
Excelで始まった人へ:Rでも始める投手分析

こんにちは。最近ノリでClubhouseを始めたTJです。2021年2月12日に書き始めたので今ぼくは華金を謳歌している真っ最中ですが、皆さんはいかがお過ごしでしょうか。暇で暇でしょうがない人は、このnoteのコメント欄にでもいかがお過ごしか書いて下さればぼくが読みます。人生相談はいつでも受け付けていますので、お気軽にぼくの悩みを聞いて下さい。
さて、今回のnoteは、Baseball Savantから入手できるデータを用いて投手分析の真似事をしていた以下の記事の焼き直しになります。Excelを使って投球の変化量をプロットするやつです。
このnoteも1年半前ですか。公開した(本当はこっそり前日に上げてた)日がたまたまお股ニキさんの第2作『なぜ日本人メジャーリーガーにはパ出身者が多いのか』の発売発表日と同日だったんですよね。
昨日黙って公開したnoteです!おうちでかんたんにできる投手アナライジング()の方法を紹介しています。おまけとしてダルビッシュ投手の持ち球に関するゆるふわ分析も掲載しているのでぜひ。
— TJ (@11_tjr) October 28, 2019
Excelで始めるMLB投手分析: 変化量グラフの作成|TJ @11_tjr #note https://t.co/HqLO0rRCou
ネットアシスタントとしてお手伝いをさせてもらったのがまるで昨日の出来事のようです(2021年2月11日ということになりますね)。ツイートの日がぼくの誕生日でもあるので今からでもお祝いしたいよーって方はぜひプレゼントを送って下さい。余談ですがT-岡田選手と奥田民生さんのファンです。
話を逸らしました。本題に戻りましょう。要するに今回のnoteはこの1年半前のものと全く同じことをやる、ということになります。前回は手動でデータをダウンロード、これをxlsxファイルに変換してExcelで散布図にする、という手法を使っていましたが、今回はぼく自身が実際に分析を行う際に利用している統計ソフト「R」を用いて作る方法です。
前回のnoteを公開した当時は高校の情報の授業でも教わるExcelを使った方が実践するのも容易だなという印象で、実際公開後は多くの方に再現したものをツイートして頂いたりもしました(この場を借りて(貸したのはぼくです)御礼申し上げます)。しかし、公開から1年半経った現在は、お股ニキさんの著書やBaseball Geeksさんなど投手の球質に着目して分析を行うメディアの発展や、Rapsodo等のポータブル測定機器で取得したデータを自ら公開・解説する現役選手による認知度向上の影響もあって、トラッキングデータを用いた分析がかなりポピュラーになってきました。特にTsuyuzakiさん、Nishiwakiさんによる 'Analyzing Baseball Data with R' (by Max Marchi, Jim Albert, Max Marchi, Jim Albert, Benjamin S. Baumer) の邦訳版の発売はR(やPythonなどその他の統計ソフト)による分析ブームに決定的な影響を与えたと感じています(なにさま)。
前回のnoteを活用して頂いた皆さんに今必要なのは、Excelを使った直感的な操作による再現ではなく、プログラムベースで再現が容易なコードの共有なのではないか!私はそう考えたわけです(握った拳で力強く机を叩く音)。
今回は特に前置きが長いですね。こんな振りかぶって書く内容でもない気がするのでとっとと本題に入りましょう。
余談ですが、Excelってマスターしようと思ったらめちゃくちゃ大変らしいです。VBAとか使う方はそれだけでデータの取得から分析、結果の出力まで一気にやれちゃうという話を聞きました。お股本制作で大変お世話になったaozoraさんもExcelでデータ取得をやられていると聞きました。すげえ~。何が言いたいかっていうと、「Excelの方が簡単」なのではなく「TJがExcelを使いこなせていないのでカンタンナコトしかできない」ということです。
手順
まずは手順の確認。変化量プロットを作る、というか分析全般をやるために必要なのは
1. データの取得
