
気候変動のデータを分析してみる【python】

今回は世界の気候変動について、Pythonを用いて調べてみようと思います。
kaggleに『Climate Change: Earth Surface Temperature Data』があるので、これを使います。
Jupyter Notebookでファイルを開きます。
import pandas as pd
df = pd.read_csv("C:\\Users\\csv_file\\GlobalLandTemperaturesByCity.csv")
df
8599212 rows
860万行の膨大なデータがあります。
最初にdfを使いやすくする為に整形します。
AverageTemperatureUncertaint、Latitude、Longitudeは不要なので削除します。
df.drop(["AverageTemperatureUncertainty","Latitude","Longitude"],axis=1,inplace=True)
そしてdtの型をobjectから、datetime64[ns]に変更します。
# 各列のtypeを確認
df.dtypes
# datetime64[ns]に変更
df["dt"] = pd.to_datetime(df["dt"])
df.dtypes
次はdfを扱いやすくする為に、dfにyearだけの列と、monthだけの列を追加します。
df['year'] = df["dt"].dt.year
df['month'] = df["dt"].dt.month
df
範囲の指定をしやすくする為に、dtの列をindexにセットします。
indexの番号は不要です。
df.set_index('dt', inplace=True)
df
最後にNan(Not a Number)を削除して、整形は終わりです。AverageTemperatureにNanがあるのが見えますね。これが含まれる行を全て削除します。
# Nanをカウント
df.isnull().sum()
# Nanを削除
df.dropna(inplace=True)
df.isnull().sum()
ここまでをまとめると。
df.drop()で列を削除
pd.to_datetime()で"dt"をdatetime64[ns]型に変更
dfに"year"と"month"の列を追加
df.set_index()で"dt"をindexに置く
df.dropna(inplace=True)でNanを削除
以上になります。
それではdfを見ていきましょう。
まずはどのくらいの国があるのか
unique()を使って調べます。
df["Country"].unique()
len()で数えると159ありました。
len(df["Country"].unique())
ではその中から、日本のデータを取り出します。
"Japan"があるか確認。
df["Country"].str.contains("Japan").any()Trueと出たので、今度は”Japan”のみを取り出して、df_jpという変数に。
df_jp = df[df['Country'] == "Japan"]
df_jp
次にどのくらいのCityがあるか
unique()とlen()を使って調べます。

