
【小ネタ】ゾーン別○○を作るためのRコードを書いた

「先週休暇を取られていたようですが、何をされていたんですか」
「実は旅行に行っていたんですよ」
「そうなんですか!ちなみにどちらへ?」
「○○県です」
「あら、実は私○○県出身なんですよ!のどかでいい所だったでしょう」
「あー、まあ意見には個人差がありますもんね」
「え、それってどういう意味ですか??」
「どういう意味か伝わらなかったみたいで安心しました。伝わっていたらもっとあなたを怒らせていたでしょうから」
「逆です、伝わったからどういう意味か訊いているんです。はやく説明して下さい」
「なんだ伝わっていたのか、でもそうだとしたらあなたの『どういう意味ですか??』は修辞疑問ですよね。『お前は私の生まれ育った地を舐め腐っていて不快だ』という指摘をあえて疑問文にすることで強調しているのだから、あなたが本当に求めているのは説明でなく謝罪だ。違いますか?」
「うるさいな、そこまで伝わっているならもう一手先回りして謝罪することぐらいしてもいいはずだろうが」
「謝罪するつもりがあるならハナからこんな重箱の隅をつつくような真似はしませんよ、それぐらい伝わりませんか」
こんにちは。So longです。冒頭の駄文で初見の皆さんは全員ブラウザバックされているでしょうから常連さん向けの文章を書きますね。すっかり低頻度更新となったこのアカウントに常連さんがまだいるのならば、ですが。
もうね、久々に更新するとnoteの機能も色々増えてて浦島太郎状態ですよ。太字がマークダウン形式で書けるようになっていたり、数式を
$$
\begin{array}{}
25-3 &= 23 \\\
\dfrac{3}{4} &= \int_{\infty}^{3} f(x-5^{x \delta \cos \theta})y dy
\end{array}
$$
突っ込んだりできます。すばらしいですね。下書きの保存もショートカットキーでできるようになっていて、テキストエディタを使って書いているかのようです。こんなことを書いているからもう1000字とかになってしまっているわけでもあり。
本題
さて、真面目にやりましょう。今回はStatcastデータにおけるゾーン別成績分析について。野球中継やらなんやらを見ているとよくこういうチャートを目にします。

ストライクゾーンを9分割して、投球が通過した位置ごとに打率や長打率を集計する分析アプローチの一つですね。Baseball Savantでは、ボールゾーンも4分割して表記しています。
各球種のコース別投球割合など、単に特定の投球コースに対する得意不得意と結論付けるのを妨げるような交絡因子が存在する
打率や長打率など、打席結果のみを集計する指標はいわゆる選球眼に相当するスイングコースの選択や、主にカウントを稼ぐために使われる球種の貢献度など、問題設定によっては重要なスタッツの情報を落としてしまう
客観的なデータ観測デバイス・集計ツールが存在しない環境の場合、そもそも投球の通過位置に関する情報が信用できないこともある
などなど、安易にゾーン分けして「このコースに強い!」をやるのには抵抗を覚える要素も少なからずあるのですが、少なくともその選手が残した結果がどのコースへの投球から生まれているのか、その概要を掴むうえでは非常にわかりやすい分析手法と言えるでしょう。
そこで今回は、私が必要に迫られてたまたま作成したチャート作成のための分析コードを、メモ書き程度の解説を添えて紹介したいと思います。Rを使っていますが、何をやっているかだけ把握できれば別にExcelでも十分再現可能というか、セル結合だったりを自由にやれる点ではむしろExcelの方がベターとすら言えます。でもダークモードで開いたエディタにカタカタスクリプトを打ち込みながら作る方がかっこいいもんね。必要を感じた方はPythonやらStataやらCやらC+やらC++やらに置き換えて下さい。
あ、やり方だけ分かればいい方はここまでの文章を飛ばしてくれて大丈夫です。この文を読んでいるということは飛ばさずにここまでいらしたということなんですけども。
実践
1. 分析対象とデザインを決める