2. データの整理
3. データの可視化
4. 結果の出力
の4つ。実際には前後にもう少しステップがありますが、とりあえずここをやれば結果を報告できます。今回は準備段階として(ちょっとだけ)Rの基本操作についても書きたいと思います。
0. Rの基本操作・パッケージの準備
まずはRのインストール。Pythonもそうですが、このソフトのつよいところは無料で利用できる点ですよね。下記サイトからダウンロードできます。
『Rによるセイバーメトリクス入門』にも詳細が記述されているのでここでは省きますが、Rを使った分析にはR Studioのインストールも不可欠です。このnoteで紹介する再現も基本的にはR Studioで行ったものを掲載しています。
基本操作と書きましたが、まあ細かいところはGoogleしてもらうのが早いでしょう。インストールとRスクリプトの作成・関数の利用やコード作成などが済んだら、次にやるのはパッケージのインストール。今回はbaseballrパッケージとtidyverseパッケージがインストールできれば紹介した操作が再現できるはずです。
install.packages('tidyverse')tidyverseパッケージはinstall.package()を用いてCRANから簡単にインストールできます。baseballrパッケージはGithubからインストールするのでもう2,3ステップありますが、まあなんとかなると思います。
install.packages("devtools")
devtools::install_github("BillPetti/baseballr")詳細はBill Petti氏のGithubを参照してもらうのが一番ですが、まずGithubからパッケージをインストールするためのパッケージ:devtoolsをインストール→devtoolsに含まれる関数install_githubを利用してbaseballrをインストールするという手順です。割とこの手順でエラーが出る印象で、baseballrに付随してインストールするパッケージの更新が上手くいかないことがよくあるのですが、"○○のアップデートに失敗しました"みたいなエラーメッセージが出たら、そのパッケージをinstall.packages('○○')で直接インストールし直してから再度やり直せばなんとかなります。これで説明になっているんでしょうか。
1. トラッキングデータの取得
パッケージがインストールできたら、いよいよトラッキングデータを取得していきます。baseballrを利用して簡単にダウンロードできますが、上手くいかない場合は前回のnoteで紹介した、Baseball Savantから直接csvファイルをダウンロード→データフレームとして読み込みの方法でももちろん大丈夫です。
df <- readr::read_csv('ダウンロードしたcsvファイルの名前.csv')読み込んだデータをdfの形で定義する方法の一例です。dfは任意の文字列で大丈夫ですが、このあたりの記述のルールはR-Tipsに全部書いてあるので適宜ご参照下さい。
で、メインはbaseballrを使った方法。library(baseballr)でパッケージを展開すると、scrape_statcast_savant()という関数が使えるようになります。
scrape_statcast_savant(
start_date = '2020-03-01', end_date = '2020-11-30',
player_type = "pitcher", playerid = 12345
)上の関数だけで、Baseball Savantに行ってデータを検索してcsvに保存して読み込んで…までが一発でできてしまいます。すげえ。
