
画像生成AIでオリキャラを生成した工程を残す

こんにちは、本好きの下剋上を一気読みする沼の生活から徐々に脱しつつある @yoshikouki です。続編?に位置する作品の更新が待ち遠しくて気分の浮き沈みすることに最近悩んでいます
StableDiffusion を使って「ルーティンナさん」というオリキャラを作ったので、メモを兼ねてその工程を残します。用語などの説明はあまりしていません。気になる方は適宜調べて見てください
工程の流れ
大きく以下の手順です
画像生成 (Txt2Img のガチャ)
眼鏡の修正
髪の毛の調整
高解像度化
2 と 3 の工程は、1 で生成した画像の修正です。修正したい項目が多いとこの工数は増加していきます。逆に言えば修正したい項目がなければ最短 2 工程です。
高解像の画像を一度に生成しないのは、効率を重視するためです。StableDiffusion を使った画像生成の手順は、高頻度の画像生成を繰り返し、その中から良さそうな画像をブラッシュアップする工程を取ることが多いようです。界隈では、この高頻度で画像生成を繰り返す初期工程を「ガチャ」と呼称しています
1. 初期画像生成 Txt2Img
パラメタ (プロンプトなど)
(looking ahead:1.5),shoot from front,1 woman,warm smile,long natural brown hair,highly detailed eyes,Symmetrical round glasses,small breasts,bright blouse,white background
Negative prompt: Distorted glasses, (EasyNegative:1.2), worst quality, low quality
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3731665322, Size: 512x768, Model hash: cbfba64e66, Model: CounterfeitV30_v30, Denoising strength: 0.7, Clip skip: 2, Mask blur: 4, ControlNet: "preprocessor: none, model: control_v11e_sd15_ip2p_fp16 [fabb3f7d], weight: 0.5, starting/ending: (0, 1), resize mode: Just Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (-1, 2, -1)", Version: v1.4.0300枚以上の画像を生成し、その中からいくつかスクリーニングしました
手の変形や指・腕の数がおかしいものや細かいところは気にせず、画像の全体感や雰囲気を優先に選別します
今回は「キャラクターができるだけ正面を向いている」ことが望ましかったので、スクリーニング結果からさらに前を向いておりイメージに近いキャラクターを選択しました

このキャラクターに決定。

この時点で課題は3つほどあります
顔が暗い
眼鏡が左右対称ではない
髪の毛多い
Txt2Img の時点で ControlNet の openpose を使えばもっと楽でした (反省)
openpose を使った場合、一度全身を写す画像を生成してから好みの画角に切り取って行く流れが良いと現時点では考えます
2. 眼鏡の修正 (ControlNet Inpaint)
Inpaint で顔を修正することに。

パラメタ (プロンプトなど)
(looking ahead:1.5),shoot from front,1 woman,warm smile,long natural brown hair,highly detailed eyes,Symmetrical round glasses,small breasts,Lighted face,bright blouse,white background
Negative prompt: Distorted glasses, (EasyNegative:1.2), worst quality, low quality
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3575290748, Size: 512x768, Model hash: cbfba64e66, Model: CounterfeitV30_v30, Denoising strength: 0.7, Clip skip: 2, Mask blur: 4, ControlNet: "preprocessor: inpaint_only, model: None, weight: 0.5, starting/ending: (0, 1), resize mode: Just Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (-1, 2, -1)", Version: v1.4.0以下のような画像が生成されます

修正後の画像 (まだ顔が暗いですが)

