
Amazon SageMaker Data Wrangler を試してみた

はじめに
機械学習のデータ準備ツール Amazon SageMaker Data Wrangler を実際に使用してみたので、利用方法と各機能について詳しくご紹介したいと思います。
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler(以下、Data Wrangler と記載する)は、機械学習において重要なデータ準備を簡素化および合理化してくれるサービスです。
データの探索、分析、変換といった処理を、サポートしてくれる様々な組み込み機能が提供されており、それらの機能をほとんどコードを使うことなく使用できる、機械学習のデータ準備に特化したローコードツールです。
Data Wrangler で作成したデータフローは、機械学習ワークフローへ統合することが可能となっています。
今回の検証内容
前回、Data Wrangler の概要と特徴についてご紹介させていただきました。
今回は、実際に Data Wrangler を使用して、各機能と操作性について検証を行っていきたいと思います。
行う作業は、公式デモに沿って「タイタニック号」のデータセットを使ったデータ準備を行います。
なお本ブログでは Data Wrangler セットアップの説明は割愛いたしますので、詳細を知りたい方は
Data Wrangler を使用してML データを準備するをご参照ください。
利用方法
Data Wrangler は、Amazon SageMaker Studio から利用可能となっています。
Amazon SageMaker Studio を起動し、Data 項目から [Data Wrangler] を選択し、 + Create Data Wrangler flow で 新規 flow を作成します。