オプションは4つ指定すればOKで、'start_date'と'end_date'には必要なデータの期間を入力します。3月1日から11月30日まで入れておけばどの年度でもそのシーズン全てのデータを確実に取得できるので、ぼくは基本的にはこの期間に設定しておくことが多いです。playerid=に選手固有のIDを指定し、player_type=に'pitcher' 'batter'のいずれかを入れると、該当する選手が投手/打者としてプレーした投球のデータが出力されるという仕組みです。playeridに何も指定しないまま実行すると、同期間中の投球が全て出力されます。が、どうやら一度に取得できる投球数の上限が決まっていてあまりに長期間だとデータの脱漏が出てしまうようなので、例えばシーズンの全投球がほしいという場合には、1日ごとに取得を行うことをおススメします。
playeridに入力する選手固有のIDもbaseballrパッケージに含まれるplayerid_lookup関数を使って確認できます。
playerid_lookup(last_name, first_name)例えば前田健太投手なら、playerid_lookup("Maeda", "Kenta")と入力すると次のような出力が得られます。クオーテーション" "を入力するのをお忘れなく。

1988年生まれのパチパチ世代、間違いなくツインズの前田健太投手ですね。同姓同名の選手・関係者がいると複数行結果が表示されることもあるので、mlb_played_first(デビューしたシーズン)等で判別して下さい。表示されている列の一番右側、'mlbam_id'に入っている'628317'が、前田投手のIDになっているので、
player <- scrape_statcast_savant(
start_date = '2020-03-01', end_date = '2020-11-30',
player_type = "pitcher", playerid = 628317
)と入力すれば「2020年3月1日から2020年11月30日までの期間中、Kenta Maeda投手が投手として登板時に記録された投球データが取得される」ということになります。以降では結果をplayerというオブジェクトに代入しておきます。
取得したデータをRStudioで見るとこんな感じになります。
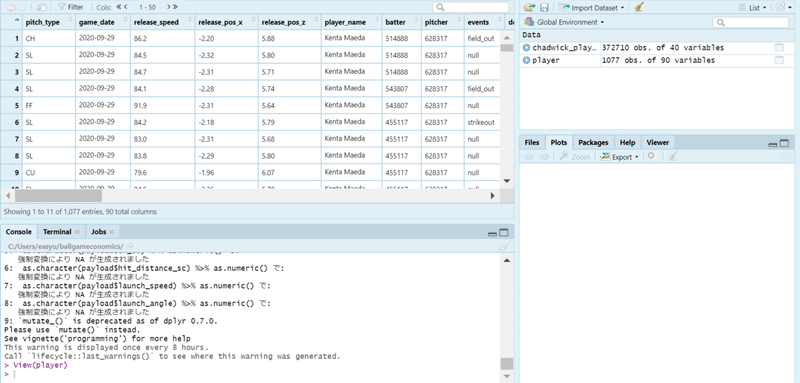
playerid_lookup関数を使用した時に得られるchadwick_playerid_lu_tableというデータフレームは、chadwick registerというデータソースを元に構築されています。MLBでプレーした全選手はもちろん、MLBの試合を裁いたことのある審判、MiLBの選手、さらにはNPBなど海外のプロリーグに至るまで、世界の主要なプロリーグの現場に携わったほとんどの人物が、Baseball ReferenceやFangraphsなどのサイトにおける固有IDと紐づけて記録されているというとんでもないデータです。個人的に本業でめちゃくちゃお世話になっています。
2. 必要な情報の整理
必要なトラッキングデータを取得したら、次はデータの整理を行います。前回同様、必要なのは球種と変化量に関するデータなので、90列あるデータフレームからこれらを抜き出してきます。
データの整理に役立つのがtidyverseパッケージ。library(tidyverse)を実行するとデータの成形に関する様々な関数を利用できるようになります。これも『Rによる~』に詳細が記入されているので、ここでは必要最低限の要素を説明するにとどめます。
パイプ演算子%>%を使用すると、特定のオブジェクトに対して複数の関数による操作を連続して記入できるので、今回はこれを利用します。
・列の取り出し
まずはデータから必要な列を取り出します。特定の列の抜き出しはselect関数を利用して簡単に行うことができます。selectの中に必要な列名、あるいは該当する列番号を列挙していけばOK。今回必要な球種はpitch_name(pitch_type)、横変化量がpfx_x、縦変化量はpfx_z列に格納されているので、これを取り出します。
player <- player %>%
dplyr::select(pitch_name, pfx_x, pfx_z)改めてplayerを開いてみましょう。90列あったデータフレームが3行だけになっているはずです。
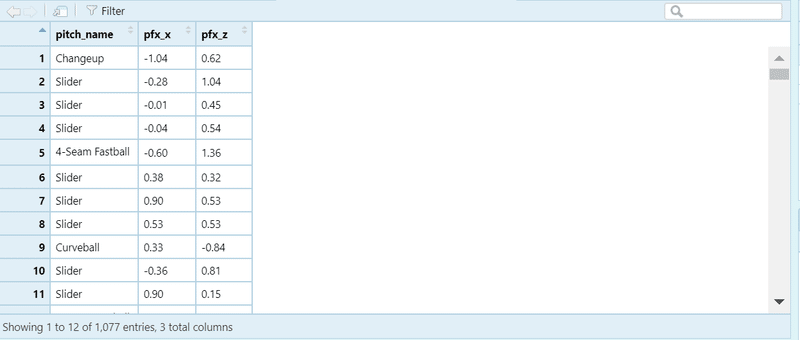
