SARIMAモデルの時系列分析で未来予測にチャレンジ!

はじめに
Pythonどころかプログラミング未経験者の四十路である私ですが、なぜこの年齢でPythonを学ぶことにしたのかといえば、
「今話題のAIって何?人工知能って何?」という単純な好奇心からでした。
AIを上手く活用すれば、今まで存在しなかった革新的なサービスを提供できます!DX化をスピーディーに進めることができます!
といった謳い文句で、取引先からもAI導入の提案をよく受けますが、正直お金を掛ければ自分が思い描いているかたちでベンダーさんが実装してくれると思います。
ただ、せっかく導入検討していくならその前にまずは、
AIとは何か知っておこうかな?
ついでに自分でも出来ることはあるかも?
何歳だろうが勉強しておいて損はないよな?
と考えたことが、今回Aidemyで学び始めたきっかけです。
そこで今回は、私の業務でもある設備保全管理の一部として、17種類の設備の異常件数の予測をARIMAモデルを用いて時系列分析にチャレンジしました。
環境
windows10 20H2
Python 3.10.2
Jupyter Notebook 6.4.5
Excel
今回使用したライブラリ
pandas==1.3.4
warnings==1.3.4
intertools==1.3.4
numpy==1.3.4
statsmodels==1.3.4
matplotlib==1.3.4
私のレベル
プログラミング完全未経験
目的
17種類ある設備の月毎の異常件数(2018年9月~2022年7月)約4年分のデータから、来年2023年1月に一番不具合が起きそうな設備を予測し、今のうちらから予防保全を行ってトラブルを未然に防いでしまうという作戦。
セットアップ(Monthly編)
使用するデータの読み込み
まずは使用するExcelファイル・Sheet・読み込む列/行 を指定していきます
使用するのは、17種類ある各設備の月毎の異常件数(2018年9月~2022年7月)約4年分のExcelデータ
※Excelファイルは公開NG
import pandas as pd
df = pd.read_excel("data.xlsx",sheet_name = "Data table①_エラー「ME」")
df = df.T
df.columns = df.iloc[1,:]
df = df.iloc[2:,:]
df = df.dropna()
df = df.iloc[:-4,:-4]
df = df.drop("出荷実績(件)",axis = 1)
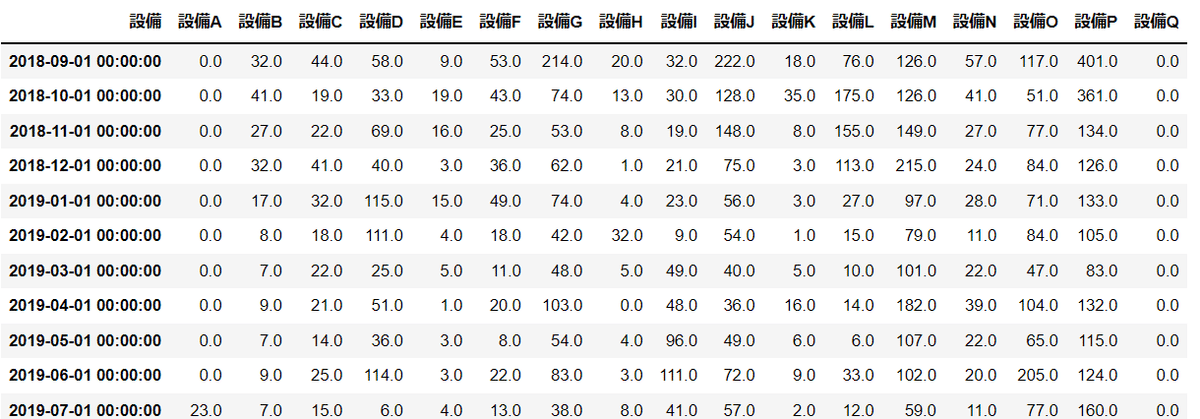
df各設備毎(設備A~設備Q)までの月毎の異常件数が確認できます
※設備A~Qの内、設備Qのみ2020年9月からの件数
必要なライブラリのインポートしてデータを整理
次に必要そうなライブラリをインポートします
取得するデータの期間もここで指定します
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
#データ取得している期間
index = pd.date_range('2018-09-01', '2022-07-01', freq='MS')
#indexをリセットしてindexを再設定
df = df.reset_index()
df.index = indexパラメーターの最適化とモデルの構築
各パラメーターがそれぞれ、0,2の場合についてのSARIMAモデルのBIC(ベイズ情報量基準) を計算し、最もBICが小さくなった場合を表示します
# パラメーターの最適化関数
def selectparameter(DATA, s): #時系列データと周期
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
return parameters[np.argmin(BICs)] #最も小さくなった場合を表示
best_params = selectparameter(df["設備A"].astype(int), 3) #上部で求めたパラメーターを使用してモデルを構築
SARIMA_model = sm.tsa.statespace.SARIMAX(df["設備A"].astype(int), order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()予測
未来の予測結果を取得
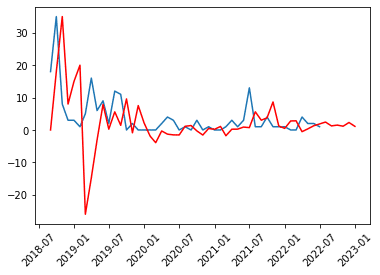
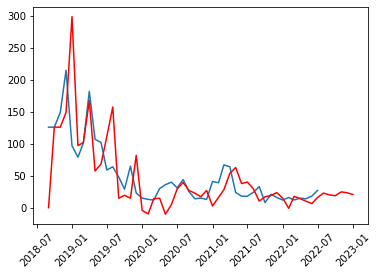
2018年9月~2022年7月までのデータから2023年1月までを予測します(予測値は赤色・実数値は青色)
result = {}
for column_name in df.columns[1:]:
print(column_name)
best_params = selectparameter(df[column_name].astype(int), 4)
#モデルの当てはめ
SARIMA_model = sm.tsa.statespace.SARIMAX(df[column_name].astype(int), order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
total = SARIMA_model.predict('2022-07-01', '2023-07-01') #実測値がないデータを反映
result[column_name] = total.sum()
pred = SARIMA_model.predict('2018-09-01', '2023-01-01') #実測値があるデータの予測
#データの可視化
plt.plot(df[[column_name]])
plt.xticks(rotation=45)
plt.plot(pred, "r")
plt.show()














