正規表現は今日から使おう(上級編)

ここまでのあらすじ
ついに上級編のはじまりはじまり。
なお、もしも以下の①と②の内容で分からないものがあれば「正規表現は今日から使おう(初級編)」を読み復習することを、③の内容で分からないものがあれば「正規表現は今日から使おう(中級編)」を読み復習することを推奨する。
①「初級編」で学んだ正規表現の記法について
以下の画像にまとめた。これらの内容は一通り分かっておきたい。

③「中級編」で学んだ正規表現の記法について
以下の画像にまとめた。「置換」のために扱った3行目以降の内容は今回要らないが、上の2行の「肯定先読み」「否定先読み」についてはこの記事を読む上で前提知識となるので、分からなければ「中級編」を読んでおいてほしい。

上記の知識があれば「初級編」「中級編」を読まずとも内容は理解できるだろうが、とはいえそれらを読んでいることを推奨することには変わりない。了承しておいてほしい。
なお、「初級編」「中級編」では、謎解き単語検索βというツールを使って単語検索をしていた。「上級編」ではこれの代わりにEnigma Studioというツールを使うことにする。使い方は後述する。
前置き
「初級編」「中級編」でも述べたように、これは「謎制作という目的のために正規表現を活用する」というマニアックな記事だ。普通のITエンジニア向けの記事を期待した人はQiitaを漁ろう。
「初級編」を読んだか、上で挙げた①が分かることを前提とする。「中級編」を読んだか、上で挙げた②が分かることを強く推奨する。必要なら適宜「初級編」「中級編」を読み返しながら読み進めても良いと思う。
ここからは難しい内容がさらに増える。分からないところは放置しても良いから、「Enigma Studioについて」「正規表現置換検索」「スマホで正規表現を使うための辞書登録」の章は読むことをオススメする。ここは最悪「中級編」の理解が不十分でも(一部分からない箇所はあるだろうが)、大体理解できるはずだ。
なるべく正確な表現を心がけるが、伝わりやすさのために厳密には正しくない説明を織り交ぜる場合がある。許してほしい。
Enigma Studioについて
2022年12月17日、わんど氏によって「Enigma Studio」という単語検索ツールが公開された。
【単語検索ツール公開】
— わんど (@wand_125) December 17, 2022
単語検索ツールEnigma Studio を公開しました
- 辞書の複数選択
- 「正規表現検索」
- はがき検索の拡張となる「正規表現置換検索」(画像参照)
- 大量の検索結果も高速に表示
- その他過去の単語関連ツールをこっちにどんどん移植予定https://t.co/ly6Ktoepkm pic.twitter.com/Ba1axBL3Oo
謎制作環境が大きく変化する革命的ツールであり、これを「ふーん、なんかすごそう」で流してはならない。
謎解き単語検索βと比較すると、以下の点が便利だ。(2023年2月時点)
・辞書の種類が多い
これが特に嬉しい。単語検索で使える日本語辞書といえばこれまで「豚辞書」か「一般語辞書」だった。
「豚辞書」は20年以上前に更新が止まっているし、文字の大小の区別が無いことに注意が必要だ。
「一般語辞書」は使用頻度の高いものに語彙に絞るために生まれた辞書だということが、強みでもあれば弱みでもある。
Enigma Studioには新語やスラング等に対応した辞書も多く、ほとんどで文字の大小の区別があるのがありがたい。
・複数辞書からの「一括検索」ができる
検索画面で辞書名が羅列されている中に「一括検索」というものがあり、これを選ぶと読み込み済の全辞書からの検索ができる。例えば「英語辞書とローマ字辞書から同時に検索ができる」のは嬉しいことがある。
・扱える正規表現の幅が広い
「後読み」の説明で詳しく述べるが、謎解き単語検索βやサクラエディタでは、後読みを使うとエラーになる場合があるのだが、Enigma Studioではならない。高度な正規表現を扱えて、とてもありがたい。ちなみに、逆に {,n} の表記はEnigma Studioで使えないようなので注意したい。{0,n} と書くように心がけよう。
(2023/3/28追記) iOS環境(iPhone等)のブラウザは長らく「後読み」に対応していなかったが、iOS 16.4以降、Safari 16.4以降では対応している。うまくいかない場合はバージョンの確認やアップグレードを試みてほしい。
・各自のローカル環境で動くので、重い検索をしてもサーバーに影響しない
謎解き単語検索βで重い検索をしてサーバーから応答が返ってこない……という経験をした人はきっといるだろう。
Enigma Studioでは各自のローカル環境で動くため、
・重い検索をしても他に迷惑がかからない
・リロードすれば検索を止められる
ので助かる。謎解き単語検索βは重い検索をしてしまうと、リロードしても無応答状態がしばらく続いてしまう。何度もやったことある。ごめんなさい。
・「正規表現置換検索」という便利機能がある
謎解き単語検索βにも「はがき検索機能」があり、これを使うと「文字列Aを文字列Bに置き換えた時、どちらも辞書に含まれている単語のペア」が検索できる。(例えば「ふらい,こてん」で検索すると、「フライ/古典」「フライパン/こてんぱん」が単語として存在するので「ふらい」「ふらいぱん」がヒットする)
Enigma Studioではこれに正規表現が使える。この記事で学ぶ知識を活かせば、「複数回現れる文字を消しても単語になるもの」といった、高度な検索を行うことができて便利だ。
一方で、謎解き単語検索βは以下の点が便利だと言える。
・検索の大半が直感的かつ楽に実行できる
これまで説明しなかった「簡単」タブでは、任意の文字を?に置き換えただけの簡易的で直感的な検索ができる。例えば「ふら?ぱん」で検索すれば「ふらいぱん」が出る。(「ふらんすぱん」は出ない)
特に、「カスタム」タブでできる検索は「~のみで構成される単語」「~を含む単語」「~を含まない単語」「~文字の単語」等の条件を正規表現を使わず楽に指定できるし、条件の重ねがけもできる場合が多い。先読み等の高度な知識が要らず、スマホから入力しやすくて嬉しい。
これら機能の詳細はshiwehiさんによる紹介記事を参照。
「謎解き単語検索β」「Enigma Studio」はどちらが便利というものではなく、用途によって適宜使い分ければ良い。
筆者は多分「謎解き単語検索β」を用いる機会の方が多い。それで事足りる場合が大半だし、それくらい「カスタム」機能の使いやすさには助かっている。
それで足りないと感じた時……高度な検索をする時や、他の辞書ファイルを使いたい場合等には、Enigma Studioを使っている。
今回はEnigma Studioの便利さに触れるので、それらの使い分けを各々で確立してもらえると嬉しい。
というわけで、Enigma Studioでの検索方法を理解しておこう。
①Enigma Studioトップの「辞書読み込み」画面にて、使いたい辞書を選択して「更新」を押すか画面の再読み込みを行う。
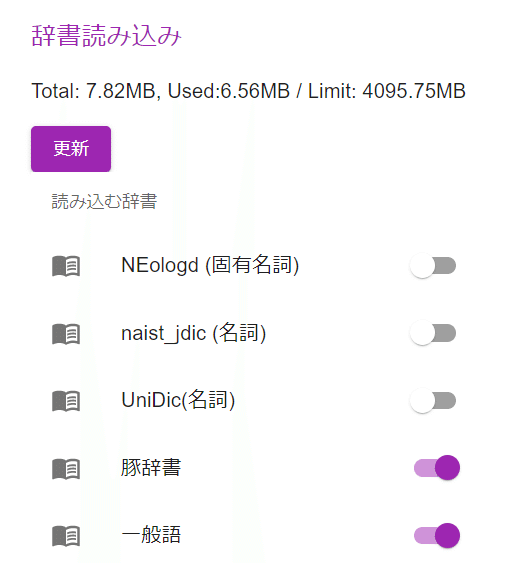