・行の取り出し
今回は前田投手が投げた2020年の全投球を対象にしますが、例えばシーズン中の変化を見るために特定の月のデータが必要になったり、打者の左右で変化量が変わっているかを確認したくなる時もあるでしょう。そういう場合にはfilter関数が便利です。filter()の中に検索条件(○月×日以前、左打者のみ…)を指定することで、これに合致する行だけを抜き出してくれます。先ほどの例では変化量と球種しか抜き出していないので、ここでは打席(stand)列と日付(game_date)の列も加えた上で、8月以降の対左打者の投球だけを使う例を記述します。条件指定に関する書式のルールも前述のR-Tipsあたりを参照して頂ければだいたい把握できるかと思います。
player %>%
dplyr::select(pitch_name, pfx_x, pfx_z, game_date, stand) %>%
dplyr::filter(stand == 'L' & game_date >= '2020-08-01')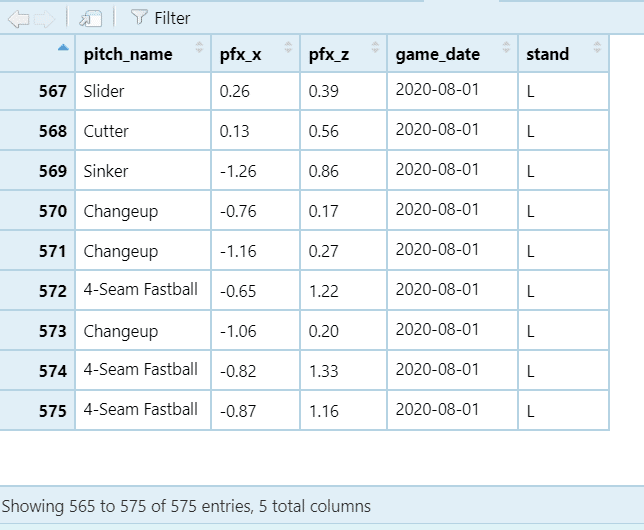
selectとfilterを連続して適用した結果、選んだ列だけ抜き出す+条件に合う行だけ抜き出す、という2つの操作をいっぺんにやった結果が出力されます。あとは申告敬遠の導入で一気に減りましたが、Pitchout(ウエスト)だったり、Intentional Ballを削除するのにもよく使います。
・新しい列の定義
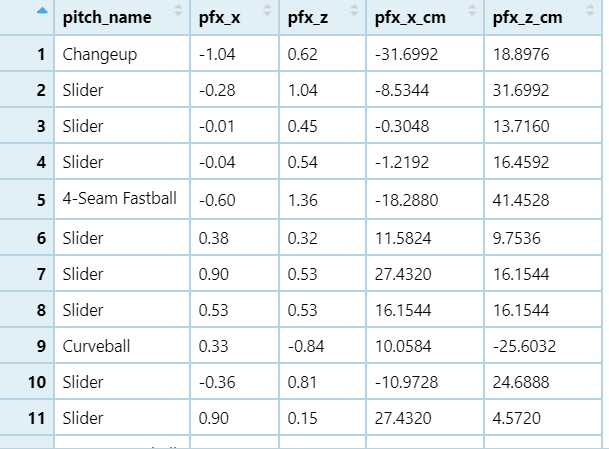
最後に新しい列の作成です。変化量の値ははフィート表示で格納されていますが、我々日本人にとってはcmの方が認知しやすいと思われるので、縦、横それぞれの変化量に30.48を掛けてcm換算したものを新しい列pfx_x_cm, pfx_z_cmを作成しましょう。mutate関数を使うことで、簡単に新しい列を定義することができます。
player <- player %>%
dplyr::select(pitch_name, pfx_x, pfx_z) %>%
dplyr::mutate(
pfx_x_cm = pfx_x * 30.48,
pfx_z_cm = pfx_z * 30.48,
)*は掛け算を表す記号です。「pfx_x列の値に30.48を掛けた値をpfx_x_cm列に格納しろ」という命令になります。出力は以下の通り。
・その他
この他によく利用する関数は、特定の条件にあてはまるかどうかを判定してくれるif_else()とこれを複数条件について行うcase_when、数値として記録されていない列を無理やり数値化するparse_number()などが役に立ちます。これらをmutate関数と組み合わせれば、例えば球種をFastball, Breaking, Offspeedに再分類するなど、自分がやりたい分析を行うためのデータの変形を行うことが可能になります。
特にデバイスがトラックマンからホークアイに替わった2020年以降は、球種別wOBAなどを計算する時に使うwoba_value、iso_valueなどの列の空欄がNAではなく'null'という文字列に置き換えられているため、parse_numberを非常に重宝しました。
3. データの可視化
データの成形が終わったところで、いよいよ分析に入ります。煩雑化を避けるため、操作の結果(select, filter)をplayerというオブジェクトに代入して説明していきます。
図形の描画にはggplot2パッケージを使います。これは「線を引く」「点を打つ」「タイトルを記入する」といった作業に対応した複数の関数を+でつなげていくことで、まっさらなキャンパスの上に重ね書きをしていくような感覚で描画をする関数になっています。画像を使いながら説明していきましょう。
・土台の作成
まずはどのデータを使うのか、x軸とy軸にはどの列が入るのかを宣言します。ggplot関数を使ってdata =に使用するデータフレーム、mapping = aes()の中に使用する列を入力してコードを実行すると、まずはまっさらなキャンバスが現れます。