記事の趣旨から言えば正直いらないんですが、一応問題設定をやっておきましょう。こういう時に役立つのは投手・野手どっちもやっていらっしゃる方です。
問題:ゾーン別集計データを使って、2022年シーズンにおける打者/投手 大谷翔平の強みを探る
評価基準としては、性質の異なる以下の指標を利用します。
「強さ」の定量化:使用する評価基準
打者大谷:wOBA
投手大谷:RV/100
指標の定義や意義については後で少しだけ解説しますが、詳細はBaseball SavantなりFangraphsなりに任せましょう。
2. データの取得とゾーン別成績集計
まずはデータの取得。Rなら baseballr パッケージの scrape_statcast_savant_* 関数から簡単に取得することができます。
library(pacman)
pacman::p_load(tidyverse)
# 呼び出し対象のパッケージがインストールされていない場合、自動でインストールしてくれる
p_load(baseballr)
p_load(viridis)
p_load(scales)(パッケージ依存の関数は最初に登場するときのみパッケージ名を明記しておきます。pacman::p_loadなど 抜け漏れは知らん)
データの取得に必要な大谷選手の固有IDもbaseballr パッケージから。
baseballr::playerid_lookup("Ohtani", "Shohei") # 出力から、MLBAMのIDは660271
id <- 660271df <- scrape_statcast_savant(
start_date = "2022-03-01",
end_date = "2022-11-30",
playerid = id,
player_type = "batter" # とりあえずバッターで、投手ならpitcherを指定
) %>% # パイプ演算子
filter(game_type == "R")
# STなどが入ってくるとめんどいのでとりあえずレギュラーシーズンの試合のみにこれでデータの取得が完了です。Excelその他のツールを利用する場合は、以下のnoteを参考に、Baseball Savantから直接csvデータをダウンロードしてみて下さい。今回使用しない各列の定義についても、今回は割愛します(参考)。

3. データの概要
取得したデータの内容を確認し、どのデータを利用すれば目的に見合ったデータを作成できるのか整理しましょう。以下のコードは必ずしも必要ありませんが、作業中に実行すると確認に役立つ関数群です。
head(df) # 先頭6行を表示
view(df) # R Studioで実行する場合:別タブでデータを開く
colnames(df) # データの列名を取得
skimr::skim(df) # データの要約統計量や簡単なヒストグラムを確認できる幸いなことに(そういうデータがある前提で書いている)、今回利用したい情報は全て取得したデータセットにデフォルトで含まれている変数ばかりです。
wOBAの算出
まず打者サイドのwOBAについてですが、これは読んで字のごとし、woba_value列にその打席結果に対するwOBAの係数が格納されています。また、打席当たりの割り算を行うための分母についてはwoba_denom列に値が含まれており、wOBAの分母に計上されるべき打席結果に整数1が割り振られています。それぞれの列を合計し、分子の列で分母を割ってあげればwOBAが算出できるというわけです。すなわち、各投球 i に関して、
$$
\begin{array}{}
\text{wOBA} = \dfrac{\sum_{i} \text{woba\_value}_i}{\sum_{i} \text{woba\_denom}_i}
\end{array}
$$
を計算してやればいいことになります。
係数値は分析対象とする期間によって微妙に変動するので厳密には再計算が必要ですが、ざっくりパフォーマンスを計算する上でここにエネルギーを使う意味は薄いと思います。必要に応じて得点期待値の再計算を行うなどしてやりましょう。2022年は打低環境だったこともあり、データセットに含まれる値にもとづくwOBAは小さめになるようです。