②左上のメニューから「正規表現検索」を選択する。
③入力フォームに検索条件の正規表現を入力する。「辞書」を選択して「検索」ボタンを押す。(もし「検索」ボタンがグレーアウトされている時は、辞書が正しく読み込めていないので再読み込みをしよう)
④検索結果が表示される。
正規表現講座7(細かいテクニックの話)
さて、ここからは正規表現の話だ。この章では、様々な細かいテクニックを説明する場所としたい。
①キャプチャせずにグループ化する方法
【事実28】(?: と ) で括られた部分は、グループ化されるがキャプチャされない。
中級編の中で「【事実18】() の冒頭に ? が来るような特殊な記法では、キャプチャの対象とならない」というものを紹介した。
この表記が「キャプチャの対象とならない」ことは、その時のルールに則っているので、(?:~) という表記があるということさえ覚えておけば、この記法の意味は思い出しやすい。
「え、これ何のためあるの? 普通の () の下位互換なのでは?」
と疑問に思った人もいるかもしれない。
今後、複雑な正規表現を書いていくと、「キャプチャは要らないけれどグループ化はしたい」という時が結構ある。しかも、そんな括弧が10個とかあったりする。それはそれとしてキャプチャしたい括弧も混ざっていたりする。
そんな時に全部普通に () を使っていると、
・ \1 、\2 等で指定するための数が何になるか数えるのが面倒
・正規表現を修正して括弧が増減する度に \1 、\2 等の数を修正するのが面倒
なので、キャプチャが要らないものは「キャプチャしない括弧」で書く方が嬉しい場合があるのだ。
なお、「キャプチャする時よりしない方が処理が速い」という側面もあるが、謎制作目的でこのレベルの処理速度の差を意識する場面は多分無い。
②任意長の回文とマッチさせる方法
さて、突然だが、「任意の文字長の回文」を表現することは我々の扱えるの正規表現ではできない。ただ、ほぼそれと同じ「n文字以下の回文」の検索ならば、実はできる。nは自分の都合で好きに設定して良い。
例えば、「9文字以下の回文」を検索する方法を考えよう。
「2文字の回文」は ^(.)\1$ で、
「3文字の回文」は ^(.).\1$ だ。
これをまとめて「2~3文字の回文」は ^(.).?\1$ で書ける。
この要領で書けば
「4~5文字の回文」は ^(.)(.).?\2\1$ だし、
「6~7文字の回文」は ^(.)(.)(.).?\3\2\1$ だし、
「8~9文字の回文」は ^(.)(.)(.)(.).?\4\3\2\1$ となる。
ただ、これらをそれぞれ分けて検索するのは面倒だ。そこで、「9文字以下」の回文をまとめて一気に表せる、
^(.?)(.?)(.?)(.?).?\4\3\2\1$
という表記が役立つ。
「たけやぶやけた」にマッチする時は
\1 は「た」、\2 は「け」、\3 は「や」が、\4 には空文字が入る。
「みみ」にマッチする時は
\1 は「み」が、\2~\4には空文字が入る。
? を使うことで、「マッチできる時は『1文字分』として振る舞いキャプチャするが、無理だったら『0文字分』として振る舞う」ようになるので、長さを自在に調節することができるのである。
結果的にn文字以下の回文にマッチすることができるのだ。
たまに嬉しい時があり、覚えておいて損はない。
③先読み条件のOR条件を判定する方法
先読みは複数条件の重ねがけができるということを中級編で学んできた。
これは要するに条件のAND条件の判定(複数条件がすべて同時に成り立つことの判定)をしている。
では、OR条件の判定(複数条件の内少なくとも1つが成り立つことの判定)をしたい場合はどうすれば良いのか。答えは簡単。
文字列の時のOR条件の場合と何も違いは無く、
(?:条件1|条件2|……|条件n)
と書けば良い。冒頭の ?: は必須ではないが、キャプチャ不要な場合はこう書いて良い。学んたばかりなので使ってみた。
条件の部分には先読み条件を書けば良い。先読み条件の複数個との羅列を書いても良い。
例えば、「『あ』『い』『う』の内2種類以上を含む」という条件で検索したい時、これは
「あを含む AND いを含む」
OR 「いを含む AND うを含む」
OR 「うを含む AND あを含む」
と解釈できる。
これを検索するのは
(?:(?=.*あ)(?=.*い)|(?=.*い)(?=.*う)|(?=.*う)(?=.*あ))
と書くことで実現できる。
これによって、AND条件とOR条件の複雑に絡み合った条件であっても、表現することができる。
④「\1以外の文字」にマッチする方法
唐突だが、「2度現れる文字」が3種類以上あるような単語を検索したい場合を考える。
条件の重ねがけが必要な予感がするので、「2度現れる文字がある」という条件を先読みで書くことを考えると、
^(?=.*(.).*\1)
となる。
では、それが3種類ある場合は
^(?=.*(.).*\1)(?=.*(.).*\2)(?=.*(.).*\3)
で良いのだろうか。駄目だ。
\1 と \2 と \3 には同じ文字がキャプチャされてしまい、結局「2度現れる文字」が1つであればマッチしてしまう。「いのしし」の「し」に\1も\2も\3もマッチしてしまうのだ。
2番目以降のキャプチャをする時に「それまでキャプチャしたものと違う文字」をキャプチャできるように工夫が必要だ。
例えば2番目のキャプチャでは「\1ではない文字」という条件を指定したい。
「~ではない文字」はこれまで [^~] だったが、[^\1] という表記は残念ながらできない。
しかし、ちゃんと代わりの方法がある。
【事実29】「\1ではない文字1文字」にマッチしたい場合、(?!\1). と書く。
キャプチャせずグループ化するなら (?:(?!\1).) と書く。
キャプチャするなら ((?!\1).) と書く。
中級編で学んだ「否定先読み」と組み合わせたものだ。「『この後に \1 が現れない場所』の次に現れる1文字」ということになるので、一見回りくどいが結果的に「\1 ではない1文字」にマッチする。
なお、「\1 でも \2 でも無い1文字」であれば ((?!\1|\2).) とか ((?!\1)(?!\2).) とかすれば良い。前者は (?!~) の~の部分にOR条件を並べた書き方で、スマートで恰好良い。この書き方を覚えておけば「\1 ~ \n のどれでも無い1文字」は((?!\1|\2|…|\n).)と書けるため、あまり長くならずに済むのが嬉しい。
以上の事実を活用することで、「2度現れる文字」が3種類以上あるような単語は
^(?=.*(.).*\1)(?=.*((?!\1).).*\2)(?=.*((?!\1|\2).).*\3)
で検索ができるということが分かる。
この記法は非常に便利で、「○○がn種類ある」という、個数ではなく種類数についての条件指定に役立つ。詳しくは練習問題を参照してほしい。
⑤先読みの中でキャプチャしておく方法
これまで、() でキャプチャする時は普通にマッチさせているケースばかりだったが、実は先読みの中でマッチさせることもできる。
(?=(.))