3A. 髪の毛の修正1 (ControlNet Inpaint)
次に毛量を調整します
この画像は行く行くアイコンになる予定なのですが、多分このままアイコンにしたら半分以上が髪の毛になるので調整したいのです
修正は ControlNet Inpaint をつかってやります。今回は Img2Img でやりましたが Txt2Img でも同じ事ができると思います
ControlNet で修正したいところを塗りつぶして実行
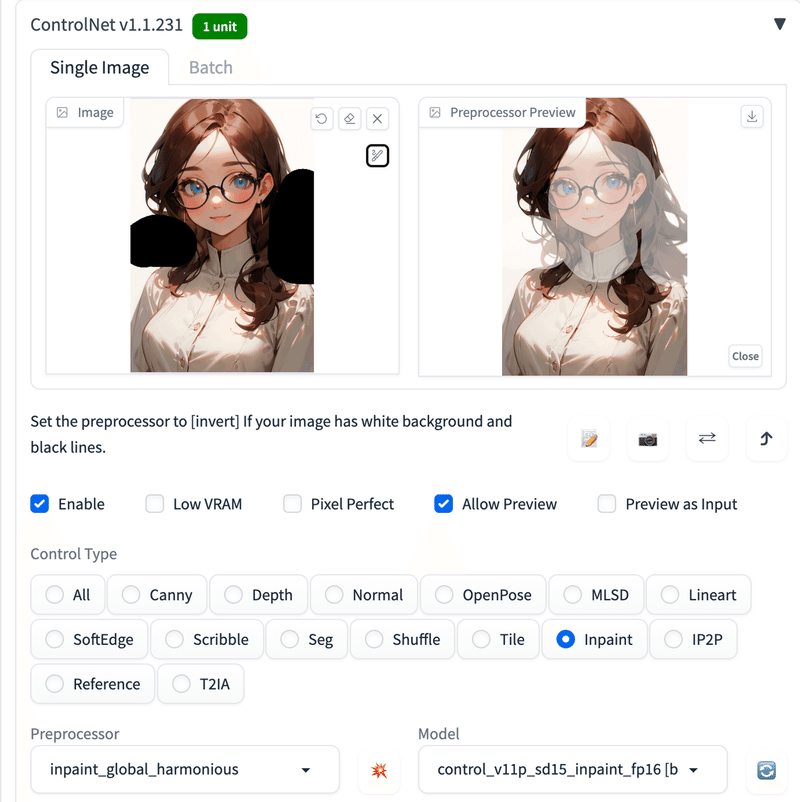
パラメタ (プロンプトなど)
(white background:1.5),long natural brown hair
Negative prompt: (EasyNegative:1.2), worst quality, low quality
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3558129972, Size: 512x768, Model hash: cbfba64e66, Model: CounterfeitV30_v30, Denoising strength: 0.75, Clip skip: 2, Mask blur: 4, ControlNet: "preprocessor: inpaint_global_harmonious, model: control_v11p_sd15_inpaint_fp16 [be8bc0ed], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (-1, -1, -1)", Version: v1.4.0しかし、これでは上手く行きませんでした。もう量が減らないのです。おそらくInput の画像 (Img2Img か ControlNet かは分からない) に引っ張られているのだと思います。
そのため次の手を打ちます
3B. 髪の毛の修正2 (直接修正 × ControlNet Inpaint)
まず、髪のボリュームを減らしたい領域を白色で塗りつぶします
macOS で画像を開いた「プレビュー」アプリで白い楕円を書き込みました

次に、この画像を ControlNet Inpaint で処理します。白く塗りつぶした領域より少し広めに範囲指定しています
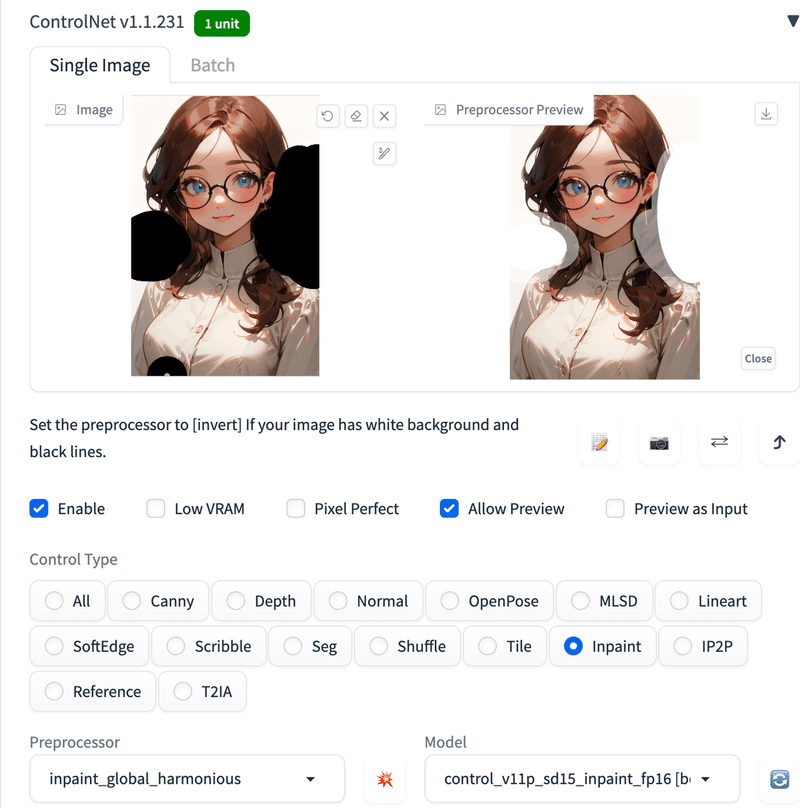
毛量が減ってる!