RVの計算
RVは投球ごとの得点期待値変動を合計してやれば算出できます。RV/100はこれを投球100球の単位あたりに変換したもの。例えば大谷選手が積み上げたパフォーマンスをコースごとに分解したい場合にはRV、それを受けてプラスを積み上げにくい「弱点」を探したい場合にはRV/100を利用するなど、詳細な問題設定に合わせて使い分けましょう。今回は投手を扱うので、マイナスが大きくなるほど失点阻止に貢献している、という見方になります。正負を裏返せば打者評価尺度としても利用できるのが強みの一つです。
wOBAと同じく、必要な情報はSavantの一球データに含まれています。delta_run_expがそれ。これを足し算したのがRV、100球あたりに直せばRV/100となります。
$$
\begin{array}{}
\text{RV} &= \sum_i \text{delta\_run\_exp}_i \\\
\text{RV/100} &= \dfrac{100}{N} \sum_i \text{delta\_run\_exp}_i
\end{array}
$$
ただし、Nは計算対象となる投球の総数に対応します。
投球コース
最後に、2つの指標をコースごとに集計するための変数。本来なら投球の通過位置を表す2次元の座標データ(plate_x, plate_z)からゾーンの区画を定義しなければならないのですが、Baseball Savantは普通の天才なのでこれも含まれています。zone 列をご確認下さい。1-9、および11-14の計13個のラベルが投球の通過位置を分類しています(10は欠番なので注意)。色分けして何番がどの位置にあたるのか確認してみましょう。
df$zone %>% unique() # zone列に含まれている要素を確認
df %>%
group_by(zone) %>%
summarise(
plate_x = mean(plate_x, na.rm = T),
plate_z = mean(plate_z, na.rm = T),
) -> sum
ggplot(sum) +
aes(x = plate_x, y = plate_z, fill = as.factor(zone), label = zone) +
geom_point(size = 10, shape = "circle filled") +
scale_fill_manual(values = viridis::viridis(13, option = "A")) +
guides(fill = "none") +
geom_label(sum, mapping = aes(x = plate_x, y = plate_z, label = zone), inherit.aes = F)
ざっくりストライクゾーンの内側が3×3 = 9分割、その外側の領域をインハイ・インロー・アウトロー・アウトハイの4つに分割した格好ですね。この11-14が曲者で、矩形を2つ組み合わせた形をしているのが面倒なんですね。
念のため、算出に必要な列を抜き出して確認しておきましょう。かなり横に長いデータなので、R Studioで開いても全容を確認するのは結構厄介です。
算出に最低限必要な列は以上です。最後にまとめて確認しましょう。
df %>%
select(woba_denom, woba_value, delta_run_exp, zone) %>%
head()4. 描画のための座標データを作成
データが出揃ったところで、いよいよ描画の準備を行います。ここでは、その手順を以下の3つに分類します。
対象となる指標をゾーンごとに集計し、テーブル形式で格納する
13のゾーンの領域を描画するために、各領域の頂点に当たる部分を格納したテーブルを作成する
座標を表すテーブルに、先ほど計算したゾーン別成績をくっつける
これだけ書かれても微妙なので、順に追っていきましょう。
ゾーンごとwOBA、RVの集計