みたいな感じで書けるということだ。そのまんまだが、個人的にこのテクニックを「先読みキャプチャ」と呼んでいる。
これを使うと、例えば「6文字の単語で、どの文字も2度以上使われている」という単語は
^(?=(.)(.)(.)(.)(.)(.)$)(?=.*\1.*\1)(?=.*\2.*\2)(?=.*\3.*\3)(?=.*\4.*\4)(?=.*\5.*\5)(?=.*\6.*\6)
という条件で書ける。
最初の (?=(.)(.)(.)(.)(.)(.)$) の中で1~6文字目を \1 ~ \6 に代入してから、各文字についてチェックをしているような形だ。
例えば、「5文字の回文」は
^(?=(.)(.)(.)(.)(.)$)\5\4\3\2\1$
という風に表記することもできる。
ここで「n文字以下の回文のチェック」の時の記法を参考にすれば、
「9文字以下の回文」は
^(?=(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)$)\9\8\7\6\5\4\3\2\1$
で表すことができる。
この書き方が必須になることは少なく、大体は他の書き方ができる。ただし、こう書くと直感的で分かりやすく書ける場合が意外とある。後で再登場するので、頭の片隅に置いてほしい。
⑥OR条件を使った優先順位付きキャプチャ
(条件1|条件2|条件3|……|条件n)の要領でOR条件が指定されている時、条件1、条件2、……という風に左から順に判定が続き、最初にマッチするものが見つかるまで(あるいは全部試してもダメとなるまで)判定を続ける。
ではここで例えば、
^(.*あ|.*い|.*う|……|.*ん)
という正規表現を書くと、\1 には何がキャプチャされるか。
それは、
あが含まれるならば、先頭から「最後に登場する『あ』」まで
いが含まれるならば、先頭から「最後に登場する『い』」まで
……
んが含まれるならば、先頭から「最後に登場する『ん』」まで
がキャプチャされることになる。
つまり、「先頭から、『五十音順で最初の文字』まで」を \1 としてキャプチャすることができるのだ。
これだけではどう嬉しいか分からないかもしれないが、後で習う後読みと組み合わせて \1 の末尾の文字にさらにキャプチャさせることで「五十音順で最初の文字」だけを取り出すことができる。
これを活用して、後読みパートの練習問題には「『五十音順で3,1,4,2,5番目の文字』の順に登場する5文字の単語」の検索方法が出てくる。
例えば「こうしえん」がこれに該当し、「うえこしん」の5文字の中で「こ」は3番目、「う」は1番目、「し」は4番目、「え」は2番目、「ん」は5番目……ということだ。
五十音順に限らず、要するにOR条件の中で羅列した順番にチェックして、「最初に見つかったもの」にマッチさせることができる。五十音の逆順、いろは順、アルファベットのABC順……何でもありだ。
まだまだ活用方法がある気がするテクニックなのだが、まだ思いついていない。うまい活用が見出されてほしい。
練習問題part8 (全5問)
色々と変なテクニックを学んだが、中でダントツに役立つのが④「\1以外の文字」にマッチする方法だ。これの活用方法は計り知れない。様々な切り口からこれを活用するための練習問題を用意した。
また、1問目にさらっと②任意長の回文とマッチさせる方法活用も入れておいたので、合わせて練習しておこう。
正規表現講座8(全列挙型クソ長正規表現の話)
唐突だが、自分が過去に作った一枚謎の中で、個人的に1番好きな謎の話をさせてほしい。Twitterで一枚謎制作を始めて半年くらいの頃に作ったものだが、未だにこの謎が1番好きなのだ。
【謎090】
— フライパン職人 (@1220oz_an) June 12, 2018
今は夏。彼女はそれを思い出す。#解けたらRT pic.twitter.com/v49REJC3AO
少しの空行を挟んだ後に解説ツイートを貼る。
もし自力で考えたい人はスクロールせずに頑張ってみてほしい。
もうすぐ解説
解説
【解説/謎090】
— フライパン職人 (@1220oz_an) June 14, 2018
「白黒の世界の女王」はチェスのクイーンで、「ある場所」は五十音表。
「あらたなひに……またあえたなら」というこの詩は、最初から最後までをクイーンの動き(縦横斜め方向に移動)で辿れるようになっている。その法則を成り立たせるような色を?に入れる必要があり、答えは「青」。 pic.twitter.com/gfdBK7d3BH
チェスのクイーンで五十音表を辿った時に現れる文章で意味が通るポエムを作った、というものだ。当時これを自分は人力で作っていた。よく頑張ったなと思う。
さて、「五十音表を特定の制約で辿って得られる単語」というのはどうやら人々の興味を刺激する重要概念なようである。
2022年に「ルーク語」という命名がダブリング氏のツイートによって提案された。五十音表上をチェスのルーク(将棋の飛車)の動きで移動することで拾える単語のことである。
「いあいぎり」や「かくう」の様に五十音表をルークが動いた時に成立する単語群をルーク語と名づけてみます。他にあったら教えてください。#ルーク語 pic.twitter.com/kV3SBfxZ1c
— ダブリング (@saikoro2357) April 22, 2022
「ルーク語」という言い方は借りつつ、ルーク語と同様に、ナイトやキングやクイーンの動きで拾える単語を「ナイト語」「キング語」「クイーン語」と呼ぶことにしよう。
これら「ルーク語」「ナイト語」「キング語」「クイーン語」は、すべて正規表現で表せるし、十分に現実的な時間内でその生成ができる。ただ、テクニックが必要である。
では、どうやるのだろうか。
まずは、濁音/半濁音/拗音/伸ばし棒 を含まない単語で考えることにする。
多少工夫すれば濁音/半濁音の制約は何とでもできるので、一旦説明しやすい内容で検討させてほしい。
ルーク語とは、
1.「あ」の次に「いうえおかさたなはまやらわん」以外が現れない
2.「い」の次に「あうえおきしちにひみり」以外が現れない
3.「う」の次に「あいえおくすつぬふむゆる」以外が現れない
……
45.「を」の次に「わおこそとのほのもよろ」以外が現れない
46.「ん」の次に「あかさたなはまやらわ」以外が現れない
47.「あいう……わをん」以外の文字(濁音/半濁音/拗音/伸ばし棒)が現れない
という47個の制約をすべて満たす単語だと考えることができる。
47個目の制約はさほど難しくないので、1~46個目を考えよう。
「~であってはならない」という条件を加えるのは否定先読みの得意技だ。
例えば1. の条件は
(?!.*あ[^いうえおかさたなはまやらわん])
という否定先読みで表すことができるし、2.の条件は
(?!.*い[^あうえおきしちにひみり])
という否定先読みで表すことができる。
ならば……これらを46通りすべて書き並べてやれば良い。
な~んだ、それだけで良いのか~。だったら気合で頑張ればその内できるぞ!!!!!!!!!
いや、流石にめんどい!!
このような、面倒だが力技の発想で作る正規表現を、筆者は勝手に「全列挙型クソ長正規表現」と呼んでいる。面倒だが、それをやるしか方法は無い。ただ、人力でそれをやるのは非常に手間だ。
どうしよう?
文明の利器を使おう。Excel、あるいはスプレッドシートの出番だ。
以下のスプシの「ルーク語の作り方」シートに解説がある。
なお、「Excelやスプシの基礎知識」というシートには基本的な知識を書いておくので、Excelやスプシの基本が分からない場合には適宜参照してほしい。
また、ルーク語以外に以後の練習問題の解説もあるので、勝手に読み進めないように注意だ。
ルーク語そのものは「五十音表上をルークの動きで辿ったもの」であり、一度求めたらそれでおしまいの概念だ。ただ、その探し方を知ることは意義がある。例えば謎制作の過程で何らかの盤面を作った時に、「その盤面上を辿って拾える単語」を導けるわけだ。今後の制作の幅が広がるだろう。
※ただし、盤面に「同じ文字」が複数現れるとうまくいかなくなるので、その点は注意してほしい。
練習問題part9 (全3問)
全列挙型クソ長正規表現についての練習問題だ。全体概要の説明をスライドの中で行い、クソ長部分はスプシで解説をする、という二段構えの構造を取ることにする。
正規表現置換検索を使ってみよう
Enigma Studioの正規表現置換検索とは、謎解き単語検索βにある「はがき検索」機能を拡張したものである。
