
HTMLタグ名の仕様を根掘り葉掘りする

仕様をいろいろ調べたけど解決できなかった話。
markuplintというHTMLのLinterを作っている。HTMLやその他マークアップ言語のコードのスタイルや、バリデーションを行うツールだ。まだまだ開発途上なんだけど、その中に「タグの名前が正しいかどうか」をチェックする機能を設けたい。HTMLの標準のタグのタイポの発見(sapnタグとか)だったり、HTML4/XHTML由来の非推奨タグの発見(fontタグとか)だったり、もしくはWeb ComponentやJSライブラリなどで利用するカスタム要素のプロジェクトでの命名規則をチェックしたい場合に活用できるようにしたい。
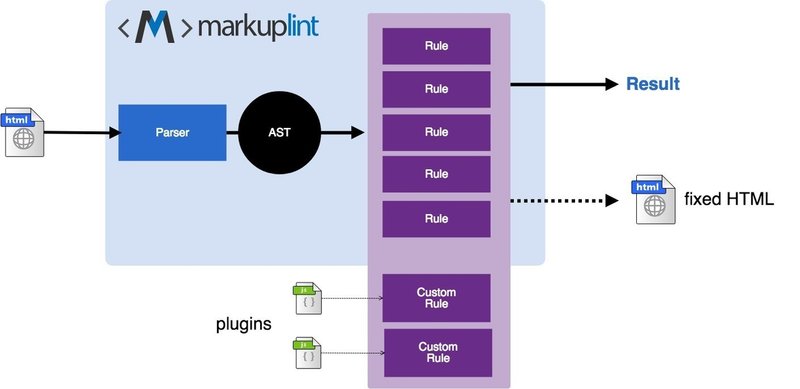
markuplintでは、各チェック内容をルール(Rule)が受け持つことになっている。「タグの名前が正しいかどうか」はひとつのルールとしてそれをチェックするわけなんだけど、その前に渡されたHTML文字列をタグ名やその他に分解する必要がある。「タグ名が正しいかどうかを判断する前にタグ名を抽出する」といったことが必要になる。自分で書いていてとてもややこしい。パーサー(Parser)がその役割を担い、AST(抽象構文木)を生成する。
<div class="fruit">Apple</div>前述のようなHTMLであれば、「<」「div(タグ名)」「 (ホワイトスペース)」「class(属性名)」「=」「"」「fruit(属性値)」「"」「>」「Apple(テキストノード)」「<」「/」「div(タグ名)」「>」といった部分に分けられ、それぞれの機能、何文字目・何行目に出現したかなどの情報をもつ。
雑に抽出することはできる。たとえば「<」の次からホワイトスペースの直前の1つ以上の任意の文字列という抽出方法であれば、前述の「div」は抽出できる。
基本的にそんな感じでいいんだろうけど、やはり作るからには正確に仕様を知っておきたい。そんな軽い気持ちから始めたら、結局答えがまだ見つかってないんだけど、経過を記しておく。
謎のHTMLのタグ名仕様
タグは、要素の名前を与えるタグ名を含む。HTML要素はすべて、ASCII英数字を使用する名前のみを持つ。HTML構文において、外来要素に対するものでさえ、タグ名は、すべて小文字に変換する場合に、要素のタグ名に一致する小文字と大文字の任意の組み合わせで書かれてもよい。タグ名は、大文字・小文字不区別である。
引用: https://momdo.github.io/html/syntax.html#syntax-tag-name
ASCII英数字とは
ASCII 英数字
{ ASCII 数字, ASCII 英字 }
ASCII 数字
{ U+0030 (0) 〜 U+0039 (9) }
ASCII 英字
{ ASCII 英小文字, ASCII 英大文字 }
ASCII 英大文字
{ U+0041 (A) 〜 U+0046 (Z) }
ASCII 英小文字
{ U+0061 (a) 〜 U+0066 (Z) }
引用: https://triple-underscore.github.io/infra-ja.html#ascii-digit
つまり正規表現で表すと
/[a-zA-Z0-9]+/となる。なんだ超シンプル!と思うんだけど、いざ本当にそうかというとだいぶ怪しい。なぜかというと、これは数字から開始することを認めている。
<0>タグ名は数字から開始してもよいのか</0>リンクのように実験してみたところダメだったし、JavaScriptで要素を生成する処理を実行してもエラーになる。
document.createElement('0'); // => DOMException エラーやっぱりどう考えてもさっきの仕様は間違っている。
カスタム要素のタグ名
PotentialCustomElementName ::=
[a-z] (PCENChar)* '-' (PCENChar)*
PCENChar ::=
"-" | "." | [0-9] | "_" | [a-z] | #xB7 | [#xC0-#xD6] | [#xD8-#xF6] | [#xF8-#x37D] | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x203F-#x2040] | [#x2070-#x218F] | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF] | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF]
引用: https://momdo.github.io/html/custom-elements.html#prod-potentialcustomelementname
カスタム要素ははっきりしていてわかりやすい。正規表現だとややこしいのでJavaScriptで表現するとこんな感じになる。
const pcenChar = [
