
機械学習を用いてGTO戦略を理解する Part II 〜Permutation Feature Importance (PFI)を用いた、アクション頻度決定における重要特徴量抽出〜

今回のnoteで取り組んだこと&結論
前回のnoteではボード・ハンドの情報からアクションの頻度を予測するモデルを構築し、精度よく予測できることを確認しました。
ボード・ハンドの特徴とアクション頻度の関係をより細かく見るために、permutation feature importance (PFI)を用いて、作成したモデルの解析を行なっていきます。先に結論を述べると、以下の知見を得ることができました。
IPのEQBが特に重要。
OOPのEQBはやや重要。
high、monotone、connectivityはやや重要。
ペアボードであることやsuitedであることはあまり重要でない。

概要
前回のnoteでは4bet potのCB頻度予測モデルを構築したものの、中身がblack boxであり、特にまだGTO戦略に関する知見を得られていません。
GTO戦略の理解度を高めるために、このような状況下で以下のようなことが知りたい気持ちになってきます。
どのような特徴量が重要なのか。
入出力はどのような関係性をもつのか。
なぜそのような予測をモデルは出したのか。
今回のnoteでは、PFIを用いて重要度を定量化することで1に取り組みます。
これは今後解析を進めていく上で、どの特徴量を優先的に見ていけば良いのか?という解析のする上での目星をつけることができます。
PFIの詳細な定義については付録をご参照ください。
実験
準備
Part Iと同様に以下の状況を考察しました。
100bb BB vs LJ (4bettor)の4bet pot(注1)の25%CBの頻度の予測を対象とします。
pot sizeは50.5bb、残りスタックは75bb
betting sizeの設定は次のようにしました。

次に、PioSOLVERを用いて、被りのない1755flop全てでのゲームツリーを生成し、OOP checkのシチュエーションに関してIPのアクションに関する集合分析ファイルを生成しXGBoostというモデルを学習しました。
詳細は前回のnoteをご参照ください。
得られたPFI
得られたPFIは次になります。
この結果を細かく解釈していきます。
IPのEQBの重要度が高い。 特に強ハンド群(75%-100%)の濃度が25%CBの頻度の予測に特に大きく影響している。
OOP EQBもそれなりの重要度をもつが、IPのEQBに比べると重要度はやや下がる。
high、monotone、connectivityもそれなりの重要度をもつが、IP EQBに比べると重要度はやや下がる。このことから、ボードそれ自体の情報よりも、Equity distributionがどのような形をしているのか?ということの方がアクションにより本質的な影響を与えることがわかる。
ペアボードやsuitedボードであることは、25%CBの頻度予測にはそこまで影響を与えない。
特に1-3の結果は特に重要です。
そもそも、high、monotone、connectivityはボードの情報のみから決まる一方で、EQBはレンジおよびボードの2種類の情報で決まります。そのため、4bet rangeがもし異なる場合、EQBはその影響を反映する一方で、high、monotone、connectivityはボードのみに紐づいているので、レンジの変化を捉えることができないといった状況が考えられます。
故に、アクションの頻度を決定する際は、ボードだけでなく、レンジの情報も照らし合わせるべき、ということをこの結果は示唆しています。
このことは、例えばLJ側の4bet rangeがソリューションよりも大幅に広い場合/狭い場合のアジャストを考える上でヒントになるでしょう。
まとめ
Part IIではPFIを通して、BB vs. LJ (4bettor)のLJ側の25%CB頻度を決める上で重要な特徴量を考察しました。その結果、
IPのEQBが特に重要。
OOPのEQBはやや重要。
high、monotone、connectivityはやや重要。
ペアボードであることやsuitedであることはあまり重要でない。
ということがわかりました。
次回Part IIIでは、それぞれの特徴量について、値が変化すると25%CBの頻度がどのように変化していくのかをpartial dependence (PD)を用いて考察していきます。
(付録)PFIとは
そもそもモデルに入力するそれぞれの特徴量の重要度とはどう定義すべきものなのでしょうか?これにはさまざまな考え方があると思います(注2)。モデルの中でどの程度その特徴量が参照されているのか、であるとか、予測精度にどれほど影響を与えているのか、というようなことが考えられます。
このようにさまざまな重要度が考えられる中で、PFIは元々のモデルによる予測精度と、ある特徴量が「わからない」とした時の予測精度を比べ、精度が大きく低下している場合、その特徴量は「重要」であるとする立場で提案された指標であり、informalには次の形で定義されます(注3):
PFIj = (元々のモデルの精度) − (j番目の特徴量がわからない時の精度).
ここで、 j 番目の特徴量が「わからない」というのをどう表現するかなのですが、次のようにモデルの性能検証用のデータの j 番目の特徴量をpermutation(ランダムに並び替える)します( j = 0 )。
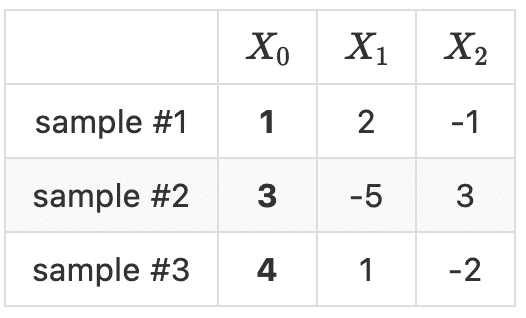
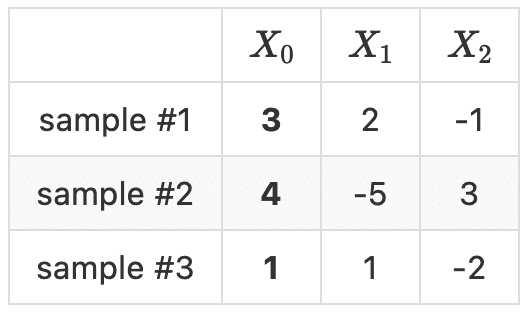
このようにして得られたデータでは、特徴量 X0 が全く出鱈目なものになっています。
一つ具体例を与えます。いま、ある住宅の適正価格を予測するとします。住宅価格の予測には、総部屋数、面積、築年数、地域全域の治安の評価などのファクターが考えられますが、例えば部屋数のみをランダムに並べ替えたデータセットを作成すると、例えば部屋数が本来4部屋の物件が1部屋など出鱈目な数値になります。
ここで、部屋数は住宅価格に明らかに大きな影響を与えると考えられるため、予測精度が大幅に低下することが考えられます。
このような場合、部屋数の予測に対する貢献度が高いと考え、同時にPFIも高い値をとることが予想されます。同様に面積、築年数、治安などに対しても同様の処理を行うことで各特徴量の貢献度を測ることが可能です。PFIが低い特徴量は、予測への貢献度が低い特徴量と考えることができます。
ポーカーの場合は、それぞれのファクターが25%CBにどのような影響を与えているかは自明でないのですが、各特徴量に同様の手続きを施すことで予測への影響度を浮き彫りにすることが可能です。
レンジは3 million poker club (3MPC)配布のこちらのレンジを使用。↩︎
例えば決定木ベースで用いられる重要度として代表的なものに、feature importanceというものがあります https://qiita.com/ameshikou/items/093d86dd46b4d440deae↩︎
差を取る他に、誤差の増加率を取ることも考えられます。また、精度を測る尺度にも、例えば決定係数を用いるなど任意性があります。↩︎
この記事が気に入ったらサポートをしてみませんか?