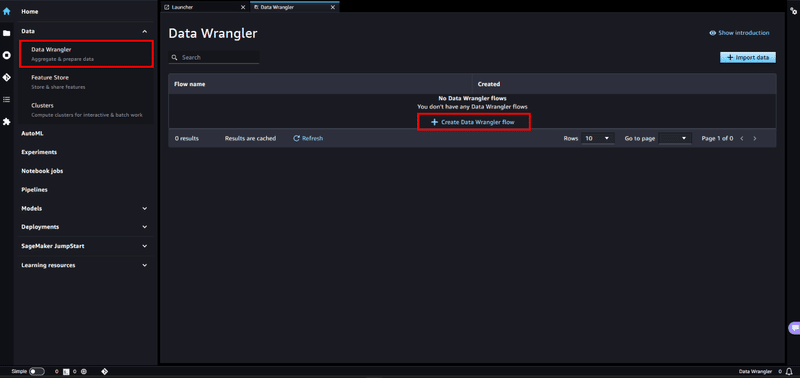
インスタンスが起動されるのでしばらく待ちます。(初めて起動には、約 5 分ほどかかる場合があります)
インポート
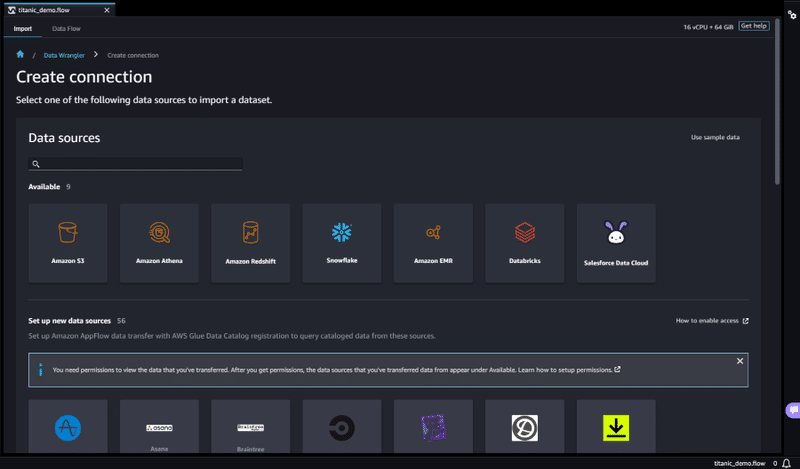
インスタンスが起動したら、まずはデータセットをインポートします。
Data Wrangler では、Amazon S3、Amazon Athena、Amazon Redshift、Snowflake など様々なソースにアクセスすることができます。
基本操作
Data Wrangler は、大きく 2 つのページで構成されています。
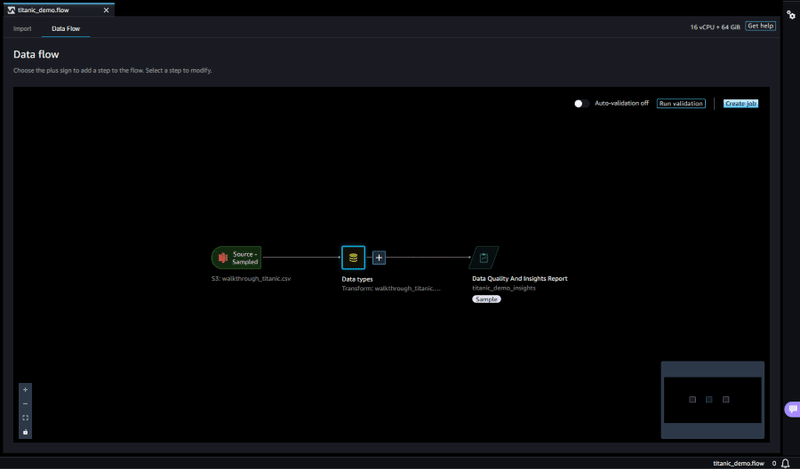
- Data Flow
データ処理手順を、俯瞰して確認することができる画面です。
+ボタンから様々な処理を追加することができます。
以下の写真のように、処理を追加していきデータフローを作成します。
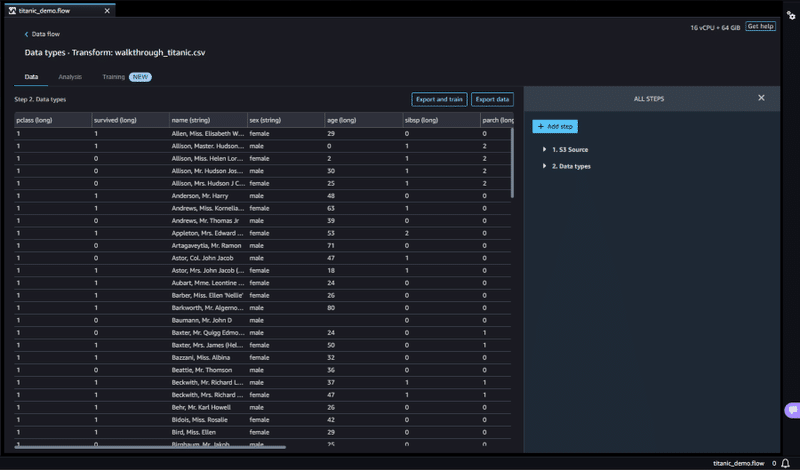
- Data Types
データ処理の詳細画面です。
[Data] [Analysis] [Training] タブで構成され、[変換] [分析] [トレーニング] に応じた機能が備わっています。
この画面からも処理の追加・確認を行うことが可能です。
今回は、「Data Types」ページから処理の追加を行い、「Data Flow」ページで手順の確認など行っていきたいと思います。
インサイトレポート
まずは、データに関する情報を確認するため、インサイトレポートを作成します。
AWS 開発者ガイドでは、データセットをインポートした後にインサイトレポートを作成することが勧められています。
