
Keyphrase Extractionまとめ - Graph base 編-

はじめに
最初、何らかの文章を読むときにざっくりと何について書かれている文章なのかを把握したい場合があります。この時、その文章のトピックを表すキーワードが設定されていると、この把握が容易になります。ただし、学術論文等であれば著者がキーワードを設定していたりしますが、多くのWeb上に存在するニュース等ではこのキーワードが設定されていない文章が多く存在します。今回はこの文章を少数の単語で表現できるようなキーワードを文章中から自動的に抽出する手法、特にGraph basedなアプローチのキーワード自動抽出手法(Keyphrase Extraction)についてざっくりと紹介します。特に以下のライブラリに実装されている手法について紹介します。
キーワード(Keyphrase)とは
KeyphraseとはTopicRank(Bougouin et al., 2013)の説明を借りると
Keyphrases are single or multi-word expressions that represent the main topics of a document.
と書かれており、1つ以上の単語を組み合わせて文章のトピックを表したフレーズということになりそうです。また、Keyphraseの自動抽出では品詞によるフィルタリングがよく行われています。特にPositionRank(Florescu and Caragea, 2017)では正規表現をもって$${(adjective)*(noun)+}$$という表現がなされており、0個以上の形容詞と1個以上の名詞を組み合わせたものになりそうです。
Graph basedなアプローチについて
Graph basedなアプローチの自動キーワード抽出の手法はどの手法においてもおおよそ以下の流れになります。
文章からKeyphraseの候補となる単語を抜き出す
抜き出したKeyphraseの候補をGraphで表現する
表現したGraphの頂点をscoringする
計算したscoreが高いものから順に頂点をいくつか取得する
取得した頂点に紐づく単語列を成形しKeyphraseとする
この手法における工夫ポイントとしては以下のような部分が考えられます。
文章 -> Graphへの変換の仕方
頂点の表現(単語、キーフレーズ候補、トピックなど)
有向グラフか無向グラフか
辺の結び方(隣接する単語間のみ辺を結ぶ、全ての頂点を辺で結ぶ)
辺の重み
Graphに存在する頂点のscoring方法
主にPageRankが使われている
Graphの頂点 -> Keyphraseへの変換方法
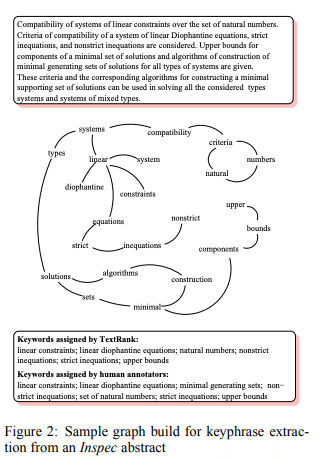
文章のGraph表現としてTextRank(Mihalcea and Tarau, 2004)による表現を一例として載せておきます。
PageRankについて
PageRankアルゴリズムとはWebページの重要度を算出するために開発されたアルゴリズムで、そこからGraphにおける頂点の重要度を算出するために使用されるアルゴリズムとなっています。PageRankでは以下の仮定に基づいて各頂点の重要度をscoreとして算出しています。
多くの頂点から参照されている頂点は重要度が高い - ①
重要な頂点から参照されている頂点は重要度が高い - ②
また具体的なscore$${R(v_i)}$$の計算式は以下のようになります。
$$
R(v_i) = d * \sum_{v_j \in In(v_i)} \dfrac{w_{ji}}{\sum_{v_k \in Out(v_j)} w_{jk}} R(v_j) + (1 - d)
$$
ここで、頂点$${V \coloneqq \{v_i | 0 \leq i < |V|\}}$$と辺$${E \coloneqq \{e_{ij} | 0 \leq j < |V|, 0 \leq j < |V|\}}$$によって構成されるGraph$${G = (V, E)}$$において$${W \coloneqq \{w_{ij} | 0 \leq j < |V|, 0 \leq j < |V|\}}$$を辺$${E}$$の重みとしています。また、$${In(v_i)}$$は頂点$${v_i}$$に入ってくる辺と接続している頂点の集合、$${Out(v_i)}$$は頂点$${v_i}$$から出ていく方向の辺と接続している頂点の集合となっています。最後に、$${d}$$はdumping factorと呼ばれる値で0.85と設定されることが多いです。
ここで第1項に着目すると、$${\dfrac{w_{ji}}{\sum_{v_k \in Out(v_j)} w_{jk}} R(v_j)}$$は図示すると次のような形になります。

つまり、$${R(v_j)}$$を出ていく辺の重みで配分した値を計算し、$${v_i}$$では入ってくる辺全てで上記のように計算した値を加算し、dumping factorを掛けた値を$${R(v_i)}$$に加えています。したがって、$${R(v_j)}$$が高いほど$${R(v_i)}$$が高くなる部分で重要な頂点から参照されている頂点は重要度が高いという①を表現しています。また、辺の重みによる配分と$${v_i}$$に入ってくる辺すべての値を加算している部分で多くの頂点から参照されている頂点は重要度が高いという②を表現しています。