175の地域がありました。
info()で見ると1845年から2013年までのデータがあります。
df_jp.info()
それでは東京のデータを見ていきたいと思います。
df_jpからTokyoだけのdfを作ります。
df_jp_tokyo = df_jp[df_jp["City"] == "Tokyo"]
df_jp_tokyo 
東京の一年間の毎月の平均気温を見ます。
では2010年のデータを見ましょう。
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.style.use('seaborn-darkgrid')
# 各期間の変数
span = df_jp_tokyo["2010-01-01":"2010-12-01"]
ax.plot(span.month, span.AverageTemperature, label="2010")
# 目盛変更
loc=[1,2,3,4,5,6,7,8,9,10,11,12]
# 目盛ラベルの表示
plt.xticks(loc)
plt.xlabel("month",fontsize=17)
plt.ylabel("AverageTemperature",fontsize=17)
plt.legend(fontsize=18)
plt.tick_params(labelsize=15)
fig.set_size_inches([8, 10])
plt.show()
春から夏にかけて上がって、8月をピークにそこから下がってますね。
最高が8月の28度、最低が1月の2度ですね。
では10年毎のデータを比較してみましょう。
# 各期間の変数
span_10 = df_jp_tokyo["2010-01-01":"2010-12-01"]
span_00 = df_jp_tokyo["2000-01-01":"2000-12-01"]
span_90 = df_jp_tokyo["1990-01-01":"1990-12-01"]
span_80 = df_jp_tokyo["1980-01-01":"1980-12-01"]
span_70 = df_jp_tokyo["1970-01-01":"1970-12-01"]
ax.plot(span_10.month, span_10.AverageTemperature, label="2010")
ax.plot(span_00.month, span_00.AverageTemperature, label="2000")
ax.plot(span_90.month, span_90.AverageTemperature, label="1990")
ax.plot(span_80.month, span_80.AverageTemperature, label="1980")
ax.plot(span_70.month, span_70.AverageTemperature, label="1970")
1980年が低く、他の年は1、2度の違いがあるという感じですね。
5月と10月はどの年もほとんど、差がなくて興味深いです。
次は夏の季節にフォーカスして見ていきましょう。
昔が今より涼しかったのかを、2000年よりまえのデータで調べます。
データは10年毎です。
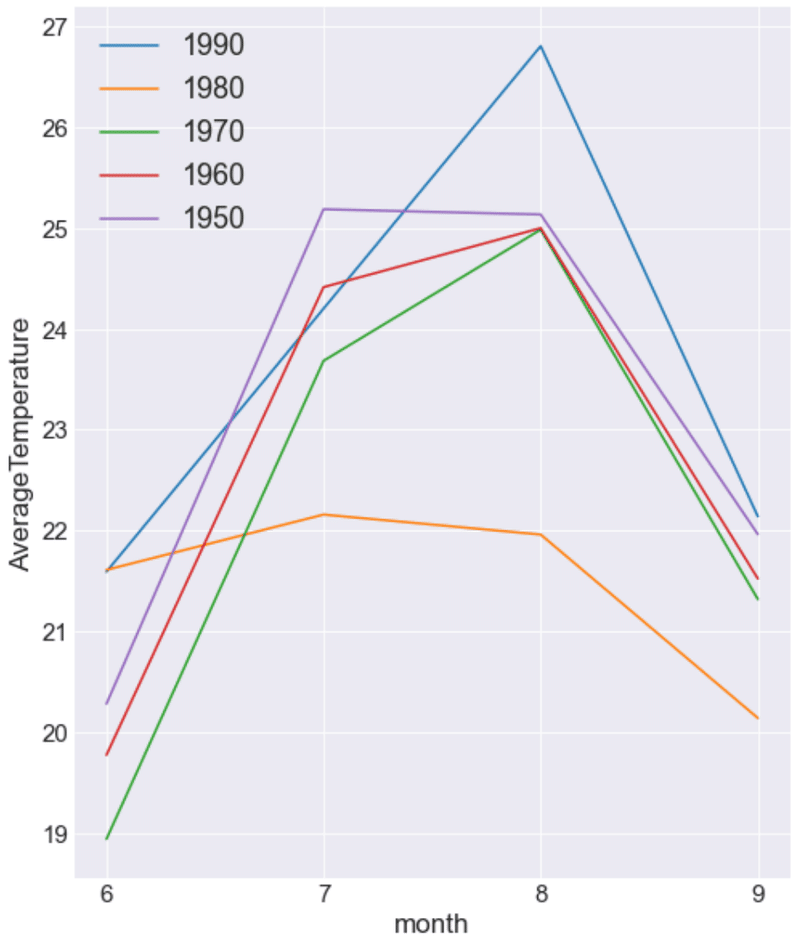
1980年は冷夏だったみたいですね。1990年は26.8度で他の年より高いです。50、60、70、は大体同じグラフをしていますね。
1980年の前後の年の8月も調べてみると25度前後だったので、やはり80年だけが低かったのでしょう。
2003年も冷夏で特に7月が涼しかったみたいです。
7月の平均気温は21度を下回ってます。