・置換前の文字列として正規表現を使える
・置換後の文字列の中で$1、$2、……を使うとキャプチャした文字列を呼び出せる
・置換後の文字列を空文字にできる
という三つの点で、従来の「はがき検索」機能より優れている。
使い方は簡単。
①Enigma Studioトップの「辞書読み込み」画面にて、使いたい辞書を選択して「更新」を押すか画面の再読み込みを行う。
②左上のメニューから「正規表現置換検索」を選択する。
③1つ目の入力フォームに「置換前の文字列」、2つ目の入力フォームに「置換後の文字列」を入力する。「検索辞書」「置換辞書」を選択して「検索」ボタンを押す。(もし「検索」ボタンがグレーアウトされている時は、辞書が正しく読み込めていないので再読み込みをする)

「『は』を『き』に変換したら一般語辞書に含まれるもの」を検索している例。
④そうすると、
・「検索辞書」に含まれる単語で、「置換前の文字列」を含むもの
・その単語の「置換前の文字列」を「置換後の文字列」に置換した場合に、「置換辞書」の中に含まれる単語
を検索してくれる。
色々と便利な使い方があるので、そのパターンを色々と挙げてみよう。
(パターン1) 「は」が「き」になっても単語となるもの
例:みえをはる→みえをきる
いわゆる「はがき謎」の典型例。謎解き単語検索βでも使える、基本中の基本の検索だ。これは、
置換前:「は」
置換後:「き」
で検索ができる。
(パターン2) 「こ」を消しても単語となるもの
例:しこつこ→しつ
いわゆる「こけし謎」の典型例。
置換前:「こ」
置換後:「」
で検索ができる。謎解き単語検索βでは置換後を空文字にすることはできなかったため、「消す検索」はEnigma Studio特有の強みだ。
(パターン3)末尾にある「てん」を消しても単語となるもの
例:ところてん→ところ
末尾の「てん」のみ消したいので、「てんせん→せん」みたいなのを除いて検索したい、ということだ。正規表現を活用して、以下のように検索できる。
置換前:「てん$」
置換後:「」
(パターン4)先頭に「はい」を足しても単語となるもの
例:きんぐ→はいきんぐ
置換前:「^」
置換後:「はい」
とすれば検索できる。なお、「先頭の『はい』を消す」という検索をしたところで得られる組み合わせは同じ(前後が逆なだけ)になるので、
置換前:「^はい」
置換後:「」
で検索しても構わない。
(パターン5)すべての母音を消しても単語となるもの
例:あうとどあ→とど
置換前:「[あいうえお]」
置換後:「」
でできる。正規表現が存分に発揮されている。
(パターン6)「連続する同じ文字」を1つに集約しても単語となるもの
例:かたたたき→かたき
キャプチャした文字列は $1 等として置換後で使うことができ、
置換前:「(.)\1+」
置換後:「$1」
とすれば期待の検索ができる。
あるいは、
置換前:「(.)(?=\1)」
置換後:「」
としても構わない。「直後に同じ文字があるような文字」を消しているわけだ。(「かたたたき」の2~3文字目にある「た」は直後に「た」があるから消え、4文字目の「た」は直後は「き」なので消えない)
先読みはあくまで「これ以降に~~が現れるような位置」にマッチするだけであって、文字列にはマッチしていない。(.)は置換されるが、(?=\1)は置換されない。
今、マッチした文字列は置換対象として扱われてしまうので、迂闊に文字列にマッチさせたくない。「文字列にマッチせず(位置にマッチさせて)条件チェックができる」という先読みの性質は、置換検索で条件を加える時にも有用で、ありがたい。
(パターン6)先頭から5文字目を消しても単語となるもの
例:おーすとらりあ→おーすとりあ
置換前:「^(.{4}).」
置換後:「$1」
で良い。「先頭の4文字+1文字」を「先頭の4文字」に変化させているので、「5文字目を消す」のと同じである。「n文字目」に関する置換を扱いたい場合、「1~n-1文字目」もとりあえずキャプチャしておくとうまくいくことが多い。
(パターン7)末尾から5文字目を消しても単語となるもの
例:せれくしょん→せくしょん
やるべきことは先頭の場合と本質的に同じで、
置換前:「.(.{4})$」
置換後:「$1」
でいける。なお、先読みを駆使すれば「.(?=.{4}$)」を「」に置換するのでも良い。
(パターン8)5文字の単語で、2文字目と4文字目を入れ替えても単語となるもの。ただし2文字目と4文字目が同じものは除く。
例:しゅしょう→しょしゅう
置換前:「^(.)(.)(.)((?!\2).)(.)$」
置換後:「$1$4$3$2$5」
で可能。n文字目~と言われたら全力でキャプチャを活用しよう。「2文字目と4文字目が違う」ことの検索のために、今日学んだ「\1以外の文字にマッチ」の時のテクニックもさりげなく使っている。
(パターン9)9文字以下の単語で、奇数文字目だけを読んでも単語となるもの
例:あきたこまち→あたま
置換前:「^(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)$」
置換後:「$1$3$5$7$9」
とすれば良い。「n文字以下の回文」の時のテクニックが役に立つ。
(パターン10)「ー」と「ん」が1度ずつ現れるような文字列において、それらの位置を入れ替えても単語となるもの
例:じんじゃー→じーじゃん
置換前:「^(?=.*ー)(?!.*ー.*ー)(?=.*ん)(?!.*ん.*ん)(.*)([ーん])(.*)([ーん])(.*)$
置換後:「$1$4$3$2$5」
やっていることが複雑になってきた。前半部分では、最初は先読みを使って「ー」と「ん」が1個ずつであることのチェックをしている。
(パターン11)文字が重複している場合に、一番最後に現れる1つを除いて他を消し去っても単語となるもの
例:しゅうちゅう→しちゅう(最後の「ゅ」「う」が残り、他は消えている)
やりたいことは「連続する文字を1つにする」の時とほぼ同じで、
置換前:「(.)(?=.*\1)」
置換後:「」
でいける。
(パターン12)9文字以下の英単語で、逆から読むとローマ字読みで単語になっているようなもの
例:iron→nori(のり)
置換前後でそれぞれ辞書を選択できることが効いてくる。
置換前:「^(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)(.?)$」
置換後:「$9$8$7$6$5$4$3$2$1」
という条件を入れつつ、検索辞書には「英語」を、置換辞書には「一般語ローマ字」を選択すれば良い。
さて、上記で12パターン例を紹介した。一部複雑なものもあったが、大半はこれまでの知識で十分いけるので理解できただろう。
現時点でも十分に便利そうに思えるが、実は今のままでは「ある弱点」を抱えている。
それは、
「置換したい文字列には必ずマッチさせないといけない」せいで、
「マッチさせた文字列よりも前の文字列」や「文字列全体」を使った判定が苦手
だということだ。例を2つ見てみよう。
1つ目の例。
「まとめがい」という変換法則を考える。「『ま』と『め』が『い』」なので、「めだま」は「いだい」になる。
ここで、
置換前:「[まめ]」
置換後:「い」
で検索すると、「ま」「め」の片方しか含まない単語がヒットしてしまい、期待通りの検索結果が得られない。
「めんどう→いんどう」がどちらも単語になることが分かっても、あんまり嬉しくない。折角ならば、「ま」と「め」が両方出てくる結果が欲しい。
文字列全体に「ま」と「め」が現れるという条件は、先読みを使えば
^(?=.*ま)(?=.*め)
と書ける。この先読みは冒頭に書きたいのだが、[まめ] をマッチさせつつこの先読みを書くのはとても難しい。
パターン10で似たようなことができていたのは、あの時は「ー」と「ん」が1度ずつという条件があったからだ。「ま」と「め」の個数を指定すれば可能なのだが、個数を指定せずに検索する方法は、今の知識ではできない。
2つ目の例。
「複数回現れる文字を全部消す」という変換を考える。
似たことをパターン11でやったが、あの時は「その文字以降に同じ文字が再び出る場合」にだけ消していたため、「最後の1個」を消し去ることができない。これをやるには「キャプチャ位置以前」にある、もう読んでしまった文字列を読み直してチェックする方法が必要になる。
そんな方法があるのだろうか……?
ある!