ゾーン1のwOBAは.300, 2のwOBAは.350, 3は…というように、それぞれのゾーン番号とその領域でのスタッツが分かるようにまとめましょう。今dfには打者のデータが入っていると思うので、まずはwOBAからまとめていきましょう。
データフレームの要約統計量(平均、中央値など)を特定の変数ごとにまとめるには、tidyverse パッケージのdplyr::group_by()とdplyr::summarise()が便利です。group_byで変数zoneの値ごとに集計を行うことを宣言し、summariseの中でwOBAの計算式を定義します。woba_valueとwoba_denomはそれぞれ打席の結果球にあたる行以外で欠損値(NA)となっているので、それを無視して足し算を行うオプションna.rm = T を忘れずに。
woba_table <- df %>%
group_by(zone) %>%
summarise(
woba = sum(woba_value, na.rm = T) / sum(woba_denom, na.rm = T)
)
woba_table
こんな感じですね。すでに真ん中高め、2番のゾーンあたりに怖い数字がある気がするんですが、見なかったことにしましょう。
投手成績については、まず改めてplayer_type = "pitcher"でデータを集計する必要があります。が、RVの計算方法は変わらないので、以下に計算方法を記しておきます。最後に投手版の集計コードを一括で掲載しておきますね。
rv_table <- df %>%
group_by(zone) %>%
summarise(
N = n(),
RV = sum(delta_run_exp),
RV_100 = sum(delta_run_exp) / n() * 100 # n()で各zoneの列数=投球数が出る
)ゾーンごと成績の描画を行うための下準備を行う
次に必要なのが、13分割された投球コースをggplot2で描画してもらうためのデータの準備です。
多分色々方法はありますが、今回は一番楽そうなgeom_polygon関数を利用してゾーングリッドの描画を行います。geom_polygon()について詳細は以下のサイトを参照して下さい。
ざっくり説明すると、geom_polygonは指定した2次元の座標データで記述された点同士を結んだ図形を描いてくれる関数です。例えばパワポや手描きのように「ここに線を引く!」と決められるソフト・手段の場合は意識する必要はありませんが、Rのようにプログラムベースで描画を行うツールの場合、「ここ」を2次元の座標として記述してあげる必要があります。

今回は1つひとつの座標の値そのものには意味がなく、点同士の相対的な位置関係が分かれば問題ないので、例えばゾーン13の左下の頂点を原点(0, 0)、ゾーン12の右上のそれを(5, 5)として各の座標を割り当てることにしましょう。ゾーン1-9は正方形、11-14は矩形を重ねた図形なので、それぞれ4つ、6つの頂点の情報を与えればいいことになります。データフレームが定義できれば方法はなんでもOKですが、TJは関数tribbleを利用して定義することにしました。
ids_4 <- 1:9 # 1, 2, 3, ..., 9: 4つの頂点で構成される区画
ids_6 <- 11:14 # 6つ
zone_vector <- c( #1-9はそれぞれ4つ、11-14はそれぞれ6つ連続したベクトルを作ってくっつける
rep(ids_4, each = 4), rep(ids_6, each = 6)
)
positions <- tribble(
~ width, ~ height, # width, height列にそれぞれのグリッドの座標を定義
1, 4,
1, 3,
2, 3,
2, 4, #1
2, 4,
2, 3,
3, 3,
3, 4, #2
3, 4,
3, 3,
4, 3,
4, 4, #3
1, 3,
1, 2,
2, 2,
2, 3, #4
2, 3,
2, 2,
3, 2,
3, 3, #5