インサイトレポートを作成すると、データ品質(欠損値、重複行、データ型など)を自動的に検証し、データの異常を検出するのに役立ちます。
インサイトレポートの作成は、「Data Types」ページの [Analysis] タブから行います。Analysis type のプルダウンから Data Quality And Insights Reportを選択し、予測を行う Target column と、Problem type を選びます。
(今回のデータでは、生存を表す列 survivedを Target column に選び、Problem Type は分類予測 Classification を選びます)
最後に Create ボタンを押してインサイトレポートを作成します。
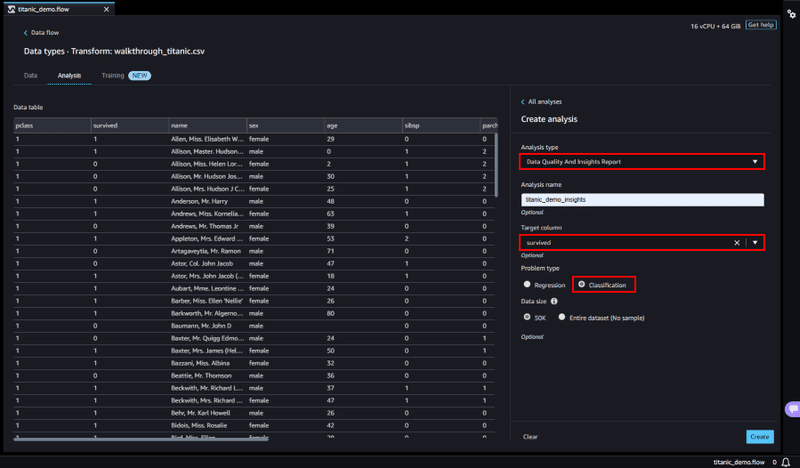
インサイトレポートでは、以下のような情報を確認できます。
SUMMARY
統計情報として、欠損値、無効な値、特徴タイプ、外れ値数など簡単な概要が記載されています。
重要度の高い問題が含まれる場合は、警告が表示されます。
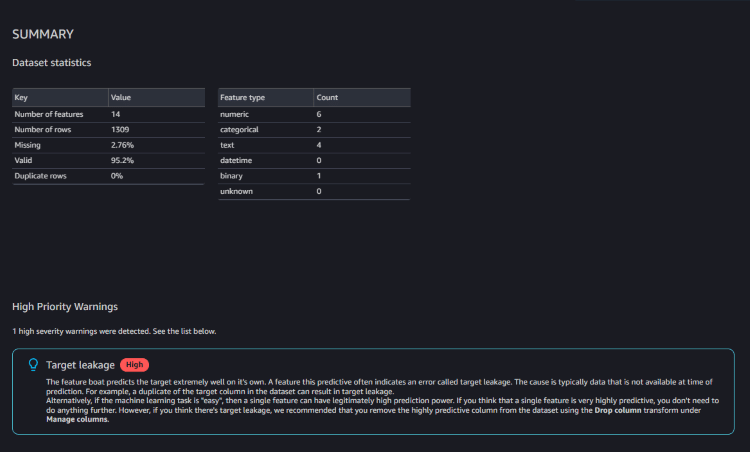
警告には、以下のような内容が書かれていました。
「boat」のように予測性の高いフィーチャーは、しばしばターゲットリークと呼ばれるエラーを示します。
ターゲットリークがあると思われる場合は、Manage columns(カラムの管理)のDrop column transform(カラムの削除)を使って、
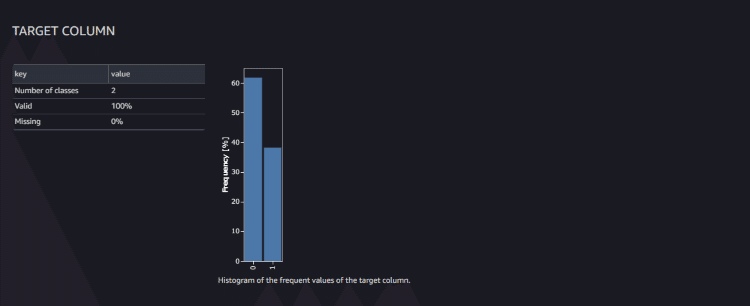
データセットから予測力の高いカラムを削除することをお勧めします。TARGET COLUMN
ターゲットに設定したカラムの分析が記載されます。
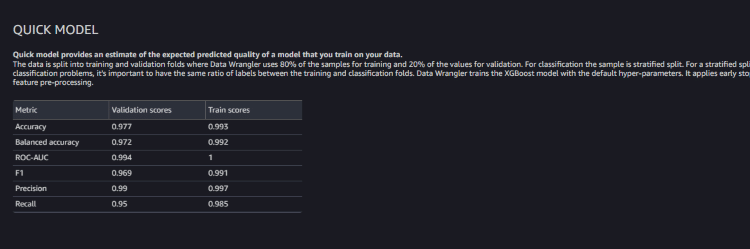