それが、この記事におけるラスボス、「後読み」だ。
より良い置換テクニックを身につけるため、後読みについて学んでいこう。
正規表現講座9(肯定後読み、否定後読みの話)
(2023/3/28追記) iOS環境(iPhone等)のブラウザは長らく「後読み」に対応していなかったが、iOS 16.4以降、Safari 16.4以降では対応している。うまくいかない場合はバージョンの確認やアップグレードを試みてほしい。
後読みについて説明する前に「先読み」「後読み」という名前についての話をしておく。
「先読みと後読み、どっちがどっちだったか混ざる」という人がたまにいる。気持ちは分かる。混ざりやすい名前だと思うし、これは日本語が致命的に悪い。英語では先読みはlookahead(前を見る)、後読みはlookbehind(後ろを見る)と言うので、「前方読み」「後方読み」等と訳してくれれば分かりやすかったのに、と思う。
「先読み」という言葉は「未来の先読み」とか言う風に、「これから先のことを読む」というニュアンスを感じてしまう。
ただ、そのイメージを持つのは望ましくない。
2つの意味で落とし穴があるからだ。
1つ目。「後読み」も「これから後のことを読む」になってしまい、区別がつかなくなってしまう。
2つ目。「先」という言葉は「これから先」の意味と別に、事前(今より先に~)というニュアンスも持ち、非常に混乱しやすい。
1つ目+2つ目のせいで、本来と真逆に覚えてしまっても「先読み」「後読み」が不自然なく通じてしまうのだ。まずい。
こう覚えよう。
・「先読み」とは、まだ到達していない文字列を「先に読んでおく」こと。
・「後読み」とは、既に通過した文字列を「後になってから読み直す」こと。
つまり、先/後 は時系列を意味しているのだと考えることにするのだ。
先読みは「先の文字列を読む」のではなく、「文字列を先に読む」。同様に、後読みは「文字列を後で読む」。
こう覚えることで混在しないように気を付けていこう。
ちなみに、この記事において(というか大半の人が学ぶであろう順番において)、先に学んだのが先読みで、後に学んだのが後読みだ。
よし、これでもう間違う心配は無い。
では、「後読み」が何かを学んでいこう。
【事実29】(?<=~) と書いた時、「この直前に~が現れる位置」にマッチする。
(?<!~) と書いた時、「この直前に~が現れない位置」にマッチする。
※謎解き単語検索βやサクラエディタでは、~の部分に「長さ不定の文字列」を使うことができないが、Enigma Studioでは可能である。
「その位置」の直前にある文字列について条件を与えるのが後読みだ。
例えば、正規表現置換の実用例の中で、
「末尾から5文字目を消しても単語となるもの」は
置換前:「.(?=.{4}$)」
置換後:「」
とやっても構わない、ということを書いた。
同様に、「先頭から5文字目を消しても単語となるもの」は、
置換前:「(?<=^.{4}).」
置換後:「」
とやっても良い。(?<=^.{4}) は、「『先頭から始まる4文字』が直前にある位置」にマッチする。その直後にある . は当然5文字目だということだ。
「2回目以降に現れた『ん』を消しても単語になるもの(1回目の『ん』は残す)」という場合には、
置換前:「(?<=ん.*)ん」
置換後:「」
とすれば良い。「まんがん→まんが」等がヒットする。
なお、(?<=^.{4}) はEnigma Studio以外でも使えるが、(?<=ん.*) は謎解き単語検索βやサクラエディタで使うとエラーになる。
正規表現には色々なバリエーション(方言と思えば良い)があるせいで、「長さ不定の文字列」を使えない場合があるからだ。具体的には、* や + や ? や {m,n} や {,n} や {m,} や、キャプチャした文字列の再利用(\1、\2、\3、……)や、長さが確定しないため、エラーとなる。
あと、(条件1|条件2|……|条件n) とした場合で条件の中で長さが不一致となる場合もエラーになる。すべて長さが同じならエラーにならない。
また、{n} はエラーにならない(長さが確定しているので)。
一見理不尽な仕様に思えるが、「長さ不定の後読みは迂闊に使うとめちゃくちゃ処理が重くなる」ので、処理が重くなるリスクを回避するための仕様なのだ。納得するしかない。
とりあえず、「後読みを使う時は基本的にEnigma Studioで使っておけば良い」と分かっておいてもらえれば大丈夫だ。
後読みを使うための定番パターンその1
後読みをうまく活用して、「文字にマッチさせつつ文字列全体の条件判定を行う」方法を考える。
そのための、自作の定番パターンをここでは提案する。とりあえずこの方式で書くことに決めておけば、先読みの知識だけで書けるので、分かりやすい。
【事実30】後読みを用いて「文字列全体に関する条件」の判定をする場合、
①後読みを書く場所はどこでも良い。キャプチャしたものを条件に使う場合は、キャプチャする文字の右に書くと楽で良い。
②(?<=^(先読み条件).*) という記法にできる場合、そうすることが望ましい。
①は「パターンその1」では一旦そんなに気にしないで良い。
②で提案している (?<=^(先読み条件).*) という記法を使って「『ま』と『め』が『い』」の検索を行うには、
置換前:「[まめ](?<=^(?=.*ま)(?=.*め).*)」
置換後「い」
と検索すれば良い。(先読み条件)の部分に、(?=.*ま)(?=.*め) を当てはめたような状況だ。
後読みを学ぶまでは、
・[まめ] にマッチさせる
・先読み条件を先頭位置に書く
を同時に実行できなかった。
これが今では「『先読み条件を満たすような先頭位置』が現在位置より前にある」という後読み条件を使うことで、先頭じゃない場所からでも先頭位置にフォーカスを当てて先読みを使えるようにしているのだ。
複雑だけれど、最悪意味の本質は理解しなくても良い。この形だけ覚えてしまおう。
「複数回現れる文字を消しても単語となるもの」を検索するには、
置換前:「(.)(?<=^(?=.*\1.*\1).*)」
置換後:「」
とすれば良い。(先読み条件)の部分に(?=.*\1.*\1) を当てはめたわけだ。
これで例えば、
「ババ抜き謎ということにしたいから、『2回現れる文字』は消えてほしいけれど、『3回以上現れる文字』はそもそも登場しないような単語だけ見つけたいな~」
と思った場合、
置換前:「(.)(?<=^(?=.*\1.*\1)(?!.*(.).*\2.*\2).*)」
置換後:「」
とすれば良い。(先読み条件)の部分に (?!.*(.).*\2.*\2) という否定先読みを追加したので、「3回以上現れる単語」を排除することができる。
ここで更に
「『みみ』みたいな短い単語が出てきても面白くないから、6文字以上の単語に検索結果を絞りたいな~」
と思った場合、
置換前:「(.)(?<=^(?=.*\1.*\1)(?!.*(.).*\2.*\2)(?=.{6,}).*)」
置換後:「」
とすれば良い。(先読み条件)の部分に (?=.{6,}) を追加したわけだ。
こうやって後付けで気軽に条件を足せるのは、先読みの時に実感したことだ。
この記事で提案する「後読みの中に先読み」という形を定番パターンとして使うことには、以下のメリットがある。
パターンを1つ覚えるだけで、先読みの時と同様に柔軟なかつ直感的に書けて分かりやすい。また、条件の追加削除が容易い。
後読みを複数回使う必要が無くなる。複雑な後読みを大量に使うことは処理を重くしがちだが、そうなりにくい。
否定後読みを使わなくて良い(後読みの中で否定先読みを使えば代用できる)ので、スッキリと書ける。
ここで、「定番パターンを使おう」と言ったは良いものの、覚えるのがしんどく思えた人がいるかもしれない。
というか、後読みの記法の ?<= や ?<! の順がそもそも覚えにくい。
一応、これは右から左に向かって
= or ! (肯定 or 否定)、 < (後)、 ? (読み)
と連想すれば多少イメージしやすいのだが、覚えたくなければ「辞書登録する」のが一番楽だ。ついでに先読みも登録してしまおう。
(?=条件) と (?=.*条件) と (?!条件) と (?!.*条件) を「;さき」で、(?<=条件) と (?<=^(?=.*条件).*) と (?<=^(?!.条件).*) を「;あと」で登録してしまうのがオススメだ。
;(セミコロン)で始めるのは、普通に「先」「後」を変換したい場合の邪魔にならないようにしたいのと、かつセミコロンが最も打ちやすい位置にある記号だからだ。その辺の思想は過去の記事「辞書登録は侮るな」を参照。

後読みを使うための定番パターンその2
「定番パターンその1」で扱えた条件は、
「文字列全体が『ま』を含む」とか
「文字列全体が同じ文字を3つ以上含まない」とか
「文字列全体が6文字以上である」とか
のような、「文字列全体に関する条件」に限る。
ここで、後読みの本来の意味である「特定の文字以前の文字列に関する条件」を検索する方法も学んでおこう。
例えば、
「2回目以降に現れた文字」を消したいような場合は、
「『ある文字』以前の文字列がその文字を含む」かどうかの判定をすれば良い。これは「定番パターン1」を使っても検索できない。
【事実31】後読みを用いて「特定の文字位置以前の文字列に関する条件」の判定を行う場合、
①後読みを書く場所に注意が必要。「この文字よりも左」についての条件は、その文字よりも左に書く方が楽で良い。
②キャプチャしたものを条件に使う場合は、先読みキャプチャを使うと楽で良い。
③(?<=条件) や (?<!条件)のように、先読みを使わず普通の記法を使えば良い。複数個重ねる場合はこの記法を複数個並べる。
まずは①について。
例えば、「2番目以降に登場する『ん』を消す(1番目は残す)」場合に、
置換前:「ん(?<=ん.*)」
置換後:「」
のように、「その文字よりも右」に後読みを迂闊に書くと失敗する。
1番目の「ん」にもマッチしてしまい、全部の「ん」が消えてしまうのだ。

「ん」の右に書くには、置換前の文字を「ん(?<=ん.*ん)」とかうまいことしないといけないのだ。注意深い人じゃないとすぐミスりそうだ。怖い。
後読み条件は「ん」の左に書くとうまくいきがちだ。

なので、今回の場合
置換前:「(?<=ん.*)ん」
置換後:「」
とすれば良い。それを定番パターンにしよう。
続いて②について。
文字の左に後読みを書くことに決めたは良いが、早速問題がある。
さっきの条件を「ん」に限定しない場合、つまり
「2番目以降に登場する文字はすべて消す(1番目は残す)」場合に、
置換前:「(?<=\1.*)(.)」
置換後:「」
とはできない。キャプチャする前に \1 を使おうとしているが、その時点ではまだ \1 に値が入っていないからだ。
普通ならば諦めてキャプチャする文字の右に後読みを書くところなのだが、既に知った「先読みキャプチャ」のテクニックが役に立つ。
つまり、
置換前:「(?=(.))(?<=\1.*).」
置換後:「」
とすれば良いのだ。
「先読みの中でキャプチャ」した時点ではまだ「文字の左」にいる状態をキープできているので、「文字の左にいながら\1を使う」ことができるのだ。最高。
(?=(.))(?<=\1.*). の末尾の . を忘れないように。置換したい文字はあくまでこれなので。(それ以前の括弧は、条件指定しているだけに過ぎない)
最後に、③について。
「特定の文字以前の文字列に関する条件」を1つだけ指定する場合は、(?<=条件) のように、先読みを使わない記法を使おう。先読みをすると「定番パターンその1」のように、勝手に「文字列全体に関する条件」になってしまうからだ。
なお、今の
(?=(.))(?<=\1.*)
は
(?=(.))(?<=^.*\1.*)
と書いても良く、このような ^ を使った書き方だと「文字列全体に関する条件」であれば追加で重ね掛けがすることができる。
例えば、
(?=(.))(?<=^(?=.{6,})(?=.*ん).*\1.*).