ggplot2::ggplot(data = player, mapping = aes(x=pfx_x_cm, y=pfx_z_cm))
出力されたグラフには何も入力されていませんが、横軸が横変化量(cm)、縦軸が縦変化量に対応していることは明らかになっていて、軸の範囲も-50~50cmと、変化量が入りそうな領域に調整されています。
・軸を描画する
今回行うのは変化量の作成なので、縦横それぞれゼロのところに線を引いておくと見やすそうです。先ほどのggplot関数の後ろにgeom_hline、geom_vline関数をプラスすると、任意の場所に縦線・横線を描くことができます。
ggplot2::ggplot(player,aes(x=pfx_x_cm, y=pfx_z_cm)) +
ggplot2::geom_hline(yintercept = 0) + ggplot2::geom_vline(xintercept = 0)
・散布図の描画
いよいよ変化量のプロットを描画していきます。散布図を加えるためには、geom_point関数を利用します。単にgeom_point()とだけ加えても良いのですが、今回は球種によって色分けをしたいので、aes()の中に(color = pitch_name)というオプションを指定しておきます。これは「pitch_nameの中身によって色分けしてね」という命令です。また、プロットに重なりがあった時に分かりやすいよう、透明度を0.7(0-1で不透明に)に設定します。
ggplot2::ggplot(player,aes(x=pfx_x_cm, y=pfx_z_cm)) +
ggplot2::geom_hline(yintercept = 0) + ggplot2::geom_vline(xintercept = 0) +
ggplot2::geom_point(aes(colour=pitch_name), alpha = .7)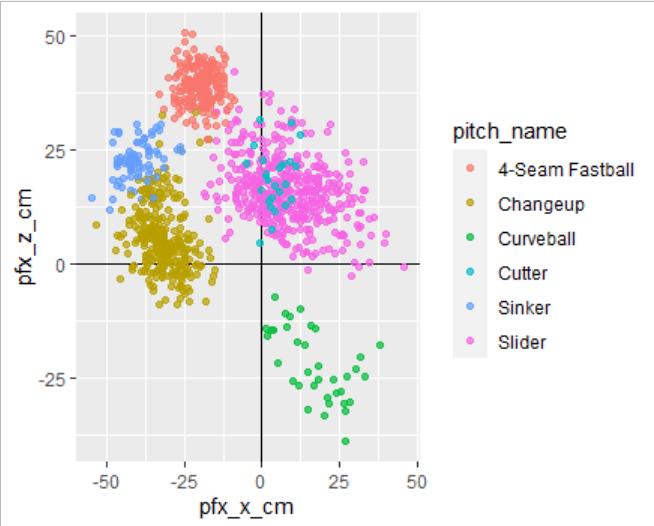
できました。やったね。右の凡例は自動で加えてくれます。
・体裁を整える
一応ここまでで完成ですが、せっかくなので表の体裁を整えましょう。Excelでは表のオプション等を用いて直感的に調整を行っていましたが、Rの場合はこれをいちいちコードで書いてやる必要があります。
まずは表のテーマ変更。theme_○○で様々な様式を利用することができます。TJが好んで用いているのはtheme_bwです。
ggplot2::ggplot(player,aes(x=pfx_x_cm, y=pfx_z_cm)) +
ggplot2::geom_hline(yintercept = 0) + ggplot2::geom_vline(xintercept = 0) +
ggplot2::geom_point(aes(colour=pitch_name), alpha = .7) +
ggplot2::theme_bw()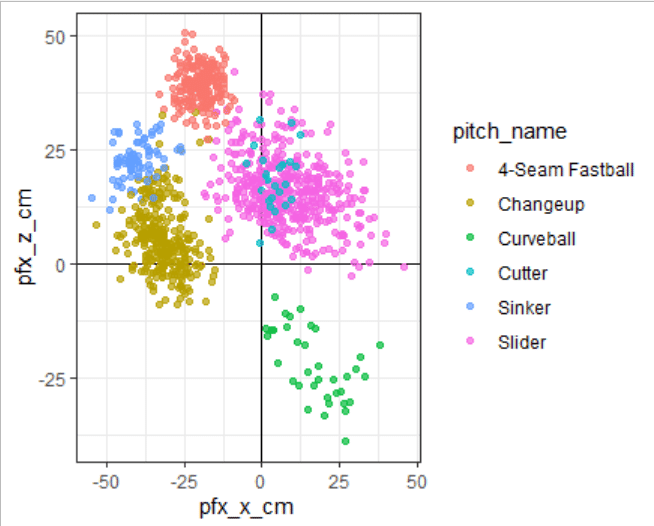
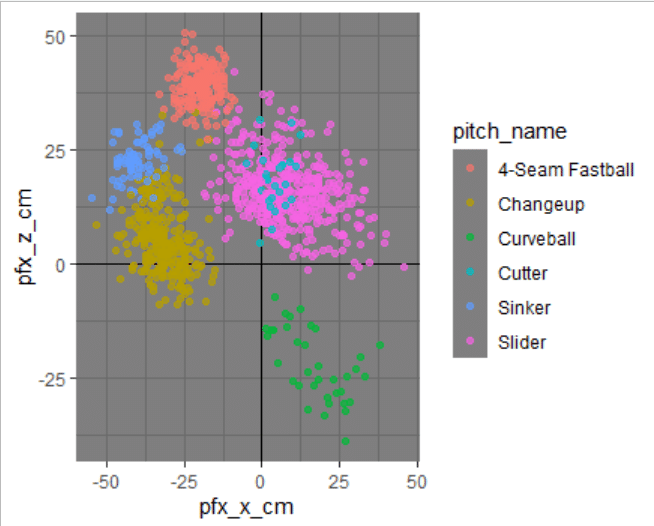
中学生、特に2年生におすすめの様式はtheme_dark()。見えないものを見ようとしているのが楽しい時期、ありますよね(は?)。見えてるものを見えなくしているのは他ならぬ自分自身だった、ということが多々あります。
面倒な線は引くな、とにかく白く!という方はtheme_testやtheme_classic。
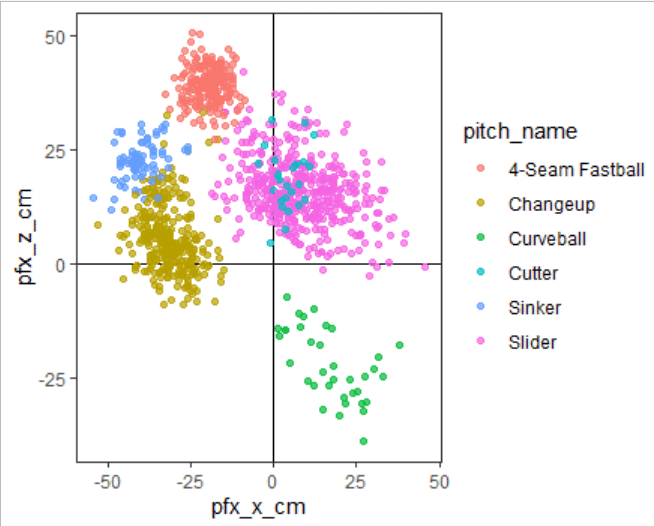
様式を保存したパッケージもあるので、こだわりたい方は調べてみて下さい。とりあえず様式に関してはこのぐらいで。
次に設定するのはラベルです。軸ラベルやタイトル、キャプションや凡例のラベルはlabs関数で設定できます。x =にはx軸、title=にはタイトル…といった具合です。こちらもクオーテーションを忘れずに付けて下さい。
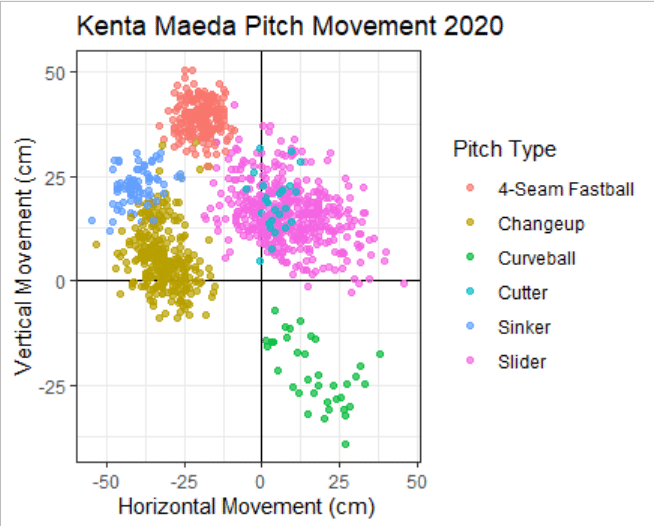
