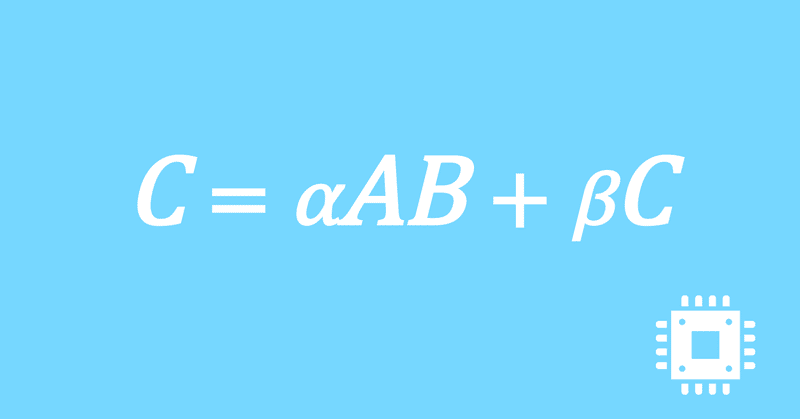
ベクトル化の設計|行列積高速化#16

この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
前述したように、コンパイラ最適化では効率的なベクトライズができないため、インラインアセンブラ機能でアセンブラ命令を直接使ってベクトライズを試みます。
そのためには、どの要素を同時に計算するかを設計しなければなりません。
設計のポイントは、処理全体の命令レイテンシーの合計値を可能な限り小さくすることです。なぜなら、総レイテンシー以上に速くすることはできない、すなわち計算速度の上限値を規定してしまうためです。
ここでは、処理回数が最も多い4x4x8アンローリングブロックの下記コードの部分の計算方法を検討します。
<ロード処理>
a00 = *(A2 + 0 + 0*4 ); a01 = *(A2 + 0 + 1*4 ); a02 = *(A2 + 0 + 2*4 ); a03 = *(A2 + 0 + 3*4 );
a10 = *(A2 + 1 + 0*4 ); a11 = *(A2 + 1 + 1*4 ); a12 = *(A2 + 1 + 2*4 ); a13 = *(A2 + 1 + 3*4 );
a20 = *(A2 + 2 + 0*4 ); a21 = *(A2 + 2 + 1*4 ); a22 = *(A2 + 2 + 2*4 ); a23 = *(A2 + 2 + 3*4 );
a30 = *(A2 + 3 + 0*4 ); a31 = *(A2 + 3 + 1*4 ); a32 = *(A2 + 3 + 2*4 ); a33 = *(A2 + 3 + 3*4 );
b00 = *(B2 + 0 + 0*4 ); b01 = *(B2 + 0 + 1*4 ); b02 = *(B2 + 0 + 2*4 ); b03 = *(B2 + 0 + 3*4 );
b10 = *(B2 + 1 + 0*4 ); b11 = *(B2 + 1 + 1*4 ); b12 = *(B2 + 1 + 2*4 ); b13 = *(B2 + 1 + 3*4 );
b20 = *(B2 + 2 + 0*4 ); b21 = *(B2 + 2 + 1*4 ); b22 = *(B2 + 2 + 2*4 ); b23 = *(B2 + 2 + 3*4 );
b30 = *(B2 + 3 + 0*4 ); b31 = *(B2 + 3 + 1*4 ); b32 = *(B2 + 3 + 2*4 ); b33 = *(B2 + 3 + 3*4 );
<演算処理>
c00 += a00 * b00; c00 += a01 * b01; c00 += a02 * b02; c00 += a03 * b03;
c01 += a00 * b10; c01 += a01 * b11; c01 += a02 * b12; c01 += a03 * b13;
c02 += a00 * b20; c02 += a01 * b21; c02 += a02 * b22; c02 += a03 * b23;
c03 += a00 * b30; c03 += a01 * b31; c03 += a02 * b32; c03 += a03 * b33;
c10 += a10 * b00; c10 += a11 * b01; c10 += a12 * b02; c10 += a13 * b03;