等とすれば、「文字列全体が6文字以上」「文字列全体に『ん』を含む」といった条件を追加することができる。
「特定の文字以前の文字列に関する条件」を追加で重ねることはできない。
先読みで書けるものしか重ね掛けできないからだ。それらは素直に後読みを複数個追加してしまおう。
例えば、
「2~3番目に登場した『い』はすべて消す(1番目、4番目以降は残す)」場合には、
置換前:「(?<=.*い.*)(?<!い.*い.*い.*)い」
置換後:「」
等とすれば、「いいんかいせい→いんかせい」(2~3番目の「い」が消えて1,4番目は残る) のような組み合わせを見つけることができる。
そんなのを検索したいことがあるかは分からないが。
以上、後読みを扱う上での定番パターンを2種類提案した。
「文字列全体に関する条件」の場合は定番パターン1を使う。
これは「後読みの中で先読みを呼び出す」というものだ。
「特定の文字以前の文字列に関する条件」の検索をしたい場合は、定番パターン2を使う。書き方自体は普通の後読みの書き方で良いのだが、「特定の文字」の左側に後読みを配置すること、そのために必要なら先読みキャプチャを駆使する、ということを注意するとミスりにくく、書きやすい。
後読みは検索においても便利である
この内容で「後読み」の学習は最後だ。
ここで学ぶ内容は即座に謎制作には活きないが、正規表現でやれることの可能性を探る上で重要な内容だと思うので、あえて書いておく。興味が無ければさっさと読み飛ばして練習問題に進んで良い。
これまで、まるで後読みは置換を行うときに真価を発揮するものと誤解させるような説明をしてきた。その方が説明が断然楽だったからだ。
ここではその誤解を解くために、「後読みはどんな時に便利なのか」の本質をちゃんと説明しよう。
唐突だが、
1. 「い」を2つ以上含む単語
2. 「い」をちょうど3つ含む単語
3. 「とある文字」をちょうど3つ含む単語
を色々な方法で検索することを考えてみよう。
その違いに触れてみようと思う。
1. 「い」を2つ以上含む単語
これを表す正規表現は、
い.*い
^.*い.*い.*$
等の書き方ができる。
ここで例えば、「^.*い.*い.*$」が「あいまいせい」にマッチするまでにどのような動きをするか、正規表現エンジンの挙動を見てみよう。
マッチする過程を見ることで、非常に興味深い性質をいくつか学んだ。
まずは、
.* 等の長さ不定のものの長さを、「うまくいくまで色々試してみる」
ということだ。この「ダメだったら後戻りして他も試す」というこの挙動をバックトラックと言う。うまくいくまで繰り返し、全通り試してもなおダメだったらアンマッチとなる。この時、最長から試して順に短くしていく。これは最長マッチの原則があるからだ。
もう一つ、
マッチするパターンは1つ見つかればそれでOKなので、全通り試さない
ということだ。
「あいまいせい」の「い」は3箇所あるので、実際に起こった「あいまいせい」にマッチしたパターン以外に「あいまいせい」「あいまいせい」というパターンも可能ではある。
可能ではあるが……それらを試すことはない。マッチするかしないか、だけが重要なのであって、どんなマッチができるかを全通り求めることは必要ないからだ。
では続いて、「い」をちょうど3つ含む単語を探すことを考えてみよう。
先読み無しで書く場合
^[^い]*い[^い]*い[^い]*い[^い]*$
となるが、肯定先読みと否定先読みを組み合わせて書くことで、
^(?=.*い.*い.*い)(?!.*い.*い.*い.*い)
という書き方をすることもできる。
ここで、このように先読みを2つ並べたケースでは、
1つ目の括弧の判定を行う。マッチしたら次に2つ目の括弧の判定を行う。ということが起こる。
この時に、例えば「いいたいほうだい」の判定について考えると、1つ目の括弧では「いいたいほうだい」という風に「い」が3個あることを見つければ判定を打ち切る。
この後「いいたいほうだい」「いいたいほうだい」「いいたいほうだい」
のような他パターンのチェックはしない。
この後2個目の括弧の判定をすると「いいたいほうだい」には「い」が4つあるからアンマッチになるのだが、その後バックトラックする場合にも、「いいたいほうだい」「いいたいほうだい」「いいたいほうだい」パターンのチェックが行われることはない。
1つ目の括弧がマッチとなるさえ確認できれば良いのだから、その中でどんなマッチが行われたかどうかを全通り知る必要はないということだ
さっきと同じ理屈だ。
一見これには何の問題も無さそうに見える。
が、実は困る場合がある。
1つ目の括弧と2つ目の括弧とに相関関係がある場合……具体的には「キャプチャした文字列が再利用される場合」には事情が変わってくるのだ。
今度は、「とある文字を3つ含み」かつ「その文字を4つ含まない」、すなわちちょうど3個含む文字がある単語を検索することを考える。
さっきの先読みにキャプチャを組み合わせて
^(?=.*(.).*\1.*\1)(?!.*\1.*\1.*\1.*\1)
でいけそうな気がする。でもこれはうまくいかない。何故か。
1つ目の括弧がOKになるパターンを1通り見つけたら、それ以外を試すことは無いという話をした。
ということは、「最初にたまたまマッチしたパターンにおいて、キャプチャした文字」を必ず使って2つ目の括弧の条件を判定してしまうのだ。
「ねるねるねるね」についてチェックすると、最長マッチ原則やら何やらのせいで、「ねるねるねるね」という風にマッチし、\1 には「ね」がキャプチャされる。この後2つ目の括弧の判定をするがうまくいかない。
2つ目の括弧で(\1=ねは4個あるから)アンマッチになるが、その後「ねるねるねるね」のパターンをチェックすることは無いのだ。
ここから、今回のケースを理解しやすくするために、筆者が勝手に生み出した「スコープ」という概念をイメージしてみよう。スコープという言葉は「範囲」という意味だ。

図のそれぞれの四角が「スコープ」と呼ぶ範囲だ。
正規表現全体は1つのスコープを持っていると考える。
括弧によって「グループ化」が起こると、今あるスコープの子供のスコープができる。子供のスコープから更に子供のスコープができる場合がある。
さっきの図では「正規表現全体」のスコープが2つの子スコープを持ち、その内一方がさらに子スコープを持っている。
あるスコープにおける条件判定では、「今いるスコープ」「その子孫のスコープ」の範囲内で探索を行う。
探索範囲内でバックトラックを繰り返して、
マッチするパターンを1つでも見つかれば「マッチ」とし、
全通り試してもマッチできなければ「アンマッチ」だ。
マッチした場合に、もしそのスコープ内でキャプチャしていれば、最初にマッチしたパターンのものが使われて、それで確定してしまう。
例えば、以下の図で、1つ目の括弧において探索をする時は赤点線枠の範囲内が探索範囲となる。

赤点線枠の範囲内の条件を満たす例を1つ見つければ「マッチ」で、最初に見つけたパターンでキャプチャ内容は確定する。
探索範囲外である黄色のスコープの条件は、\1 に干渉できない。
なので、「3つ含み、かつ4つ含まない」ような \1 をキャプチャすることができないのだ。
ではどうすれば良いのか?