完成です。前田投手のスライダーが非常に広い変化量を持っている:横に大きく滑るスライダーや高速で縦に落とすスラットライクなボールを打者に応じて使い分けているということがはっきり分かりますね。また、チェンジアップにはドロップ成分を含むものも多く、ジャイロ回転を利用してフォーシームと横成分の差が小さい=縦に大きく落ちるスプリットチェンジを実現していることが分かります。
スライダーとカッターを打者の左右で分けるとこんな感じ。
player2 <- player %>%
dplyr::select(pitch_name, pfx_x, pfx_z, stand) %>%
filter(pitch_name %in% c('Slider', 'Cutter')) %>%
dplyr::mutate(
pfx_x_cm = pfx_x * 30.48,
pfx_z_cm = pfx_z * 30.48,
)
ggplot2::ggplot(player2, aes(x=pfx_x_cm, y=pfx_z_cm)) +
ggplot2::geom_hline(yintercept = 0) + ggplot2::geom_vline(xintercept = 0) +
ggplot2::geom_point(aes(colour=stand), alpha = .7) +
ggplot2::theme_bw() +
ggplot2::labs(
title = 'Kenta Maeda Pitch Movement 2020',
x = 'Horizontal Movement (cm)', y = 'Vertical Movement (cm)', colour = "Batter Dexterity"
)
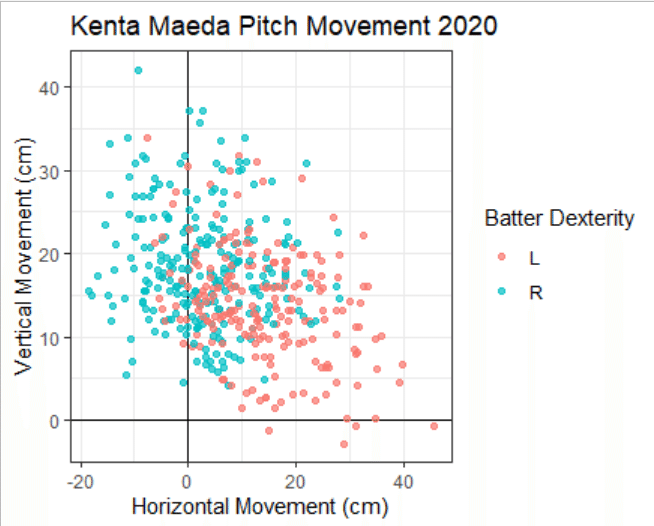
赤が左打者、青が右打者に対する変化量になっています。対左打者の方が比較的大きなスライダー(カッター)を投げているんですね。インコースに食い込ませることになるのでこれはちょっと意外でした。前田投手の切れ味鋭いバックフットスライダーが繊細なコマンドに支えられていたことが明らかになる可視化ですね。
最後に軸の範囲の設定方法です。xlim()、ylim()を使うことで、グラフの範囲を自由に変更することができます。複数投手や年度間の比較をしたい場合に有用なツールです。
ggplot2::ggplot(player,aes(x=pfx_x_cm, y=pfx_z_cm)) +
ggplot2::geom_hline(yintercept = 0) + ggplot2::geom_vline(xintercept = 0) +
ggplot2::geom_point(aes(colour=pitch_name), alpha = .7) +
ggplot2::theme_bw() +
ggplot2::labs(
title = 'Kenta Maeda Pitch Movement 2020',
x = 'Horizontal Movement (cm)', y = 'Vertical Movement (cm)', colour = "Pitch Type"
) +
ggplot2::xlim(-100, 100) + ggplot2::ylim(-100, 100)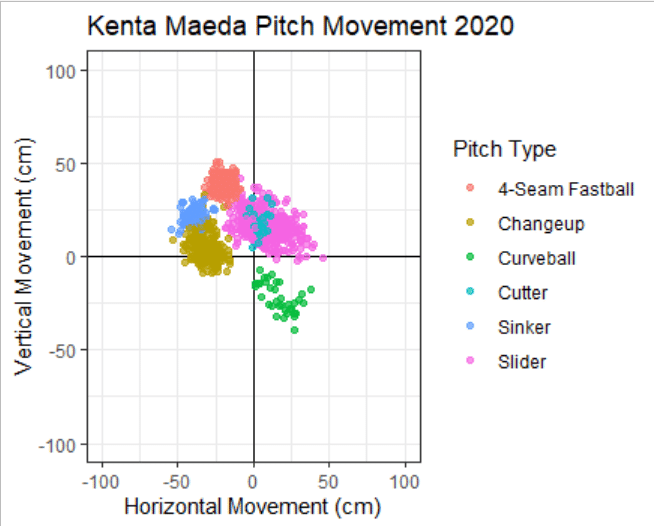
4. 結果の出力
最後に結果の出力です。ggplotで描画した結果を適当なオブジェクトに代入し、ggsave関数を使うことで作ったものを保存することができます。Twitterにぶん投げるもよし、noteで記事を書くのに使うもよし、インスタのストーリーに挙げて匂わせに使うもよし。
pl <- ggplot() + (略)
ggsave('ファイル名.png', pl)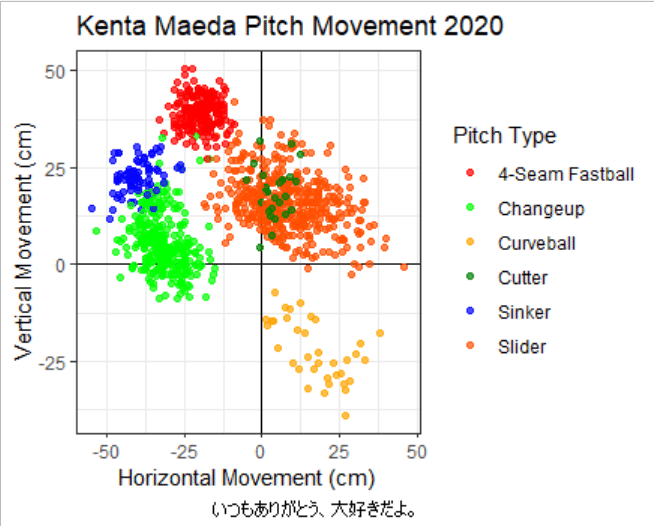
まとめ
今回は以上です。なっがいnoteにお付き合い頂き、ありがとうございました。気づいたら10,000字超えてました。コードブロックも字数にカウントされるので実際はもう少し常識的な数字に収まっているはずですが、人間の脳は10より大きな数を数えられないと聞いているので、どっちにしろ長い以外の感想を持った人はいないと思います。本noteがこれを必要とする一人でも多くの皆さんの目に留まることを願って今回の締めとさせて頂きます。
