GCP #5 ビッグデータ

概要
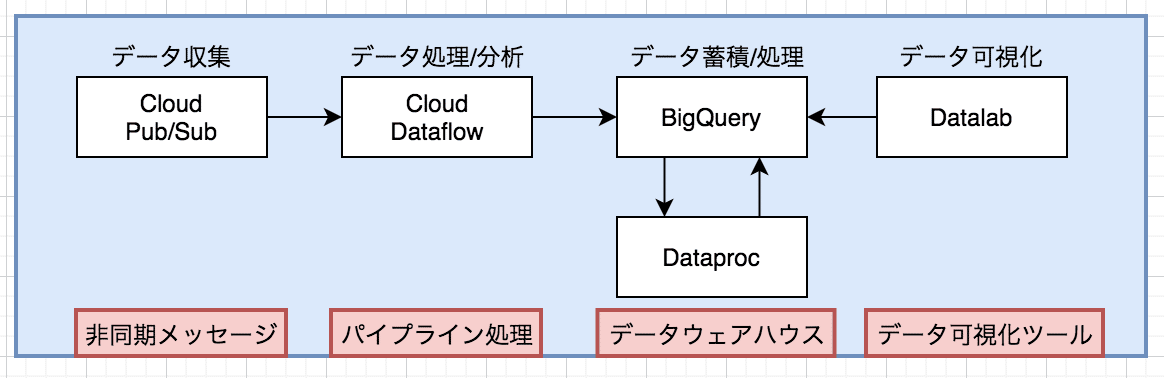
以下の5種類がある
1.Cloud Pub/Sub
2.BigQuery
3.Dataflow
4.Dataproc
5.Datalab
1.Cloud Pub/Sub
概要
・低レイテンシー、高可用、スケーラビリティを持ったメッセージサービス
・AWSのSQSとSNSを組み合わせたようなもの
・SNSのようにPushが可能
・SQSのようにPullが可能
アーキテクチャ
アクター
パブリッシャー:メッセージを送信するデバイス
サブスクライバー:メッセージを受信するデバイス
パブリッシャーはインターネット上のエンドポイントへHTTPSリクエスト
を送付する
サブスクライバーはPullもしくはPushで取得する。パブリッシャーの際と
同様で、HTTPSである
構成要素
トピック:パブリッシャーから見た送信先
サブスクリプションは:サブスクライバーから見た送信元
トピックはメッセージを受け取り、サブスクリプションにメッセージを
渡す役割を持つ

注意点
・メッセージの順序制御を行なっていないので、順序を守る必要なシステ
ムには採用できない
・メッセージが複数回送信される可能性がある
セキュリティ
・トピック、サブスクリプションレベルでのアクセス制御が可能
・通信はHTTPSで暗号化されている
・Cloud Pub/Subとの通信はインターネットを経由する必要がある
2.BigQuery
特徴
・単なるデータの格納だけでなく、分析が可能
・処理性能が超はやく、テラバイトのデータを数秒で返却可能
・SQLライクなクエリーを利用可能
・処理結果をキャッシュ(一時テーブル)し24時間保持が可能
・処理結果をCSV,JSONで保存可能
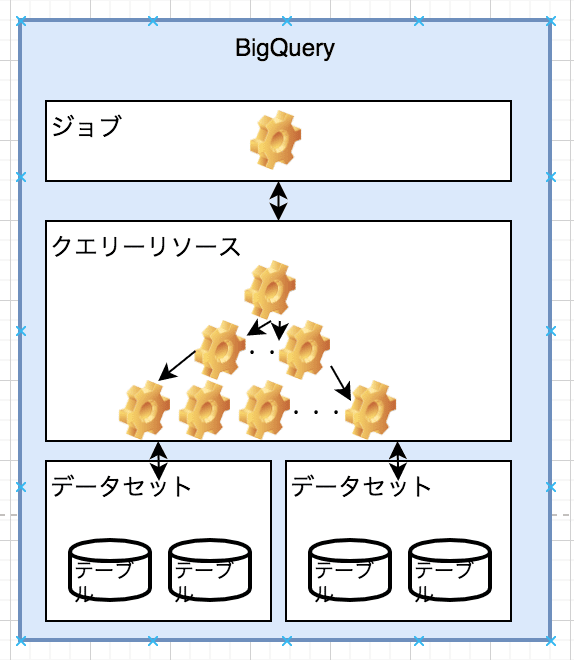
アーキテクチャ
テーブル:データの格納単位
データセット:論理的にテーブルを格納する単位
ジョブ:利用者が作成し、データの取り込み、クエリーなど
BIgQueryが自動で行なってくれるタスク
クエリー:上位からの操作指示を受け取り演算する
クエリーの種類
インタラクティブクエリー
・実行命令を出すとすぐに処理が実行される
・デフォルトで適用
・同時実行は50が上限
バッチクエリー
・一度キューに格納し、クエリーリソースがアクティブになっ
た後、処理される
・24時間以内に処理されない場合は、自動的にインタラクテ
ィブクエリーに変更される
・同時実行上限はなし
利用方針
・データセットはロケーションやACLを利用した権限設定が可能
・データセットは利用目的単位で分割を推奨
・テーブルは日付分割がパフォーマンス向上が望める
・サードパーティ製のJDBCツールやSDK,APIでアクセス可能
料金
・データ保管料とクエリー課金
・クエリー課金は1Tバイトあたり課金と毎月定額課金
・データ保管料はCloudStorageと同じで1Gバイト単位課金
・クエリー課金は必要な分だけで、Athenaと異なる
セキュリティ
・IAMのほか、ACLでの制御が可能。一般公開も可能
・過去7日間の変更履歴をテーブルデコレコーダに保管可能
・Datastoreやcloud strage間のデータやり取りはセキュアNW
・BigQueryのAPI操作はすべてインターネット経由だが、HTTPSで
暗号化されている
3. Cloud Dataflow
概要
・バッチ、ストリーミングのどちらも対応可能なデータ処理パイプラインサービス
・入力データを読み込ませ、事前に準備したデータ変換処理を実行し、出力データを作成する
Cloud Dataflow プログラムの実行
・処理フローを設計し、実行するための環境構築する事前準備
パイプラインの実行
・構築したパイプラインへ、実データを渡し処理を行うこと
・パイプラインは「ジョブ単位」で実行される
・パイプラインを実行すると、GCPプロジェクト内で指定したVPC上にCompute Engineインスタンスが自動で起動し、パイプライン処理を実行
PCollection
・データの集合体を表すクラス
スケーリング
・ワーカーノードの最小と最大を指定可能
4. Cloud Dataproc
概要
・Hadoop,Sparkを使用する大規模分散処理
・フルマネージドサービスであり、初期設定を省くことができる
・GCPプロジェクト内に存在するVPC上にCompute Engineインスタンスが起動。インスタンスではHadoop/sparkが構築される
アーキテクチャ
・クラスタ構成
・「マスターノード」「ワーカーノード」「プリエンプティブノード」で構成される
・マスターノード:管理系プロセスが起動する
・ワーカノード/プリエンプティブノード:処理系プロセスが起動する
・プリエンプティブノード:データを保持することなく、処理のみを行う
5. Cloud Datalab
概要
・ブラウザを使用して、データ分析や可視化、機械学習などの分析プログラミングをインタラクティヴに実行可能
・データソースとしてGCPサービスを利用可能
・Jupyter Notebook
この記事が気に入ったらサポートをしてみませんか?