c11 += a10 * b10; c11 += a11 * b11; c11 += a12 * b12; c11 += a13 * b13;
c12 += a10 * b20; c12 += a11 * b21; c12 += a12 * b22; c12 += a13 * b23;
c13 += a10 * b30; c13 += a11 * b31; c13 += a12 * b32; c13 += a13 * b33;
c20 += a20 * b00; c20 += a21 * b01; c20 += a22 * b02; c20 += a23 * b03;
c21 += a20 * b10; c21 += a21 * b11; c21 += a22 * b12; c21 += a23 * b13;
c22 += a20 * b20; c22 += a21 * b21; c22 += a22 * b22; c22 += a23 * b23;
c23 += a20 * b30; c23 += a21 * b31; c23 += a22 * b32; c23 += a23 * b33;
c30 += a30 * b00; c30 += a31 * b01; c30 += a32 * b02; c30 += a33 * b03;
c31 += a30 * b10; c31 += a31 * b11; c31 += a32 * b12; c31 += a33 * b13;
c32 += a30 * b20; c32 += a31 * b21; c32 += a32 * b22; c32 += a33 * b23;
c33 += a30 * b30; c33 += a31 * b31; c33 += a32 * b32; c33 += a33 * b33;4x4x8アンローリングブロックは、上記の処理を2回行っていますが、同じコードなので1回分で検討します。
16-1. ロード処理のレイテンシーの見積もり
前節でアライメントを揃えたおかげで、ロード命令には最も高速なVMOVAPDを使うことができます。一方、Intel社のArchtecture Optimization Manualによると、L1キャッシュからのロード処理は最短で4サイクルかかると記載されています。そこで、ここでは全てのデータがL1キャッシュ上に存在するとして、ロード命令のレイテンシーを4サイクルとして見積もることにします。
対象コードで行われているロード処理は、行列Aが16個、行列Bが16個です。VMOVAPD命令は連続4要素を同時にロードするので、結果、行列Aのロード命令は16÷4=4つ、行列Bのロード命令も16÷4=4つ必要です。
また、Architecture Optimization Manualによると、Skylakeマイクロアーキテクチャでは、ロード演算器が2つ(Port2,3)存在します。これは、2つの命令を同時に実行可能なことを表すので、レイテンシーは半分になります。
したがって、ロード処理のレイテンシーは次のように見積もれます。
ロード処理のレイテンシーの見積もり
8(命令数)×4(1命令のレイテンシー)÷2(演算器数)=16サイクル
16-2. 演算処理のレイテンシーの見積もり
上記の対象コードは、全て積和計算なのでFMA命令を使って、4つの積和計算を1命令で処理することができます。Skylakeマイクロアーキテクチャでは、FMA命令のレイテンシー(LT)と逆スループット(TP)は、Intel社のマニュアルでは、次のように記載されています。