キャプチャする括弧を、もう一つ上のスコープに持ってくるしかない。
ここで後読みの定番パターンを駆使すると、
(.)(?<=^(?=.*\1.*\1.*\1)(?!.*\1.*\1.*\1.*\1).*)
という書き方ができる。
この時、キャプチャする括弧(図の赤い括弧)が一番上のスコープにある。

この時、「キャプチャする値を決めるための探索」がすべてのスコープを巻き込んでいる。「3つ現れる」の「4つ現れない」の両方が、\1 でキャプチャする値を決定するための条件に組み込まれるのである。
「キャプチャの括弧を1番上に持ってくる」時に、
「キャプチャをしつつ」「先読みを駆使して文字列全体に条件を加える」ことが必要となり、それを実現できるのは後読みしかない。
これは、置換の時に後読みが便利だった理由と同じだ。
以上の内容をまとめる。
キャプチャした文字を使って、先読み等の括弧の中で判定を行う時は「スコープ」を意識する必要がある
「同じスコープ」「その子孫のスコープ」以外のスコープにある条件は、「キャプチャする文字を何にするか」という制約としては機能しない
結果、「同じスコープ」「その子孫のスコープ」で探索をして、「最初にたまたまマッチしたパターン」でキャプチャが行われてしまう。これを使って判定をした時、うまくいかない場合がある
うまくいってほしい場合、「キャプチャの登場するスコープ」「それを条件とするスコープ」が親子関係になるよう意識する必要がある
その時に、後読みが役立つ
ということだ。
難しい!!!!!!!!!!!!!!!!!!
ここまで分かったら大したもんだ。本当にすごい。
よく頑張った! お疲れ様でした。
練習問題part10(全6問)
では、最後の練習問題にいこう。長い旅もこれで一区切りだ。
スマホで正規表現を使うための辞書登録
話のテンションがだいぶ変わる。さて、これまでの記事の内容はすべて「PCで入力する」ことを想定してきた。
記事の内容がそうだったというよりも、そもそも正規表現は多数の記号を操る必要があるため、スマホで入力することにはまったく適していない。
ただ、謎制作のアイディアというのはいつどこで降ってくるか分からない。降ってきたその時その瞬間に色々と検索をしたいことはある。それが謎制作者という生き物である。
ならば、スマホでも正規表現を扱いやすいように「対策」をしておくべきだろう。辞書登録だ。
というわけで、こんなものはどうだろう。
zipファイルの中に入っているのは2つ目に貼った辞書登録用のtxtファイルだ。
Android端末でGboardに辞書登録を取り込む場合、このzipファイル自体を使って辞書取り込みができる。他の入力ソフトならtxtファイルでいけるかもしれない。分からないので、色々試行錯誤してみてほしい。
辞書登録の内容について、スタンスを紹介する。
(スタンス1) どの登録も「!(びっくりマーク)で始まる」ようにしてある。
普段使う時の邪魔にならないように、普通の入力と混ざらないようなものにするためだ。
!を選んだのは、フリックで入力しやすい記号だからだ。
(スタンス2) 「あかさたなはまやらわ」の文字を数字に対応させて考えている。あ=1、か=2、……、ら=9、わ=0 の要領だ。数字が絡む正規表現を変換で出したい時、この対応付けを分かっておくと入力しやすいようになっている。
以下に、登録内容を具体的に紹介しながら解説をする。説明を読みながら実際に辞書登録の内容に目を通し、内容を汲み取ってもらえると嬉しい。
(その1) . には 。を対応させることにして、「!。」で . を変換できるようにする。
* や + には 、 を対応させる。
!。 . 。は . に対応させる
!、 * 、は * と + に対応させる
!、 + 、は * と + に対応させる
!? ? ?はそのまま ? に対応させる
!。、 .* 。、 を .* に対応させる
!。、 .+ 。、 を .+ に対応させる
!。? .? 。? を .? に対応させる
--------------------------------------------------------------------------
(その2) .{m,n}や{m,n}等も登録しておく。
区切りの , は 、 を対応させる。
数字は あ=1、か=2、さ=3、……、ら=9、わ=0 と対応させる。
最大で{10}までの数字指定ができるように網羅的に登録をする。
!。か .{2} . 2 に対応させる
!か {2} 2 に対応させる
!。さ .{3} . 3 に対応させる
!さ {3} 3 に対応させる
……(中略)……
!。あわ .{10} . 1 0 に対応させる
!あわ {10} 1 0 に対応させる
!。あ、 .{1,} . 1 , に対応させる
!あ、 {1,} 1 , に対応させる
!。か、 .{2,} . 2 , に対応させる
!か、 {2,} 2 , に対応させる
……(中略)……
!。あわ、 .{10,} . 1 0 , に対応させる
!あわ、 {10,} 1 0 , に対応させる
!。、あ .{,1} . , 1 に対応させる
!、あ {,1} , 1 に対応させる
!。、か .{,2} . , 2 に対応させる
!、か {,2} , 2に対応させる
……(中略)……
!。、あわ .{,10} . , 1 0 に対応させる
!、あわ {,10} , 1 0 に対応させる
!。あ、か .{1,2} . 1 , 2 に対応させる
!あ、か {1,2} 1 , 2 に対応させる
!。あ、さ .{1,3} . 1 , 3 に対応させる
!あ、さ {1,3} 1 , 3 に対応させる
……(中略)……
!。あ、あわ .{1,10} . 1 , 1 0 に対応させる
!あ、あわ {1,10} 1 , 1 0 に対応させる
!。か、さ .{2,3} . 2 , 3 に対応させる
!か、さ {2,3} 2 , 3 に対応させる
……(以下略)……
!。ら、あわ .{9,10} . 9 , 1 0 に対応させる
!ら、あわ {9,10} 9 , 1 0 に対応させる
これらの要領で、
.{2}~.{10}や{2}~{10} (※.{1}と{1}は要らないので省略)
.{1,}~.{10,}や{1,}~{10,}
.{,1}~.{,10}や{,1}~{,10}
.{1,2}~{9,10}や{1,2}~{9,10}の全パターンを網羅的に登録する
--------------------------------------------------------------------------
(その3) 各種の必要な記号を登録するシリーズ | 編
!おあ (|) | を登録しておく。2条件のORの場合
!おあ (?:|) 2条件のORの、キャプチャしない括弧の場合
!おあ | 2条件のORの、括弧無しの場合
!おあか (|) おあ 2 に対応させる。2条件ORなので「!おあ」と同じ
!おあか (?:|) おあ 2 に対応させる。2条件ORなので「!おあ」と同じ
!おあか | おあ 2 に対応させる。2条件ORなので「!おあ」と同じ
!おあさ (||) おあ 3 に対応させる。3条件ORの場合
!おあさ (?:||) おあ 3 に対応させる。3条件ORの場合
!おあさ || おあ 3 に対応させる。3条件ORの場合
……(中略)……
!おああか (|||||||||||) おあ 1 2 に対応させる。12条件ORの場合
!おああか (?:|||||||||||) おあ 1 2 に対応させる。12条件ORの場合
!おああか ||||||||||| おあ 1 2 に対応させる。12条件ORの場合
「!おあ」の後ろに数字をつけたら「それだけ個数の条件のOR」を作れるよう登録する。
現実の謎制作にありがちなラインとして12条件まで登録しておく。
「n条件のOR」は「 | の個数がn個」とは異なるので( | の個数はn-1個になるので)、
混同しないように気をつけること。
--------------------------------------------------------------------------
(その4) 各種の必要な記号を登録するシリーズ いろんな括弧編
ー(伸ばし棒)を括弧に対応させる。(入力しやすいので)
伸ばし棒なことに理由はないが、何となくで覚える。
!ー () キャプチャ/グループ化の括弧
!ー (?:) キャプチャしない場合の括弧
!ー [] 「~のどれか」の括弧
!ー [^] 「~以外のどれか」の括弧
!ー。 (.) 1文字キャプチャする時用
!ー。、 (.*) .* をキャプチャする時用
!ー。、 (.+) .+ をキャプチャする時用
!ー。? (.?) .? をキャプチャする時用
!ー。か (.{2}) 2文字キャプチャする時用
!ー。か (..) 2文字キャプチャする時用
!ー。さ (.{3}) 3文字キャプチャする時用
!ー。さ (...) 3文字キャプチャする時用
……(中略)……
!ー。あわ (.{10}) 10文字キャプチャする時用(使うか?)