QUICK MODEL
データに基づいてトレーニングするモデルの予想品質が記載されます。
FEATURE SUMMARY
各特徴量の予測力(Prediction power)が記載されます。
スコア 1 は完全な予測能力を意味し、多くの場合、ターゲットの漏洩を示します。
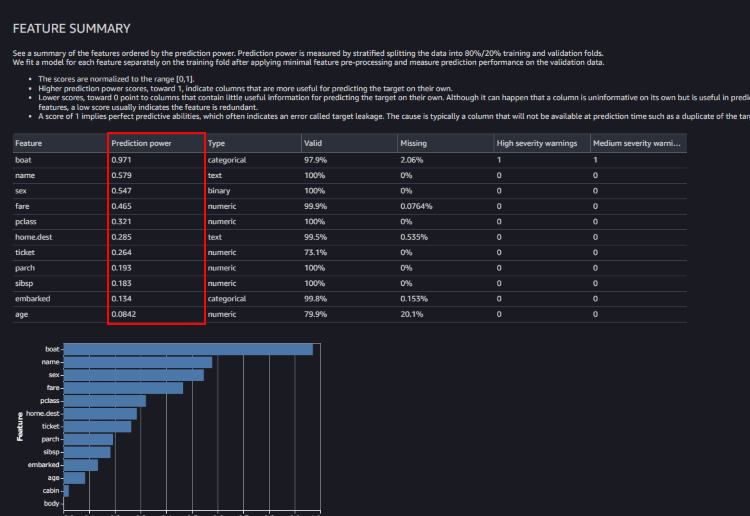
警告にもあったように、「boat」列はターゲットの漏洩を示しているようです。
このようにインサイトレポートを確認するだけで、様々な情報を確認することができます。
次は、このインサイトレポートを基に、データのクリーニングと変換を行っていきます。
データの変換
データの変換は、[Data] タブから + Add step ボタンを押すと ADD TRANSFORM が表示されます。
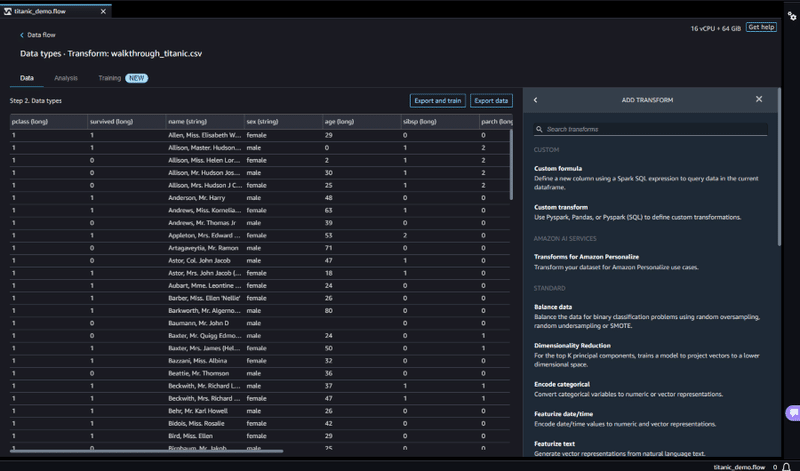
ADD TRANSFORM には、多数の組み込み変換機能が用意されており、ほとんどコードを使わずデータをクリーニング、変換することが可能です。
ADD TRANSFORM の詳細は、開発者ガイド「データの変換」をご確認ください。
カラムの削除
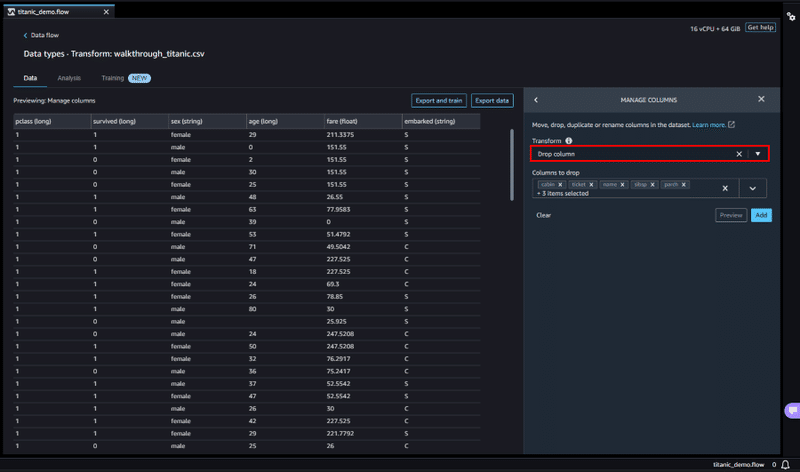
今回は、まずインサイトレポートの警告にもあったターゲットリークを解消するため、Manage columnsを選択し、不要なカラムを削除していきます。
Transform 項目から Drop Columnを選択し、Columns to drop に予測で使用したくないカラムを選択します。
選択後 Preview で確認を行い、カラムが削除されたことを確認し、Addボタンでデータ処理に追加します。
追加された処理は、以下の写真のように ALL STEPS 内に追加されていきます。