積和計算 All FMA Instructions : LT=4, TP=0.5
これによると、レイテンシーは4サイクル、すなわち処理が完全に終わるまでに4サイクルかかります。ただし、逆スループットの値から、1命令あたりの次の処理へ進める時間が1サイクル、処理可能な演算器が2つあるため平均0.5サイクルになると読み取れます。演算器が2つあると、2命令を同時に実行可能なので、総レイテンシーも半分になります。
対象コードの積和計算は16×4=64個あり、FMA命令で4個は同時に計算できるので、64÷4=16個のFMA命令で処理することができます。
したがって、演算処理の総レイテンシーは次のように計算できます。
演算処理の総レイテンシーの見積もり
16(命令数) × 4(1命令レイテンシー)÷2(演算器数)=32サイクル
16-3. 詰め替え処理のレイテンシーの見積もり
対象コードのロード処理と演算処理をよく比較するとわかるように、ロードした連続4要素をそのままの順序で積和計算に使用できるわけではありません。そのため、ロード処理と演算処理をつなぐために、レジスタ間のデータの詰め替え処理が必要になります。
ただし、上述の演算処理の順序では、[c00,c01,c02,c03]の計算をワンセットにしたくなりますが、行列Cにとってこのデータの並びはストライドアクセス方向になっています。ここでは、行列Cへのストア処理を簡単にできるように、シーケンシャルアクセス方向である[c00,c10,c20,c30]の計算をワンセットにできる順序に並び替えて検討してみます。

上図は、行列Cに直接ストアできるようにシーケンシャルアクセス方向に処理を並べた場合です。これによると、行列Aの4要素はロードしたデータ順のまま使用することができます。
しかし、行列Bについては、ロードした4要素について、1要素ずつを充填したレジスタを4つ用意しなければなりません。そのため、行列Bはレジスタ間の詰め替え処理が必要になります。そこで、この詰め替え処理が可能なアセンブラ命令を探索します。
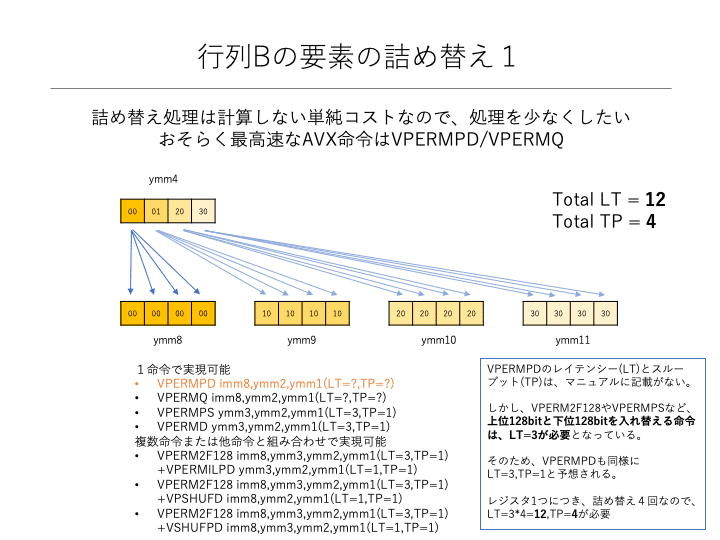
一度に4つのレジスタに書き込む命令は存在しないので、同じ処理を4回繰り返すことで4つのレジスタにデータを詰め替えます。
Intel社のSoftware Development Manualを調べたところ、1つの処理を1命令で実現できる命令は、VPERMPD、VPERMQ、VPERMPS、VPERMDの4つ命令がありました。また、VPERM2F128命令とVPERMILPD、VPSHUFD、VSHUFPD命令のいずれかを使用すれば、1処理を2命令でも実現できる見込みでした。
VPERMILPD、VPSHUFD、VSHUFPD命令が1命令で処理できないのは、上位128ビットと下位128ビットを詰め替えることができないためです。そのため、上位128ビットと下位128ビットを詰め替えるVPERM2F128命令と組み合わせる必要があります。
しかし、わざわざ2命令を使って処理遅延の可能性を大きくする必要はないので、1命令で実現できる命令群から処理に使用する命令を選択します。その命令群の各命令は、下記の通り対象とするデータ型が異なります。
VPERMPD 64ビット浮動小数点データ用(倍精度浮動小数点)
VPERMQ 64ビット整数データ用
VPERMPS 32ビット浮動小数点データ用(単精度浮動小数点)
VPERMD 32ビット整数データ用
今回は、倍精度浮動小数点を扱っているため、VPERMPD命令を選択します。