おまけ
ここにリンクを貼らないと終われないので貼らせて下さい。
去年の4月ぐらいから突然これにハマってゴールデンウィークあたりの時期に無限ループしてましたね。自粛期間の産物です。ブルージーな歌声で夜に聴くと落ち着くのでおすすめです。
おまけ②
曲とガチおまけの位置を逆にすることで曲を見せるという低級テクニックを覚えました。球種別成績の集計方法を紹介しようかと思います。こんなやつですね。

出力はcsv形式ですが、データの集計は基本的にRでやっています。まずはデータと必要な列選択をまとめて。
player <- baseballr::scrape_statcast_savant(
start_date = '2020-03-01', end_date = '2020-11-30',
player_type = "pitcher", playerid = 628317
) %>%
select(pitch_type, pfx_x, pfx_z, plate_x, plate_z, type,
description, release_speed, stand, release_spin_rate, pitch_name, zone,
events, description, launch_speed, bb_type, woba_value, woba_denom) %>%
filter(!(pitch_type %in% c("PO", "IN", "null"))) %>%
mutate(
pfx_x_cm = pfx_x * 30.48,
pfx_z_cm = pfx_z * 30.48,
release_speed_km = release_speed * 1.61,
woba_value = parse_number(woba_value),
woba_denom = parse_number(woba_denom),
)データフレームの集計にもtisyverseが活躍します。group_by関数とsummarize関数を使うことで、各指標の集計データを算出することができます。
pitchsum <- player %>%
dplyr::group_by(pitch_name) %>%
dplyr::summarise(number = n(), usage = round(100 * n() / nrow(player), 1),
speed = round(mean(release_speed_km), 1),
srate = round(mean(release_spin_rate, na.rm = T), 1),
hmov = round(mean(pfx_x_cm, na.rm = T), 1),
vmov = round(mean(pfx_z_cm, na.rm = T), 1),
Zone = round(sum(zone %in% 1:9)/n() * 100, 1),
SwStr = round(sum(description %in% swst) / n() * 100, 1),
Called = round(sum(description %in% calledstr) / n() * 100, 1),
Swing = round(sum(description %in% swing) / n() * 100, 1),
Contact = round(sum(description %in% contact) /
sum(description %in% swing, na.rm = T) * 100, 1),
GB = round(sum(bb_type == "ground_ball", na.rm = T) /
sum(!is.na(bb_type), na.rm = T) * 100, 1),
Hard = round(sum(launch_speed >= 95, na.rm = T) /