では第2項にはどういう意味があるのでしょうか。ここで第1項を見ると$${R(v_i)}$$に加算した値は$${v_j}$$から$${v_i}$$へのGraph上での遷移確率と見ることができます。したがって、$${R(v_i)}$$はGraph$${G}$$上でrandom walkした時に$${v_i}$$上での滞在確率と捉える事ができます。ここで、Graph$${G}$$が非連結グラフであったり、次数が小さい頂点ではrandom walkを始める頂点によっては滞在確率が0となる頂点が存在してしまいます。これを防ぐために、一定確率でrandomにGraph$${G}$$上の頂点にジャンプさせることを考えます。このrandom jumpが第2項で表現されており、その割合を調整するのがdumping factorとなっています。
ここで辺$${E}$$が重みを持たない場合、重み$${w_{ij}}$$は
$$
w_{ij} = \left\{ \begin{matrix}1&(e_{ij} \in E)\\ 0&(e_{ij} \notin E) \end{matrix} \right.
$$
と表現できます。また、無向グラフの場合$${In(v_i)}$$、$${Out(v_i)}$$は
$$
\exists v_i\in V: In(v_i) = Out(v_i)
$$
となります。
今回紹介したPageRankの計算方法ではrandom jumpによって遷移する頂点は一様な確率で決定されますが、この確率をコンテキストによって調整することで別の情報を組み込む手法も提案されています。例えば、Webページごとに設定されたカテゴリごとに確率を調整する手法(Haveliwala, 2002)や、ユーザの興味によって確率を調整する手法(Jeh and Widom, 2003)が提案されています。
各手法のサマリー
ここではこちらのライブラリで実装されているGraph basedな手法に関して簡単な説明を与えます。
TextRank(Mihalcea and Tarau, 2004)
こちらはGraph basedなKeyphrase Extractionの手法における最もプリミティブな手法です。文章をtokenizeし、固定長のwindow sizeをスライドさせます。このときに同一windowに入ったKeyphrase候補に辺を結び、Graphを生成します。生成したGraphに対してPageRankを計算し、それぞれのKeyphrase候補にscoreを与えます。最終的にこのscoreが高いものをKeyphraseとして抽出します。また、Keyphrase候補が文章中で隣接していた場合、Keyphrase候補を連結したものをKeyphraseとして抽出します。
SingleRank(Wan and Xiao, 2008)
SingleRankはTextRankと比較すると同一windowに含まれた回数を辺の重みとして使用するという点が唯一の違いとなります。
TopicRank(Bougouin et al., 2013)
TopicRankではKeyphrase候補の代わりにtopicをGraphの頂点として使用します。このtopicとはKeyphraseの文字が25%以上同じものを同一のtopicとみなし、生成されます。TopicRankでは完全グラフとなっており、辺の重みはtopicに属するKeyphrase同士の相対位置によって付与されます。こうして生成したGraphに対してPageRankを計算し、それぞれのtopicにscoreを与えます。最終的にscoreの高いtopicから1つずつKeyphraseを抽出します。これにより冗長なKeyphraseが選ばれるのを防いでいるようです。topicからKeyphraseを選択するルールはいくつか試されていますが、文章中で最初に出現したKeyphraseを選択するのが最もF-scoreが高かったようです。
TopicalPageRank(Sterckx et al., 2015)
こちらの手法ではKeyphrase候補ごとにLDAによって計算したtopicが設定されており、topicごとに異なるGraphを生成し、PageRankを計算する手法であるTopicalPageRankを改良した手法になっています。topicごとにPageRankを計算する場合、topicの数に対して線形に計算量が増えてしまいます。そこでこの手法では、random jumpによって到達する頂点を文章のtopic分布によってbiasを書けることで単一のPageRankの計算のみでTopicalPageRankを表現しています。実験結果ではオリジナルのTopicalPageRankと遜色ない結果となっています。
PositionRank(Florescu and Caragea, 2017)
こちらの手法では学術論文においてより文章の先頭に出現しやすい単語のほうがKeyphraseになりやすいという情報を用いてKeyphraseを抽出しています。具体的にはTopicalPageRankと同様により早く文章中で出現したKeyphrase候補にrandom jumpによって到達する確率を増やすようにしてPageRankを計算しています。
MultipartiteRank(Boudin, 2018)