最も故障が発生する設備を抽出
max(result)抽出結果
'設備Q'設備Qが一番異常が多くなることが予測されました
性能評価・考察①
今回は4年分の月毎のデータから予測しましたが、もう少しデータ量があるとより精度の高い予測データが取得できると思います。また、設備Qはデータの取得期間が他の設備より少ないため、今回のような結果に結びついているところもあり、まだ精度としてはイマイチかもしれません。
そこで、もう少し精度を上げるため、4年分の月毎ではなく日別の異常件数(2018年8月1日~2022年7月31日まで)を取得できたので、今度はこのデータを使って予測して変化をみていきたいと思います。
セットアップ(Daily編)
使用するExcelデータの読み込み
#必要なデータの取得
import pandas as pd
df = pd.read_excel("data_Day.xlsx",sheet_name = "Machine error")
df = df.T
df.columns = df.iloc[1,:]
df = df.iloc[2:,:]
df = df.iloc[:,:19]
df※設備Qのみ2020年9月からの件数

この状態だとNaNなど不必要な情報が多いのでデータを整理していきます
必要なライブラリのインポートしてデータを整理
#必要なライブラリのインポート
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
%matplotlib inline
#いらない列を削除
df = df[df[df.columns[0]] .isnull()]
df = df.iloc[:,1:]
#NaNを数値化
df = df.fillna(0)
#データ取得している期間
index = pd.date_range('2018-08-01', '2022-07-31', freq='D')
#indexをリセットしてindexを再設定
df = df.reset_index()
df.index = index
df = df.iloc[:,2:]
df
データ取得に必要な情報だけになりました
パラメーターの最適化とモデルの構築
Monthly編と同様の方法です
# パラメーターの最適化関数
def selectparameter(DATA, s): #時系列データと周期
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], s) for x in list(itertools.product(p, d, q))]
parameters = []
BICs = np.array([])
for param in pdq:
for param_seasonal in seasonal_pdq:
mod = sm.tsa.statespace.SARIMAX(DATA,
order=param,
seasonal_order=param_seasonal)
results = mod.fit()
parameters.append([param, param_seasonal, results.bic])
BICs = np.append(BICs, results.bic)
return parameters[np.argmin(BICs)] #最も小さくなった場合を表示
best_params = selectparameter(df["設備 A"], 7) #上部で求めたパラメーターを使用してモデルを構築
SARIMA_model = sm.tsa.statespace.SARIMAX(df["設備 A"].astype(int), order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()予測
未来の予測結果を取得
2018年8月1日~2022年7月31日までのデータから2023年1月までを予測します(予測値は赤色・実数値は青色)
#resultに未来の予測結果を取得
result = {}
for column_name in df.columns:
print(column_name)
best_params = selectparameter(df[column_name].astype(int), 4)
SARIMA_model = sm.tsa.statespace.SARIMAX(df[column_name].astype(int), order=best_params[0],
seasonal_order=best_params[1],
enforce_stationarity=False, enforce_invertibility=False).fit()
total = SARIMA_model.predict('2022-08-01', '2022-10-01')#実測値がないデータを反映
result[column_name] = total.sum()
pred = SARIMA_model.predict('2018-08-01', '2023-01-01')#実測値があるデータの予測
plt.plot(df[[column_name]])
plt.xticks(rotation=45)
plt.plot(pred, "r")
plt.show()※出力結果は設備A~設備QまでのDailyのグラフがプロットされますが、
今回は設備Aと設備IでDailyとMontlyの比較をしてみます




最も故障が発生する設備を抽出
max(result)抽出結果
'設備Q'性能評価・考察②
月毎と比較して日別の方がデータ量が多いので精度としては上がっているように思いますが、今回は結果にはあまり大きな差を感じることが出来なった印象を受けました。データのとり方から見直してみると、もっとわかりやすく予測が出来ると思いました。
まとめ
今回、Aidemyのデータ分析講座6ヵ月間を受講しましたが、学んだことをとにかく毎日5分でも10分でも復習、予習を繰り返すことが、プログラミング習得の一番の近道だと実感しました。
そういった意味では、仕事の都合で思うように勉強時間を捻出出来ず大変苦しみましたが、今回の成果物の作成でこれまで学習したことを振り返ることが出来ましたし内容はイマイチなところもありますが、今後の業務にも生かせる内容となったので、この経験を元にもっと実践的な予測モデルを作成出来るようにしていきたいと思います。