!ー。あわ (..........) 10文字キャプチャする時用(使うか?)
--------------------------------------------------------------------------
(その5) 各種の必要な記号を登録するシリーズ ^と$編
!はし ^ 「端」の記号なので
!はし $ 「端」の記号なので
!はし ^$ 両方があるケース
--------------------------------------------------------------------------
(その6) 各種の必要な記号を登録するシリーズ キャプチャ編
!→!→数字 で、その数字にちなんだキャプチャ絡みの記号を呼び出す。
あ=1、か=2、さ=3、……、ら=9、わ=0 と対応させる。
!!あ \1 1のキャプチャ
!!あ $1 1のキャプチャ(置換後文字列で指定する用)
!!あ (?!\1) 「\1以外」を指定する時の定番パターン
!!あ (?:(?!\1).) 「\1以外の文字1文字」を指定するパターン
!!か \2 2のキャプチャ
!!か $2
!!か (?!\2)
!!か (?:(?!\2).)
……(中略)……
!!かわ \20 20のキャプチャまで登録しておく(意外と10以降も使うので)
!!かわ $20
!!かわ (?!\20)
!!かわ (?:(?!\20).)
--------------------------------------------------------------------------
(その7) 各種の必要な記号を登録するシリーズ 先読み・後読み編
基本形ではどこに条件を入れるべきか見失わないように、
あえて「条件」という文字列を記載している。
使う時は「条件」の文字を消してからそこに入れていくことになる。
また、使いがちなパターンは便利なのでいくつか登録する。
!さき (?=条件) 肯定先読み
!さき (?=.*条件) 肯定先読みのありがちなパターン
!さき (?!条件) 否定先読み
!さき (?!.*条件) 否定先読みのありがちなパターン
!あと (?<=条件) 肯定後読み
!あと (?<!条件) 否定後読み
!あと (?<=^(?=.*条件).*) 後読みの定番パターン1
!あと (?<=^(?!.*条件).*) 後読みの定番パターン1
!さきー (?=[]) 肯定先読み+[]の括弧
!さきー (?=.*[]) 肯定先読みのありがちなパターン+[]の括弧
!さきー (?![]) 否定先読み+[]の括弧
!さきー (?!.*[]) 否定先読みのありがちなパターン+[]の括弧
!あとー (?<=[]) 肯定後読み+[]の括弧
!あとー (?<![]) 否定後読み+[]の括弧
!あとー (?<=^(?=.*[]).*) 後読みの定番パターン1+[]の括弧
!あとー (?<=^(?!.*[]).*) 後読みの定番パターン1+[]の括弧
!さきー。 (?=(.)) 肯定先読み+キャプチャ括弧
!さきー。 (?=.*(.)) 肯定先読みのありがちなパターン+キャプチャ括弧
!さきー。 (?!(.)) 否定先読み+キャプチャ括弧
!さきー。 (?!.*(.)) 否定先読みのありがちなパターン+キャプチャ括弧
!あとー。 (?<=(.)) 肯定後読み+キャプチャ括弧
!あとー。 (?<!(.)) 否定後読み+キャプチャ括弧
!あとー。 (?<=^(?=.*(.)).*) 後読みの定番パターン1+キャプチャ括弧
!あとー。 (?<=^(?!.*(.)).*) 後読みの定番パターン1+キャプチャ括弧
--------------------------------------------------------------------------
(その8) 咄嗟に呼び出せると便利な「●●な文字列」たち
!だく がぎぐげござじずぜぞだぢづでどばびぶべぼぱぴぷぺぽ 濁音+半濁音
!だく がぎぐげござじずぜぞだぢづでどばびぶべぼ 濁音のみ
!だく ぱぴぷぺぽ 半濁音のみ(多分登録要らないが……)
!みに ぁぃぅぇぉっゃゅょゎ 小さい文字一覧
!ああ あかさたなはまやらわがざだばぱ 母音が「あ」。母音を連続させて登録することに決めた。
!ああ (?:[あかさたなはまやらわがざだばぱ](?![ぁぃぅぇぉっゃゅょゎ])|.[ぁゃゎ]) 母音が「あ」(拗音含む)
……(中略)……
!おお おこそとのほもよろをごぞどぼぽ 母音が「お」
!おお (?:[おこそとのほもよろをごぞどぼぽ](?![ぁぃぅぇぉっゃゅょゎ])|.[ぉょ]) 母音が「お」(拗音含む)
!あいう あいうえおかきく(……中略……)らりるれろわをん 全ひらがな
!あいう ぁ-ゔ []で囲う時用
!えー abcdefghijklmnopqrstuvwxyz 全アルファベット(小文字)
!えー ABCDEFGHIJKLMNOPQRSTUVWXYZ 全アルファベット(大文字)、多分使う機会は無い
!えー a-z []で囲う時用
!えー A-Z []で囲う時用(大文字)、多分使う機会は無い「入力モードを切り替えなくても、すべて日本語入力モードで完結する」ことを目指して構成しているため、これらを正しく使いこなせればスマホからの入力は劇的に楽になる。是非導入してみてほしい。
前提として、筆者は普段Androidの端末で、フリック入力を使用している。その環境の自分にとって便利に使えるように作られている。iOS環境でもほぼ問題なく使えるはずだが、もし何かしら不便があったら申し訳ない。なお、フリックじゃない人は想定していない。あくまで「自分用のものを公開してみた」だけなので、ノークレームノーリターンでお願いしたい。
エンディング
「正規表現は今日から使おう」は、「正規表現について学べば出てくることをまとめただけ」にならないようにと意識して書いた。
筆者が数年間の謎制作を通して正規表現を使いこなす中で身につけた実用的なテクニックや、扱う上で重視してほしい本質的な考え方等、蓄積し続けてきたナレッジを2023年2月時点で一通り詰め込んで書いたつもりだ。
難しくてボリューミーな記事になってしまったが、それを頑張って最後まで読んでくれた人が大きく成長するきっかけとなってくれていれば嬉しい。
今の謎制作者のみならず、未来の謎制作者にとってもこの記事が役に立つことを願いつつ、一旦ここでこの記事は区切りとしておこう。
勝ったッ! 「上級編」完!
スペシャルサンクス
あさかぜ様、すーぴか様、Hibiki Yajima様、ブラッキー様、らまぬじゃん様
白猫様(謎解き単語検索β)、わんど様(Enigma Studio)
誤記指摘の他、追記すべき有益情報の提供や一部練習問題の考案等々等々、様々な面でご協力いただいたおかげで記事の内容を大きく充実させることができました。ありがとうございました!
また、謎制作者のために便利なツールを提供してくださるツール制作者にはいつも頭が上がりません。ありがとうございました! 焼肉行きましょう。
この記事が気に入ったらサポートをしてみませんか?