超簡単Pythonでアヤメ(Iris)分類(XGBoost 利用)機械学習

PythonでXGBoostを利用してアヤメ(Iris)分類を超簡単に機械学習
1. ツールインストール
$ pip install install scikit-learn xgboost2. ファイル作成
pred.py
from sklearn import datasets
from sklearn.model_selection import train_test_split
import xgboost as xgb
import numpy as np
from sklearn.metrics import precision_score
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.20, random_state=42
)
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
parameters = {
"eta": 0.3,
"objective": "multi:softprob", # error evaluation for multiclass tasks
"num_class": 3, # number of classes to predic
"max_depth": 3, # depth of the trees in the boosting process
}
num_round = 20 # the number of training iterations
bst = xgb.train(parameters, dtrain, num_round)
preds = bst.predict(dtest)
best_preds = np.asarray([np.argmax(line) for line in preds])
print(precision_score(y_test, best_preds, average="macro"))
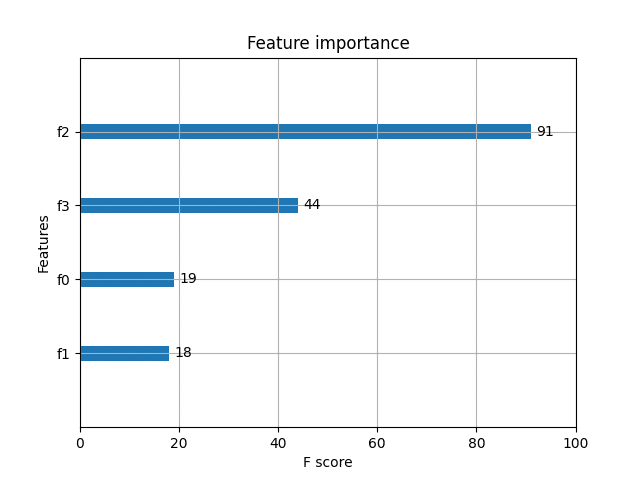
ax = xgb.plot_importance(bst)
ax.figure.savefig("fi.png")3. 実行
$ python pred.py
1.0fi.png
以上、超簡単!
4. 参考
この記事が気に入ったらサポートをしてみませんか?