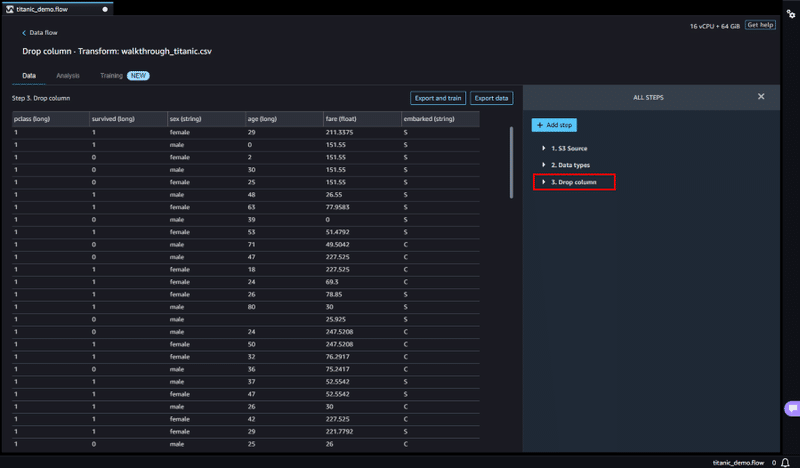
このようにして、データのクリーニング、データの変換に必要なデータ処理を追加していくことができます。
欠損値のクリーンアップ
次に、データ内にある欠損値をクリーンアップします。
Handle missing を選択し、Transform 項目から Drop missing を選択し、
Input columns に欠損値が含まれるカラムを選択して、欠損値が含まれる行を削除します。
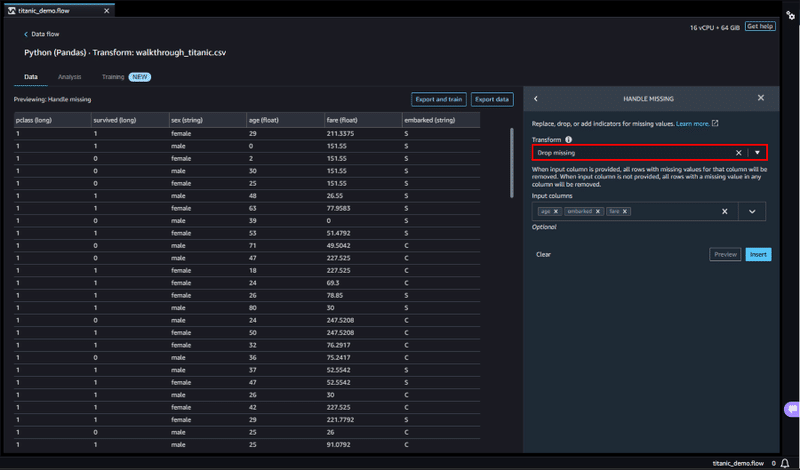
欠損値のクリーンアップ
次に、データ内にある欠損値をクリーンアップします。
カスタム変換
ADD TRANSFORM には、組み込み変換のほかにもカスタム変換が用意されており、カスタム変換を使用すると、Python (ユーザー定義関数)、PySpark、Pandas、または PySpark (SQL) を使用して定義することができます。
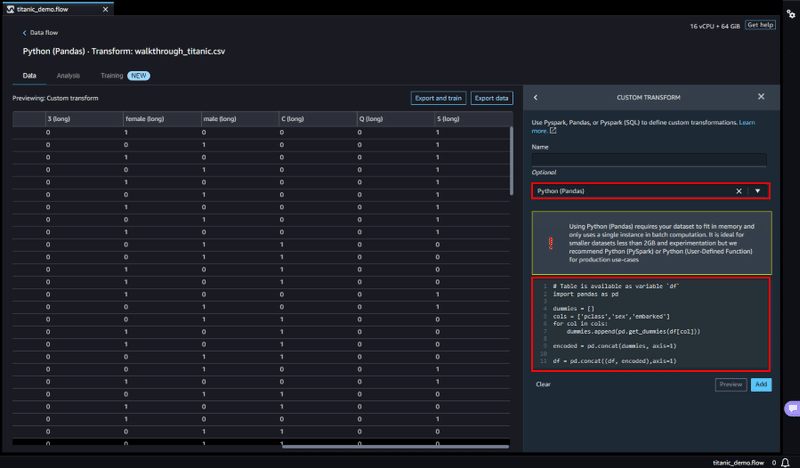
今回は Pandas を使用して、カテゴリカル変数をエンコードしていきます。
Custom transform を選択し、Optional 項目から Python (Pandas) を選択します。
コードボックスに、以下のコードを入力します。
import pandas as pd
dummies = []
cols = ['pclass','sex','embarked']
for col in cols:
dummies.append(pd.get_dummies(df[col]))
encoded = pd.concat(dummies, axis=1)