3, 3,
3, 2,
4, 2,
4, 3, #6
1, 2,
1, 1,
2, 1,
2, 2, #7
2, 2,
2, 1,
3, 1,
3, 2, #8
3, 2,
3, 1,
4, 1,
4, 2, #9
0, 5,
0, 2.5,
1, 2.5,
1, 4,
2.5, 4,
2.5, 5, #11
2.5, 5,
2.5, 4,
4, 4,
4, 2.5,
5, 2.5,
5, 5, #12
0, 2.5,
0, 0,
2.5, 0,
2.5, 1,
1, 1,
1, 2.5, #13
2.5, 1,
2.5, 0,
5, 0,
5, 2.5,
4, 2.5,
4, 1 #14
) %>%
bind_cols(zone = zone_vector)できたら一度データフレームを確認してみて下さい。
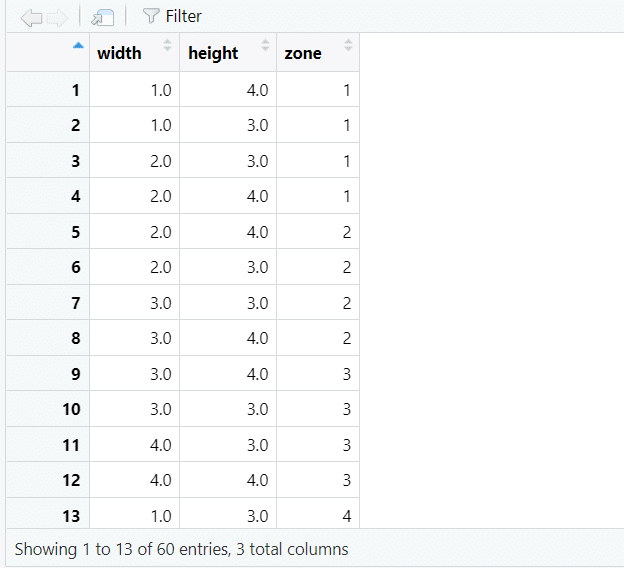
例えば、1-4行目はゾーン1に対応する座標が格納されていて、(1, 4), (1, 3), (2, 3), (2, 4)を結べばいいことが分かります。

11-14は6つの点を結ぶので、対応する頂点座標も6つになります。
さらにもう一つ、ゾーンの上に算出したwOBAやRVの値そのものを書き込みたい場合は、そのテキストを表示する座標データも作成しておかねばなりません。これも具体的な座標は見やすい位置に調整してくれればいいですが、正方形のグリッドならばその中心にテキストが来るようにしておくのが無難でしょう。ゾーンと表示場所の座標なので、13行のデータになります。
text_position <- tribble(
~ zone, ~ width, ~ height,
1, 1.5, 3.5,
2, 2.5, 3.5,
3, 3.5, 3.5,
4, 1.5, 2.5,
5, 2.5, 2.5,
6, 3.5, 2.5,
7, 1.5, 1.5,
8, 2.5, 1.5,
9, 3.5, 1.5,
11, .5, 4.5,
12, 4.5, 4.5,
13, .5, .5,
14, 4.5, .5
)ここまででようやく②の手順が終了です。だりい。
geom_polygon()関数の動きもざっくり把握しておきましょう。今回の定義の場合、横軸にwidth 列、縦軸にheight 列を取ります。groupにzone 列を指定して、頂点をグリッドごとに線で結ぶという宣言を忘れないようにして下さい。
ggplot(positions) +
aes(x = width, y = height, group = zone) +
geom_polygon(colour = "dodgerblue", fill = "hotpink") +
theme_dark() +
coord_fixed()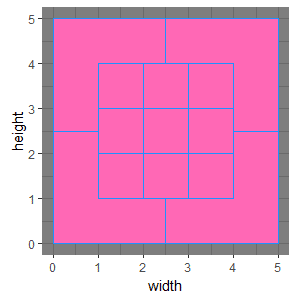
座標テーブルと成績テーブルのマージ
一旦整理しましょう。ここまでで以下のテーブルを作成しています。
ゾーン別成績を集計したテーブル (13行)
ゾーンの頂点を格納したテーブル (60行)
ゾーンのテキスト表示位置を格納したテーブル (13行)
下準備の最後のステップとして、2, 3のテーブルに1をマージして、座標データにスタッツが結びつけられた形にしておきます。テーブルのマージには、dplyr::left_join()が便利です。すべてのテーブルにzone列が共通しているので、これをキーにします。
positions <- positions %>%
dplyr::left_join(woba_table, by = "zone")
text_position <- text_position %>%
left_join(woba_table, by = "zone")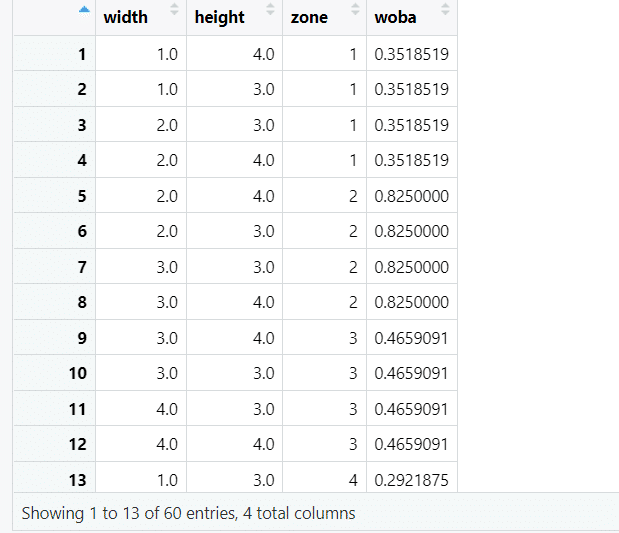

これで準備は完成です。
5. 描く