sum(!is.na(launch_speed), na.rm = T) * 100, 1),
wOBA = round(sum(woba_value, na.rm = T) / sum(woba_denom, na.rm = T), 3),
) %>%
dplyr::arrange(desc(number))空振りやスイングを表すdescription、eventは以下のように定義しているのですが、いちいち書くのはさすがに面倒なのでスクリプトに保存して毎回呼び出しています。きったないコードだなと思いますが、書き直さなくても動くからいいやと思って直さないままです。
ev <- c(
"batter_interference", "catcher_interf",
"caught_stealing_2b", "caught_stealing_3b",
"caught_stealing_home", "double",
"double_play", "field_error",
"field_out", "fielders_choice",
"fielders_choice_out", "force_out",
"grounded_into_double_play", "hit_by_pitch",
"home_run", "other_out",
"pickoff_1b", "pickoff_2b",
"pickoff_3b", "pickoff_caught_stealing_2b",
"pickoff_caught_stealing_3b", "pickoff_caught_stealing_home",
"run", "sac_bunt",
"sac_bunt_double_play", "sac_fly",
"sac_fly_double_play", "single",
"strikeout", "strikeout_double_play",
"triple", "triple_play",
"walk", 'interf_def',
NA
)
PAresult <- ev[c(1, 2, 6:16, 24:34)]
AtBat <- PAresult[c(3:10, 12, 13, 18:23)]
baseHit <- AtBat[c(1, 9, 11, 14)]
des <- c(
"ball", "blocked_ball", "bunt_foul_tip",
"called_strike", "foul", "foul_bunt",
"foul_pitchout", "foul_tip", "hit_by_pitch",
"hit_into_play", "hit_into_play_no_out", "hit_into_play_score",
"missed_bunt", "pitchout", "swinging_pitchout",
"swinging_strike", "swinging_strike_blocked"
)
strike <- des[c(3:8, 10:13, 15:17)]
calledstr <- des[c(4)]
swing <- des[c(3, 5:8, 10:13, 15:17)]
swst <- swing[c(8:11)]
foul <- swing[c(1, 2, 3)]
contact <- swing[c(1:8)]出来上がったデータテーブルをcsvに出力。完成品はこんな感じになります。

これに適当に色を付けて桁数を揃えれば完成。スライダーとチェンジアップで投球の70%近くを構成しているんですね。それでいてスライダーのContact%が60%台に収まっているのはさすがの一言。フォーシームとの縦変化量の差もしっかり確保していることが分かります。
ちなみに、wOBAの値はBaseball Savantの値と微妙にズレます。なぜかはよく分からないんですが、生データから球種の修正等で出る差なんでしょうか。他の方も指摘していたので、恐らくコードの問題によるものではないと思います。まあ球種間の大小関係は大きく変わらないので投手分析程度なら問題ない違いかなと認識していますが。
(おまけ終わり)
貨幣の雨に打たれたい