df = pd.concat((df, encoded),axis=1)これより、ダミー変数のカラムが追加され、カテゴリカル変数をバイナリ形式でエンコードすることができました。
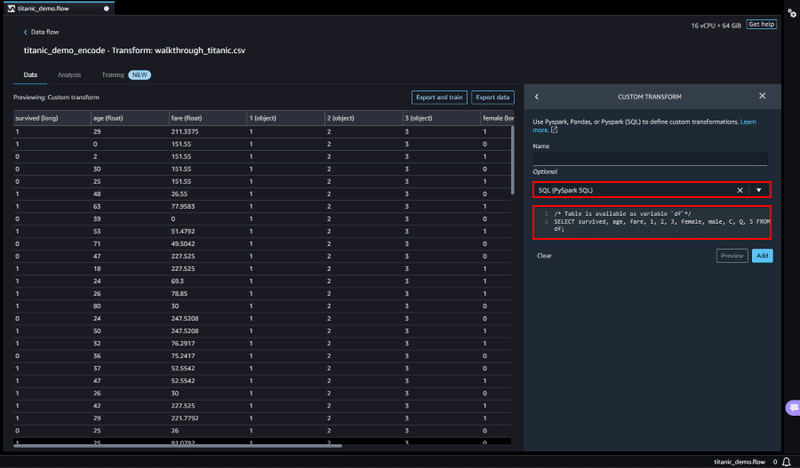
元のカテゴリカル変数は使用しないので、SQL を使用してカラムの選択する処理を追加します。
先ほど同様に Custom transform を選択し、Optional 項目から SQL (PySpark SQL) を選択し、コードボックスに、以下のコードを入力します。
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df;survived はトレーニングのターゲット列であるため、その列を最初に置きます。
使用するカラムがセレクトされているのが確認したら、Add ボタンで処理を追加します。
以上で、一通りのデータのクリーニング、変換が完了しました。
公式デモはこの後にエクスポートとなるのですが、今回はもう少し詳しくデータの分析を行いたいと思います。
データの分析
Data Wrangler では、インサイトレポートに加えて、より詳細な分析が行える組み込み分析機能が用意されています。
数回クリックするだけで、ヒストグラムや散布図といった形式で可視化し、データ分析を生成することができます。
ADD ANALYSIS の詳細は、開発者ガイド「分析と可視化」をご確認ください。
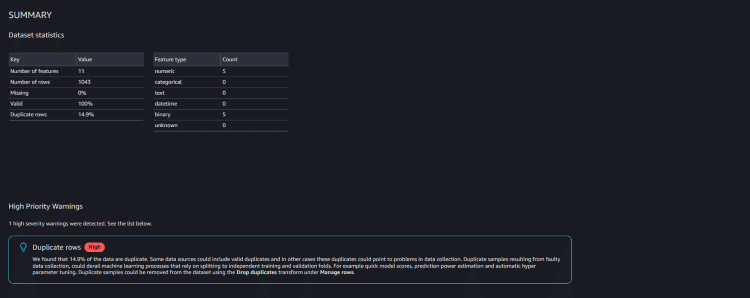
再度インサイトレポートを確認すると、「Duplicate rows」行の重複に関する警告が出ています。
このままのデータを使用してしまうと、モデルの評価に偏りが生じるほか、データの不均衡など引き起こす可能性があります。
「Data flow」ページの移り、SQL 処理横の + ボタンから Add analysis を選択しデータの詳しい分析を行います。
