
ピアソンの積率相関係数について、何故ノンパラメトリックで用いられないのか

ピアソンの積率相関係数は以下の式で表される。
$$
r_{xy}=\frac{\sum_{i=1}^n(x_i-\bar{x})(y_i-\bar{y})}{\sqrt{\sum_{i=1}^n(x_i-\bar{x})^2}\sqrt{\sum_{i=1}^n(y_i-\bar{y})^2}}
$$
これはよく知られた式なので、これ自体がある二変数の類似性を表すことは調べればいくらでも出てくると思います。しかし、この式はデータがノンパラメトリックなものである場合あまり適切でない指標であるという話は高校数学レベルではあまり語られません(パラメトリック・ノンパラメトリックの説明についてはここでは省略します)。統計の教科書でも「ピアソンの相関係数は正規分布に従っている必要がある」と書かれていたりしますが、なぜそうなのかの説明が掲載されていることはあまりないように思えます。私の使っている教科書だけかもしれないですが。
この記事では何故ピアソンの相関係数がノンパラメトリックでは不適切になるかを考察します。
「外れ値」に対する弱さ
上記の式の通り、ピアソンの相関係数は標準偏差を含みます。
$$
標準偏差=\sqrt{\frac{\sum_{i=1}^n(x_i-\bar{x})^2}{n}}
$$
そもそも標準偏差とは、「平均からの距離」をもとにした統計量です。各データから平均を引いたものを「偏差」と呼びますが、これが概念的には距離に近いものになります。
ここで大きく問題になってくるのが「平均」の指標です。この統計量は「外れ値」によって大きく変動しますが、このことについて具体例を挙げて説明します。
日本の「平均年収」は約445万円と言われています。しかし「中央値」になると約396万になります。一部の金持ちが平均を大きく引き上げているので、「真ん中」であるはずの396万円から平均が50万円も多くなってるわけです。仮に年収が正規分布に従っている場合、平均値は「集団の真ん中」としての意味を持ちますが、今回のような場合その機能を果たしません。
先ほど標準偏差は「平均からの距離」と言いました。ここで平均が外れ値によって大きくずれるようなことがあれば、その値一つで標準偏差が変化してしまい、これではデータの性質を正確に表せるとは言えません。大雑把に表すことは可能かもしれませんが。
このことから、正規分布に従っていないデータに対して相関係数を用いるのは適切でない場合があることが分かります。
近似直線からの直感的な検討
Excelなどで相関係数を考え散布図を描く時、近似直線を図示する場合があると思います。タンパク質の濃度を蛍光で測定するとき、濃度が既知のタンパク質の蛍光を測定してその近似直線を求めてから濃度未知の試料を検査機にかけますが、相関があると仮定される場合、そういった近似直線の一次関数を用いて一方の変数からもう一方の変数を推定することが出来ます。
近似直線を作成する時、仮に外れ値があればその直線の傾きは大きく変わります。
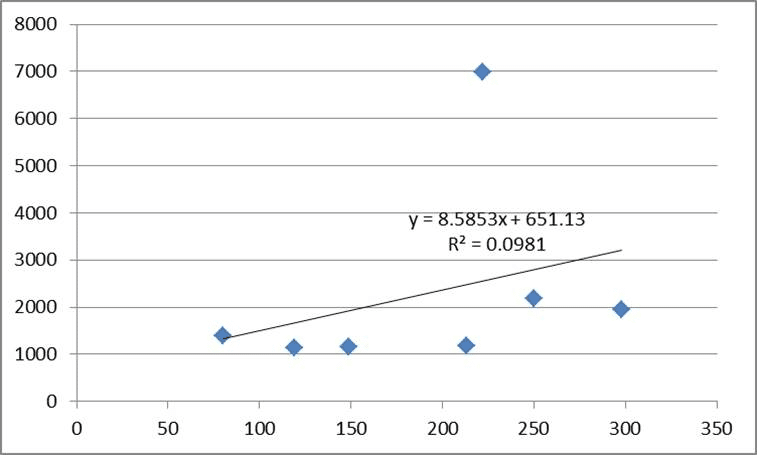
上の図のように、外れ値がある場合に近似直線を描くと、ほとんどのデータより上に直線があることになります。この近似直線は「だいたいこの直線に沿って相関してるよ」という指標にもなるわけで、外れ値がある場合はその相関性を上手く表せないことになります。
まとめ
ピアソンの相関係数が正規分布に従っていない場合好まれないのは、こういった外れ値への弱さや分布の仕方によってデータの性質を表せないことがあるためです。さらには、標準偏差などの指標がそもそもパラメトリックなデータに対して適用させるものであるということも言えます。そのためノンパラメトリック、あるいは分布が不明なデータではスピアマンの順位相関係数が用いられることが多くなります。スピアマンの順位相関係数については別記事で導出をしようと思うので、書けたら下に記事のリンクを貼ります。
この記事が気に入ったらサポートをしてみませんか?