にさっきの練習問題でさらっと登場させたが、比較的自然に受け容れやすい書き方だと思う。
これは、* は「直前の文字」の0回以上の繰り返しだったはずだが、() で括られた部分がひとまとまりのものと解釈できているので、「きorどorあいorらく」の全体に対して「×0~」の効力が発揮されているのだ。
では、() で括らず、 ^き|ど|あい|らく*$ とするとどうなるかというと、
「きで始まる単語」or「どを含む単語」or「あいを含む単語」or「らorらくorらくくorらくくく……で終わる単語」
となってしまう。(^き)or(ど)or(あい)or(らく*$) と解釈されたわけだ。うーむ、想定外。() をつけるか否かでこんなに変わるとは、事故としか言いようが無い……
とまあなんやかんやで、
() をつけた方が事故りにくい
「グループ化」というとても重要な機能の恩恵を受けておいて損することは少ない
ので、or条件の場合はとりあえず () で括るもの、と決めつけて覚えてしまって良い。上級編までいくと「キャプチャされてしまうと逆に色々めんどい」等のデメリットが気になる場合も出てくるが、その対処法はその時説明する。
ところで急に出てきたキャプチャって何?
ということで、() が持つもう一つの重要機能、「キャプチャ」を説明しよう。
【事実16】() で括られた内容が実際にマッチした結果を記憶(キャプチャ)して、後で \1 や \2 …等と再利用することができる
例えば、「証→アカシア」「今日→狂気」「スパイ→?」みたいな法則謎を作りたくて「先頭の文字と末尾の文字が同じ単語」が欲しい時がある。これは、^(.).*\1$ という正規表現で表せる。
^(.).*\1 は、まず先頭の1文字を () で括ることで「キャプチャ」しており、「() で括った部分にマッチした文字列は記憶されて、今後 \1 と書けばキャプチャした文字を呼び出せますよ」という状態を作っている。
その後末尾に \1 が出てくるが、その際にキャプチャした文字がここに自動的に埋めこまれてくれるのだ。
キャプチャするのは1文字である必要は無い。
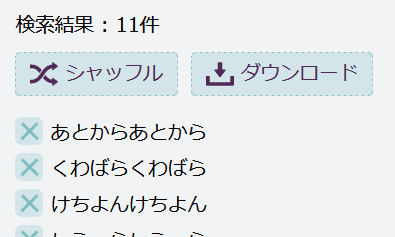
例えば ^(….)\1$ と書けば、「くわばらくわばら」のように、「同じ4文字の繰り返しになっている8文字の単語」にマッチする。
そもそも「任意の文字」をキャプチャする必要も無く、キャプチャしながら条件指定して良い。
例えば ([あいうえお]).*\1.*\1 とすれば、「いいあらそい」「うぞうむぞう」のように、「同じ母音が3回登場する」ような単語にマッチさせることもできる。(「しんかんせん」は3度登場する文字が母音でないのでマッチしない)
\1 なのは1番目にキャプチャしたものだからで、2番目、3番目、4番目……にキャプチャしたものは同様に \2 、\3 、\4 ……となっていく。
例えば ^(.)(.)\2\1$ は、「1文字目=4文字目 かつ 2文字目=3文字目」になる単語、つまりは「4文字の回文」にマッチする。

練習問題part4 (全6問)
今回の記事もこの練習問題で終わり。最後まで頑張ろう!
なお、参考までに。
10番目以降にキャプチャしたものを使いたい時は、\10 とか \20 とかの要領でそのまま書けば大丈夫だ。
環境によっては \1 〜 \9 までしか対応してないことがあり、その場合 \10 と書くと「\1 の後ろに数字の0がある」と解釈される場合がある……が、謎制作で正規表現を使うくらいであればその環境にはなかなか出会わないと思うので気にしなくて良い。そういう環境に出会うような人は、多分言われなくても分かっているはずだから。
この次も、サービス、サービスぅ♪
というわけで、「初級編」はここまで。
正直、この記事の内容を全部ちゃんと分かっていれば十分すぎるくらいに優秀だ。
分量は多いが、覚えるべき内容は意外と少ない。適宜復習して、使えるようになっていってほしい。謎制作で使う単語検索の8割は今回の記事のテクニックで十分に賄えることだろう。
例題をすべてスラスラ解答できることを目指しつつ、自分の謎制作の中で正規表現で検索すれば嬉しい場面が無いか、考える癖をつけていってほしい。
次回予告
正規表現の手を逃れた謎制作者を待っていたのは、また正規表現だった。
正規表現置換のためにインストールしたサクラエディタまたはCotEditor。
肯定先読みと肯定後読み、否定先読みと否定後読みとをブチまけた、
ここは正規表現大好きナゾクラのnote。
次回「正規表現は今日から使おう(中級編)」。
来週も正規表現に付き合ってもらう。
→ 中級編に続く
この記事が気に入ったらサポートをしてみませんか?