Analysis type 項目から Duplicate rows で重複行の確認を行うと、いくつかのデータで重複が生じているのが確認できました。
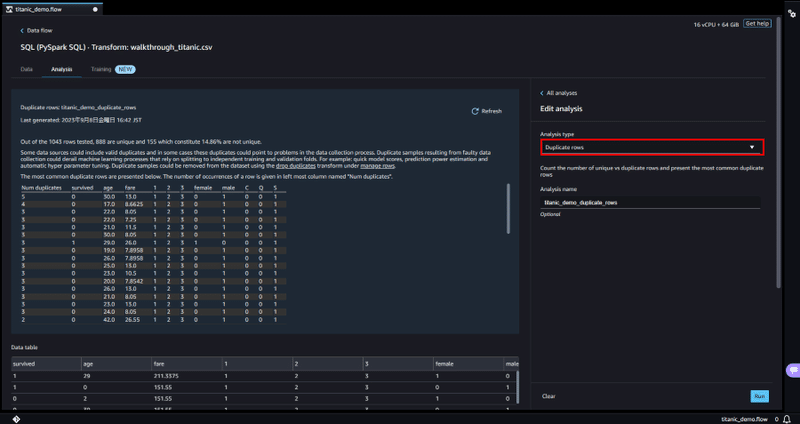
[Data] タブに戻り、先ほど同様にデータの変換を行います。
ADD TRANSFORM から Manage rowsを選択し、Transform 項目で Drop duplicatesを選択して重複行を削除します。
再度インサイトレポートを確認すると、警告が消え整形された状態のデータが確認できました。
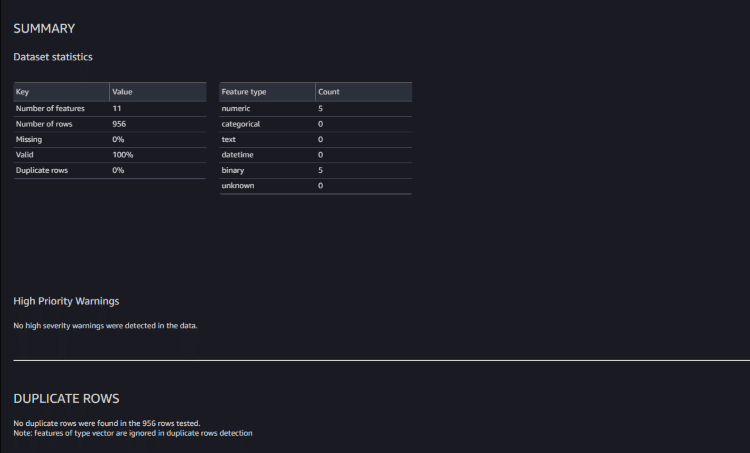
このように、手軽にデータの分析と変換が可能となっているので、適切なデータ処理を素早く行うことができます。
データフロー
「Data flow」ページでは、以下のような形でデータ準備手順を正確に確認することができます。
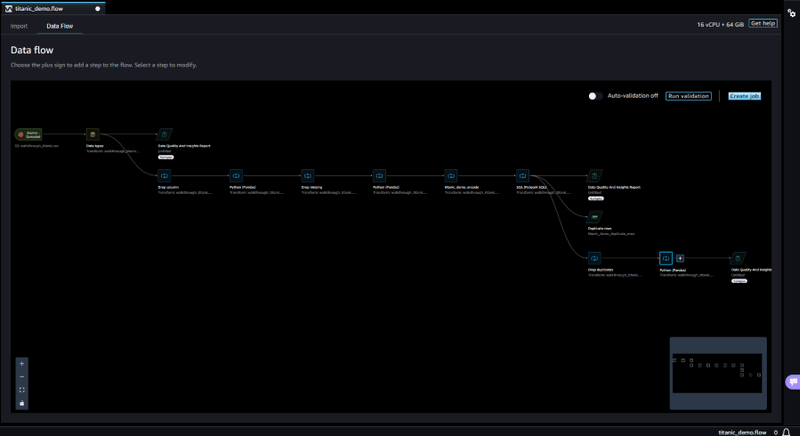
データフローでは任意の場所で、分析や変換処理の追加など行えるほか、データセットの結合など可能となっています。
こちらの画面から、目的に応じた形式でエクスポートを行います。
エクスポート
Data Wrangler では、複数のエクスポートオプションが用意されており、Export toから目的に応じた形式を選択することができます。
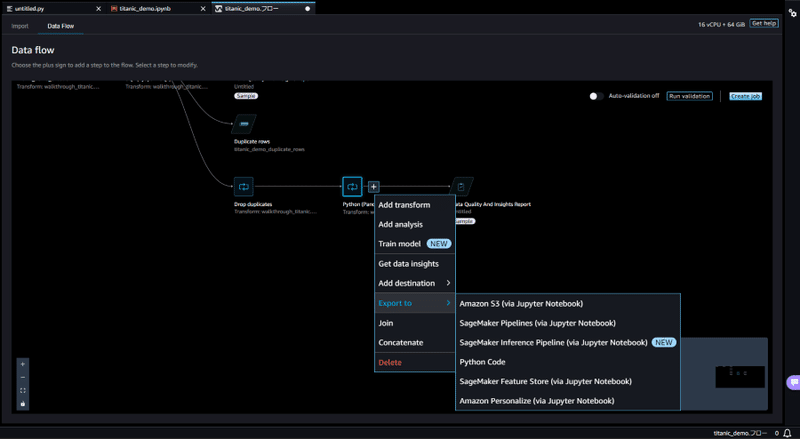
エクスポートオプションは以下になります。
Amazon S3
データフローをジョブとして実行するノートブックを作成
SageMaker Pipelines
データフローをパイプラインへ組み込んだノートブックを作成
SageMaker Inference Pipeline