描きます。ggplotの基本的な記法についてここでは割愛しますが、書籍の山にもネットの海にも明快な解説がゴロゴロ転がっているので問題ないでしょう。横軸・縦軸にはpositionsテーブルの座標データを渡したうえで、group = zone を指定しておきます。塗りつぶしの濃淡でwOBAを表現したいので、woba列はfill = に突っ込んで下さい。
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = woba) +
geom_polygon(colour = "black")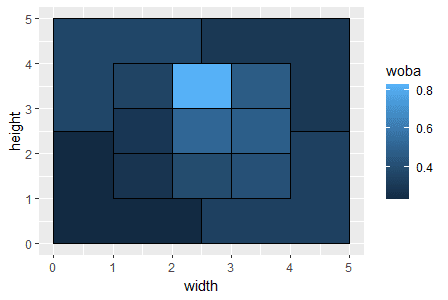
塗り潰しができました。ベース上のインコース、特に真ん中から高めのゾーンへの強さが伺えます。が、このままだと正直色合いが分かりにくいので、どの値にどの色を割り当てるか、詳細な設定を行っていきましょう。scale_fill_gradientn 関数で塗り潰し色の詳細設定ができます。wOBAはその平均がほぼ出塁率に等しくなるようデザインされているので、ざっくり.320を基準に、それより高いか低いかで塗分けをやっておきましょう。カラースケールはscales::rescale 関数を用いて、
まあ流派があると思いますが、Baseball Savant様の赤-青スケールに異常対抗してできるだけ目にやさしめのカラーリングを選択します。詳細は以下。
ついでにグラフの詳細もいじっちゃいましょう。繰り返しになりますが、今回は頂点座標の絶対的な値には意味がないので目盛りはなくても構いません。従って、背景の目盛り線も消してしまった方が見やすいと思います。
value_min <- text_position$woba %>% min()
value_max <- text_position$woba %>% max()
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = woba) +
geom_polygon(colour = "black") +
scale_fill_gradientn(
colours = c("navy", "white", "maroon"),
values = scales::rescale(c(value_min, .320, value_max))
) +
theme_classic() +
guides(x = "none", y = "none") +
coord_fixed() +
labs(x = "", y = "")
色覚多様性に配慮するのであれば、viridis パッケージのscale_fill_viridis_c関数を利用しましょう。平均に当たる部分の表現が難しいのでその意味では情報量が落ちますが、「見やすい」が指す意味がどこにあるのかに応じて使い分けるといいと思います。
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = woba) +
geom_polygon(colour = "black") +
scale_fill_viridis_c(
values = scales::rescale(c(value_min, .320, value_max)),
option = "C"
) +
theme_classic() +
guides(x = "none", y = "none") +
coord_fixed() +
labs(x = "", y = "")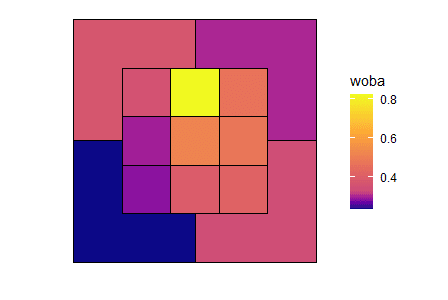
うぇい。さらに、wOBAの実数値を加えたラベルを貼り付ければ、配色を説明する凡例は必要ないかもしれませんね。geom_label()関数を使うと、それぞれのゾーンにwOBAを加えることができます。有効数字を3桁に揃えたいので、format関数やらなんやらを用いて形式を整えます。使用するデータフレームが異なるので、オプションinherit.aes = F を忘れずに追加して下さい。
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = woba) +
geom_polygon(colour = "black") +