各年の8月のデータを取り出してみようと思います。
df_jp_tokyo_8 = df_jp_tokyo[df_jp_tokyo["month"] == 8]
平均を出すと24.8度となりました。
# 平均の計算
df_jp_tokyo_8["AverageTemperature"].mean()
ではこの中から24度より低い年を抽出します。
df_jp_tokyo_8[df_jp_tokyo_8["AverageTemperature"] < 24]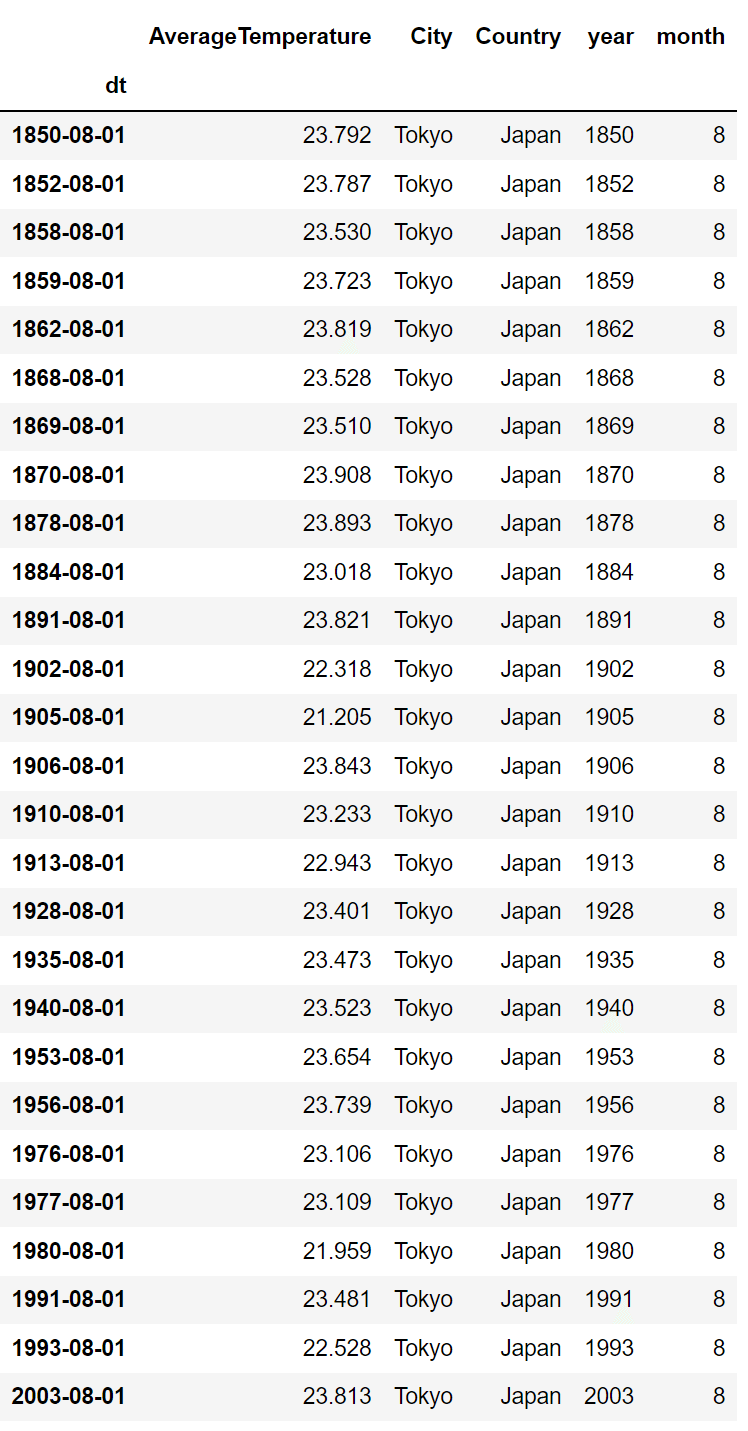
1800年代、1900年代が多いですね。2000年代は2013年のみです。
やはり昔は涼しかったのでしょう。100年以上前にはなりますが。
1900年代には、23度以下の年が5つあります。

最後に1800年代、1900年代、2000年代をそれぞれのグラフで比較します。
df_jpから7月と8月のデータを抽出。
df_jp_tokyo_7_8 = df_jp_tokyo[(df_jp_tokyo["month"] == 7) | (df_jp_tokyo["month"] == 8)]
df_jp_tokyo_7_8
fig, ax = plt.subplots()
# 期間の変数
period_1 = df_jp_tokyo_7_8["1845-07-01":"1899-08-01"]
ax.scatter(period_1.month, period_1.AverageTemperature,color="r",label="1845-1899")

8月に1回だけ26度を超えた年かがある
# 期間の変数
period_2 = df_jp_tokyo_7_8["1900-07-01":"1999-08-01"]
ax.scatter(period_2.month, period_2.AverageTemperature, color="orange",label="1900-1999")

8月の最高平均は26.8度
# 期間の変数
period_3 = df_jp_tokyo_7_8["2000-07-01":"2013-08-01"]
ax.scatter(period_3.month, period_3.AverageTemperature,color="b",label="2000-2013")

分かりやすいようにグラフを重ねてみました。

1900年代の7月の平均気温は23度を下回る日多いですね。2000年代は2回しかりません。だんだんと上下の幅が広くなっているのが興味深いです。

こちらの8月のデータでも1900年代は24度を下回る日が多いです。2000年代は一回だけです。
単純に1900年代のデータが多いというのもありますけど、やはり昔は涼しかったのでしょうか。このデータでも最高平均気温は右肩上がりですから、徐々に暑くなっているのは間違いなさそうです。
まとめると、昔も暑い年はあったが、涼しい年もあった。
2000年以前は涼しい年が多かった。
平均気温は高くなっている。
昔は涼しかったという意見は間違ってはいないですね。
あと2013年までのデータなんで、最近のデータも欲しいところです。
この記事が気に入ったらサポートをしてみませんか?