修正後の画像

4. 高解像度化 (ControlNet Tile × Tiled Diffusion)
これまでの画像は横幅 (width) を 512 px で生成しています。これでは実用に耐えれないため、高解像度化します
使用する技術は ControlNet Tile と Tiled Diffusion という拡張機能の合わせ技です
PCスペックが足りないなら Tiled VAE も併用することができるようです (今回は使いませんでした)
パラメタ (プロンプトなど)
(looking ahead:1.5),shoot from front,20s woman,warm smile,long natural brown hair,highly detailed eyes,glasses,small breasts,simple blouse,white background, (masterpeace, best quality, good quality:1.4), masterpeace
Negative prompt: (EasyNegative:1.2), worst quality, low quality
Steps: 30, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 1518968624, Size: 1024x1536, Model hash: cbfba64e66, Model: CounterfeitV30_v30, Clip skip: 2, Tiled Diffusion: {"Method": "MultiDiffusion", "Tile tile width": 96, "Tile tile height": 96, "Tile Overlap": 32, "Tile batch size": 1}, ControlNet: "preprocessor: tile_colorfix, model: control_v11f1e_sd15_tile_fp16 [3b860298], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (-1, 8, -1)", Version: v1.4.0
入力と出力には差異があるものの、出力画像間ではよく見ないと気付かないほどの差異しかないように見えます
ControlNet Tile の Preprocessor による差異は大きかったです。今回は tile_colorfix を採用しています
tile_resample は凄く細やかに書き込みが行われます (プロンプトの影響もあるかも?未検証)
tile_colorfix は、今回のケースではほどよく感じる書き込みに留まりました
出力画像間に差異が少なかったため、消去法で選んでいきました
変な線が入っていないか
矛盾ある表現がないか
必要以上に書き込まれていないか
最後の2択は直感
課題や反省点は残るものの、完成しました

初期画像から完成までの変遷

初期生成の着手から完成まで、5〜8時間ほどの作業時間だったと思います。ControlNet の経験値を上げて使い馴れたら3時間もかからないかもしれません
今回使用したアドオン技術
(Extensions をはじめ、標準機能以外でセットアップしたもの)
EasyNegative (Negative prompt)
CounterfeitV30_v30 (学習モデル)
Tiled Diffusion
ControlNet
Clip skip
VAE (変更)
まとめ
今回は私なりにある程度ちゃんと画像生成した手順を、メモだつら公開してみました。どなたかの参考になれば幸いです。
もしご指摘や質問などございましたら、Twitter DM @yoshikouki までご連絡ください
おまけ: ルーティンナさんの設定
ChatGPT に作ってもらった設定があります
容姿:若々しい女性、大きな目、温かい微笑み、平均的な体型
性格:ポジティブで元気、他人の目標達成を助ける
性別:女性
服装:モダンカジュアル、明るい色調
年齢:28歳、活動的な印象
ルーティン:元気づけるストレッチとリラックス音楽
バックストーリー:ルーティン管理の苦労から生まれた助ける存在
好きなもの:新しい学び、ユーザーの達成感
特技:タスクの優先順位決定、適切なリマインド方法の見つけ出し
嫌いなもの:無駄な時間、ネガティブなエネルギー
モットー:「小さな一歩が大きな変化を生む」

この記事が気に入ったらサポートをしてみませんか?