scale_fill_gradientn(
colours = c("navy", "white", "maroon"),
values = scales::rescale(c(value_min, .320, value_max))
) +
geom_label(
data = text_position, aes(x = width, y = height, label = woba %>% format(., digits = 3, nsmall = 3) %>% str_extract("([1-9]|)\\.[[:digit:]]{3}")),
inherit.aes = F
) +
guides(x = "none", y = "none", fill = "none") +
coord_fixed() +
labs(x = "", y = "")
あるとかわいいので、ホームベースちゃんも描いちゃいましょう。ゾーンの領域と同様、homebaseというオブジェクトに頂点5つの情報を追加したデータフレームを定義し、geom_polygonで追加します。こちらもinherit.aesを忘れずに。
homebase <- tribble(
~ width, ~ height,
1.3, -.2,
1, -1,
2.5, -1.5,
4, -1,
3.7, -.2
)
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = woba) +
geom_polygon(colour = "black") +
scale_fill_gradientn(
colours = c("navy", "white", "maroon"),
values = scales::rescale(c(value_min, .320, value_max))
) +
geom_label(
data = text_position, aes(x = width, y = height, label = woba %>% format(., digits = 3, nsmall = 3) %>% str_extract("([1-9]|)\\.[[:digit:]]{3}")),
inherit.aes = F
) +
geom_polygon(aes(x = width, y = height), data = homebase, inherit.aes = F, colour = "black", fill = "white") +
theme_classic() +
guides(x = "none", y = "none", fill = "none") +
coord_fixed() +
labs(x = "", y = "")
真面目な話をすると、これがあるだけで捕手視点であることが分かるのでBenlligerです。
ということで完成です。最も値の低いアウトローの.230、最も高い.825にカラースケールの両端を設定しているので、それぞれ真っ青と真っ赤になるのはちょっとミスリーディングかもしれません。自らが作った可視化に踊らされないためにも、この辺のシステムは最低限理解した上で使用するようにしましょう。
同様に、投手のRVを描画。色塗りのmidpointを平均値であるゼロに設定するなど、ディテールはよしなにしておきましょう。ここまでの総まとめとして、コードを全部ぶん投げておきます。ただし座標プロットは省略。
df <- scrape_statcast_savant(
start_date = "2022-03-01",
end_date = "2022-11-30",
playerid = id,
player_type = "pitcher"
) %>% # パイプ演算子
filter(game_type == "R")
rv_table <- df %>%
group_by(zone) %>%
summarise(
N = n(),
RV = sum(delta_run_exp),