推論パイプラインへデータフローを組み込んだノートブックを作成
Python Code
手動で行った処理を Python スクリプトに変換
SageMaker Feature Store
データフローで作成した、特徴量を Feature Store へ保存するノートブックを作成
Amazon Personalize
データセットを作成し、Amazon Personalize へインポートするノートブックを作成
今回は Amazon S3 を選択します。
しばらくするとノートブックが自動生成され、画面に表示されます。
こちらのノートブックに書かれた処理コードを、順番に実行することでデータの処理が行われ、最終的に処理されたデータは Amazon Simple Storage Service (Amazon S3)へと保存されます。
こうして保存されたデータは、モデルのトレーニングなどに使用されます。
まとめ
今回、公式デモに沿って一連の流れを体験しましたが、機能が豊富で操作性にも優れたサービスだと感じました。
どこからデータ準備を行えばよいかわからない方でも、インサイトレポートを作成すれば処理すべきデータの確認が行えるので、まずはインサイトレポートを作成し、そこからデータの分析、データの変換を行うのが効果的な使い方だと思います。
今回行った処理のほかにも、Train modelから Amazon SageMaker Autopilot を起動して、機械学習モデルを自動的にトレーニング、調整、構築することもできたりと、Data Wrangler は、データ準備という工程だけでなく、機械学習プロジェクト全体を効率化してくれるサービスだと思います。
気になった方は、ぜひ Amazon SageMaker Data Wrangler を利用してみてください。
この記事が気に入ったらサポートをしてみませんか?