こちらの手法ではTopicRankと同様の方法でKeyphraseごとにtopicを計算しています。ただし、MultipartiteRankではGraphの頂点にはKeyphraseそのものを使用し、異なるtopicに属する頂点同士で有向な辺を結んでいます。辺の重み自体はKeyphraseの相対位置によって計算されており、topicはこの重みを強化するために使用されています。どの様に強化しているかというとtopicの中でもより早く文章中に出現したKeyphraseを優遇するように辺の重みをupdateします。直感的にはTopicRankにおけるtopicからのKeyphrase抽出の部分をPageRankの計算で済ましているように見えます。
最後に
ここまでGraph basedなKeyphrase Extractionの手法について紹介してきました。文章をグラフと見立ててPageRankを計算するのは手法としてはわかりやすかったです。ただ、いくつかの論文ではTfIdfによるKeyphrase ExtractionにF-scoreとして負けていたり、包括的な性能比較がされておらずどの手法が実用的なのかは分かりづらかったです。時間があればいくつかのデータセットで比較してみたいです。
引用
(Haveliwala, 2002)
Taher H. Haveliwala. 2002. Topic-sensitive PageRank. In Proceedings of the 11th international conference on World Wide Web (WWW '02). pages 517–526.
https://doi.org/10.1145/511446.511513
(Jeh and Widom, 2003)
Glen Jeh and Jennifer Widom. 2003. Scaling personalized web search. In Proceedings of the 12th international conference on World Wide Web (WWW '03). pages 271–279.
https://doi.org/10.1145/775152.775191
(Mihalcea and Tarau, 2004)
Rada, Mihalcea and Paul, Tarau. 2004. Textrank: Bringing order into text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. pages 404–411.
http://www.aclweb.org/anthology/W04-3252
(Wan and Xiao, 2008)
Wan, Xiaojun and Xiao, Jianguo. 2008. CollabRank: Towards a Collaborative Approach to Single-Document Keyphrase Extraction. Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008). pages 969-976.
https://aclanthology.org/C08-1122/
(Bougouin et al., 2013)
Bougouin, Adrien and Boudin, Florian and Daille, Beatrice. 2013. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction. Proceedings of the Sixth International Joint Conference on Natural Language Processing. pages 543-551.
https://aclanthology.org/I13-1062/
(Sterckx et al., 2015)
Sterckx, Lucas and Demeester, Thomas and Deleu, Johannes and Develder, Chris. 2015. Topical Word Importance for Fast Keyphrase Extraction. In Proceedings of the 24th International Conference on World Wide Web (WWW '15 Companion). pages 121–122. https://doi.org/10.1145/2740908.2742730
(Florescu and Caragea, 2017)
Florescu, Corina and Caragea, Cornelia. 2017. PositionRank: An Unsupervised Approach to Keyphrase Extraction from Scholarly Documents. Association for Computational Linguistics. pages 1105-1115
https://aclanthology.org/P17-1102/
(Boudin, 2018)
Florian, Boudin. 2018. Unsupervised Keyphrase Extraction with Multipartite Graphs. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). pages 667-672
https://aclanthology.org/N18-2105/
感想等も合わせて送られてくると嬉しいです!