RV_100 = sum(delta_run_exp) / n() * 100
)
positions <- positions %>%
dplyr::left_join(rv_table, by = "zone")
text_position <- text_position %>%
left_join(rv_table, by = "zone")
value_min <- text_position$RV %>% min()
value_max <- text_position$RV %>% max()
ggplot(positions) +
aes(x = width, y = height, group = zone, fill = RV) +
geom_polygon(colour = "black") +
scale_fill_gradientn(
colours = c("navy", "white", "maroon"),
values = scales::rescale(c(value_min, 0, value_max))
) +
geom_label(
data = text_position, aes(x = width, y = height, label = RV %>% format(., digits = 2, nsmall = 2) %>% str_extract(".*([1-9]|)\\.[[:digit:]]{2}")),
inherit.aes = F
) +
geom_polygon(aes(x = width, y = height), data = homebase, inherit.aes = F, colour = "black", fill = "white") +
theme_classic() +
guides(x = "none", y = "none", fill = "none") +
coord_fixed() +
labs(x = "", y = "")
やっぱり球種別に表示した方がいいかもしれないですね。とかそういうのは頑張って下さい。
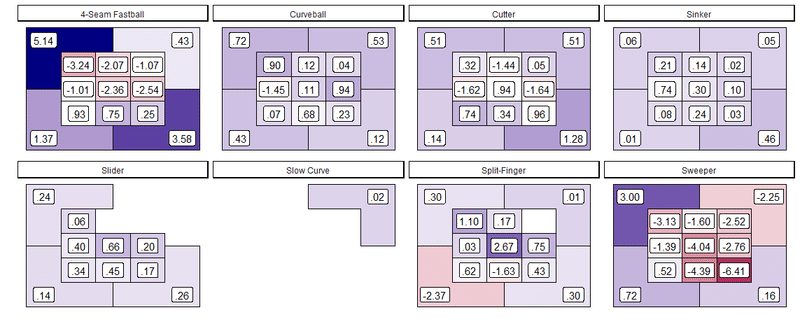
おわり
おわり。こんな長い文章をよく最後まで読んでいらっしゃるもんだと思いますよ、本当に。応用すれば野球以外のデータ分析にも使えるかもしれません。とりあえず誰かの役に立てば幸いです。面白かったら投げ銭なり不正献金なりスープカレーを奢るなりして下さい。
副業規制がようやく解けたのでなんでも言えるようになりました。助かりますね~。
おまけ:Excelでもやろう
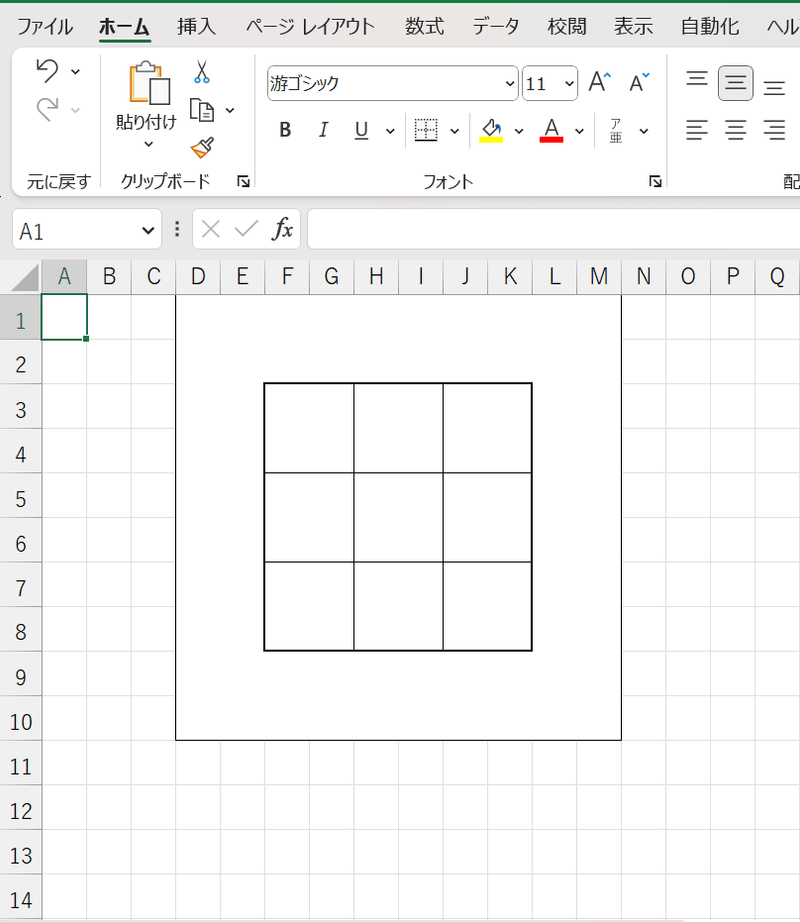
ここまで読んでから言うのもあれですが、特に5.のステップに関してはこだわりがないならExcelでやっちゃう方が早いかもしれません。
まず、画像のようにセルを結合・幅と高さを調整したセルを用意します。
ステップ4.で用いたゾーンごとの集計データを読み込み(csv形式で保存しておくと便利です)、適当なセルにコピーしておきます。というかわざわざRで計算する必要すらないです。全てはExcelで十分。

そのうえで、各セルの値は={セル番号}で指定可能なので、それぞれ対応するゾーンに参照するセルを指定すれば完成です。
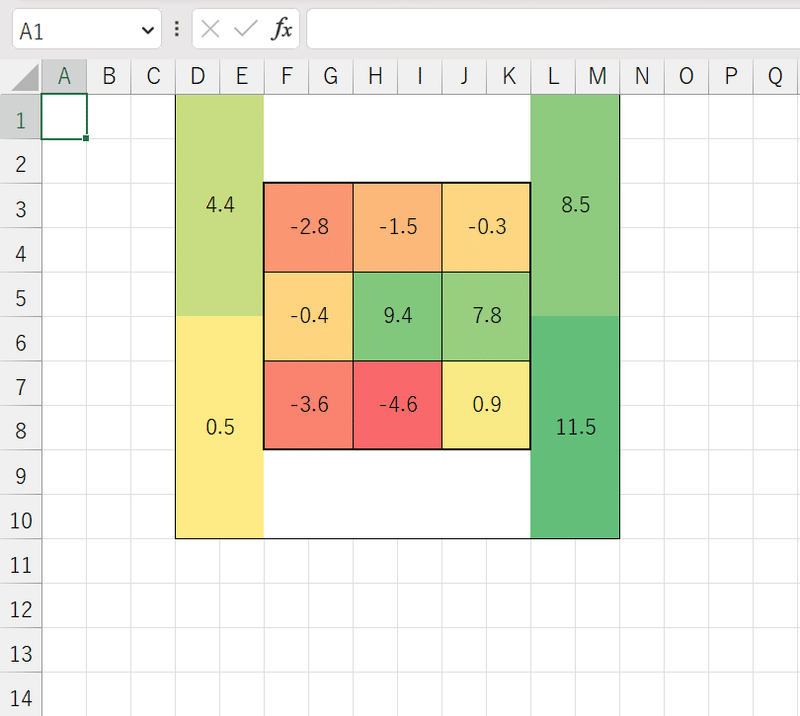
色の塗り分けは各設定していただければ。11-14のゾーンは2つのセルにまたがる塗りになるのでちょっと面倒ですが、条件付きのセルカラーを選択して、塗られた色をスポイトで抜いてくるなどすればまあまあゴリ押せるでしょう。セルの番号指定をそのままに、csvファイルのコピー先を同じ場所にすれば、wOBAやRVなど、様々なゾーン別スタッツを量産することも可能です。

以上です、困ったら手を動かして下さい。
おまけ2:曲を貼るコーナー
大サビの裏でそれまでなかったギターがきゅーんってなる曲好きなんですよね。最近は転調して雰囲気変える曲が多い気がしますが。ユニコーンの『鳥の特急便』もおすすめ。
貨幣の雨に打たれたい