'\\-',
'\\.',
'[0-9]',
'_',
'[a-z]',
'\u00B7',
'[\u00C0-\u00D6]',
'[\u00D8-\u00F6]',
'[\u00F8-\u037D]',
'[\u037F-\u1FFF]',
'[\u200C-\u200D]',
'[\u203F-\u2040]',
'[\u2070-\u218F]',
'[\u2C00-\u2FEF]',
'[\u3001-\uD7FF]',
'[\uF900-\uFDCF]',
'[\uFDF0-\uFFFD]',
'[\uD800-\uDBFF][\uDC00-\uDFFF]',
].join('|');
export const rePCEN = new RegExp(
`^[a-z](?:${pcenChar})*\\-(?:${pcenChar})*$`
);実際は他にも細かいルールがあるがアルファベットで開始してハイフンが入っていれば絵文字も使って良いことになる。
<nav-🍔 role="navigation" aria-label="ハンバーガーメニュー" />ここにはアルファベット開始が明記されていることにはなるがHTMLの標準要素に対しての言及は見つけられなかった。ちなみにカスタム要素の定義では大文字は使ってはいけないことになっている(エラーになる)が、パーサ側は大文字小文字不区別でパースする。ややこしすぎる。
createElementメソッドの仕様
HTMLに書いてなければDOMの方はどうだ、ということで確認してみる。
If localName does not match the Name production, then throw an "InvalidCharacterError" DOMException.
引用: https://dom.spec.whatwg.org/#dom-document-createelement
Name productionとは
NameStartChar ::= ":" | [A-Z] | "_" | [a-z] | [#xC0-#xD6] | [#xD8-#xF6] | [#xF8-#x2FF] | [#x370-#x37D] | [#x37F-#x1FFF] | [#x200C-#x200D] | [#x2070-#x218F] | [#x2C00-#x2FEF] | [#x3001-#xD7FF] | [#xF900-#xFDCF] | [#xFDF0-#xFFFD] | [#x10000-#xEFFFF]
NameChar ::= NameStartChar | "-" | "." | [0-9] | #xB7 | [#x0300-#x036F] | [#x203F-#x2040]
Name ::= NameStartChar (NameChar)*
引用: https://www.w3.org/TR/xml/#NT-Name
おお!カスタム要素と同じく明確な記載があった!と思ったんだけど完全にXMLの仕様を直で参照しているのでとても怪しい。
しかもちょっと待て、コロンやアンダースコアから開始できるのか?!XMLではひらがなや漢字を要素名にできることは以前から知っていたけど、こんなにゆるかったとは。
で、試してみる。
<:.:.:>やってみけど案の定動作しねぇ</:.:.:>やっぱりそこはXMLではなくHTML。こんなふざけたタグ名はさすがに許してくれなかった。ただ実験をいろいろやってみるとDOMもまた味わい深い。
document.createElement(':'); // => <:></:>
document.createElement(':.:.:'); // => <:.:.:></:.:.:>
document.createElement('\u00C0'); // => <À></À>
document.createElement('\u200C'); // => DOMException エラー
document.createElement('\uFDF0'); // => DOMException エラーパースはできなかった「:」や「:.:.:」で要素を生成できているし、ラテン文字や漢字の一部では生成できるけど、ある部分を超えたコードポイントではエラーを返す。
一体何を信じたらよいのやら。
JavaScriptでDOMをエミュレートするJSDOMというライブラリ(Reactのテストなどでも使わている)のソースコードも参考にしてみようとしたけれど、こちらはcreateElementのDOMに仕様書に書かれたとおりXMLの命名ルールに完全に準拠する xml-name-validator というモジュールに依存した実装になっていた。
解決できず
ということで未だ解決できず。まだまだ調べていないところがいっぱいあるので、そのうち見つかるだろうと思っているんだけど、どうしてこう表に出てこないのだろうか。
次はひとまずChromiumのソースコードから探ってみようと思う。
この記事が気に入ったらサポートをしてみませんか?