さて、VPERMPD命令のレイテンシー(LT)と逆スループット(TP)は、実はマニュアルに記載がありません。しかし、上位128ビットと下位128ビットの詰め替えが可能な命令のVPERMPS命令、VPERMD命令、VPERM2F128命令は、全てLT=3、TP=1と記載されていますので、VPERMPD命令も同様と推定できます。
なお、上位128ビットと下位128ビットの詰め替えができないVPERMILPD命令、VPSHUFD命令、VSHUFPD命令は、全てLT=1、TP=1となっています。このことから、128ビット境界を跨がない詰め替えは高速に処理可能と分かります。
また、TP=1より、処理できる演算器は1つしかなく、複数の命令が同時実行されることはないと考えられます。
以上により、詰め替え処理のレイテンシーは次のようになります。
詰め替え処理のレイテンシー
4(Bのレジスタ数)×4(命令数)×3(命令レイテンシー)=48サイクル
16-4. レイテンシーの削減
前述までのレイテンシーの見積もりをまとめると、次のようになります。
4x4x8アンロールブロックの処理(の半分)のレイテンシー
(1)ロード処理 16サイクル
(2)演算処理 32サイクル
(3)詰め替え処理 48サイクル
単純合計 96サイクル
処理(1)〜(3)は実行する演算器が異なるので、本来、単純に合計はできませんが、単純合計の50%を(計算上は不要な)詰め替え処理が占めているのは多すぎます。そこで、(3)詰め替え処理をもう少し短縮できないか考えることにします。
前述したとおり、YMMレジスタの上位128ビットと下位128ビットを入れ替える置換命令は、レイテンシーが3サイクルでした。VPERMPD命令もこれに従うものと予想しました。しかし、上位128ビットと下位128ビットを入れ替えない置換命令であれば、レイテンシーは1サイクルでした。
ということは、上位128ビットと下位128ビットを入れ替えなくても良い計算方法にできれば、詰め替え処理のレイテンシーを削減することができるはずです。そのために、計算の組み合わせから見直します。

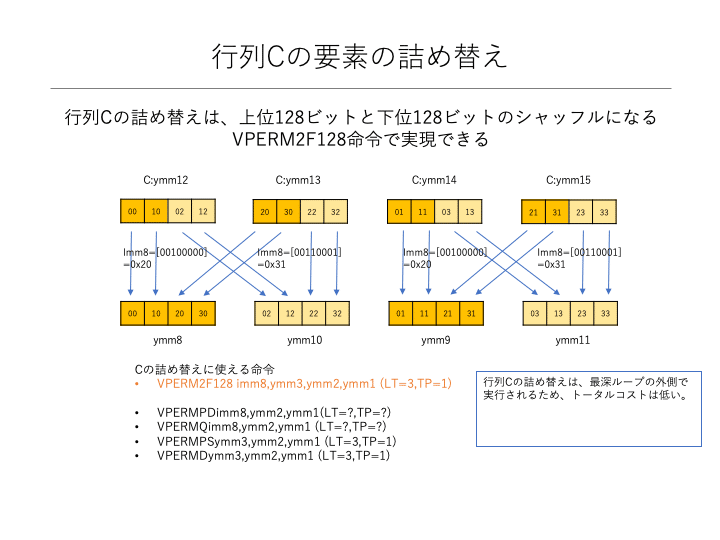
上図では、行列Cに相当するレジスタの並び順をストア順にすることを諦めました。しかし、行列Cのレジスタの詰め替え処理は、最深ループを脱した後のストア処理の直前で行うことができるため、処理量増加の影響は軽微で済むと考えられます。なお、行列Cの詰め替え処理には、VPERM2F128命令を使用することができます。(下図参照)
次に、行列Aに相当するレジスタの要素も、ロードされた順序とは異なるため、詰め替え処理が必要になります。しかも、これは上位128ビットと下位128ビットを跨いだ詰め替えになっているため、レイテンシー3サイクルの命令を使う必要があります。ただし、2要素ずつの詰め替えになるため、アセンブラ命令は1レジスタ(4要素)につき2回、すなわち前述の方法に比べて半分の命令数で実現できます。
上記の計算の組み合わせのポイントは、行列Bの詰め替え処理が上位128ビットと下位128ビットを跨がない点です。これにより、詰め替え処理自体は必要ですが、レイテンシーが1サイクルの命令で実行できます。こちらも、2要素ずつの詰め替えなので、アセンブラ命令は1レジスタにつき2回で処理を行うことができます。
行列Aと行列Bの詰め替え処理に使用するアセンブラ命令を検討した結果、行列Aの詰め替えはVPERM2F128命令で、行列Bの詰め替えはVSHUFPD命令で実行可能でした。
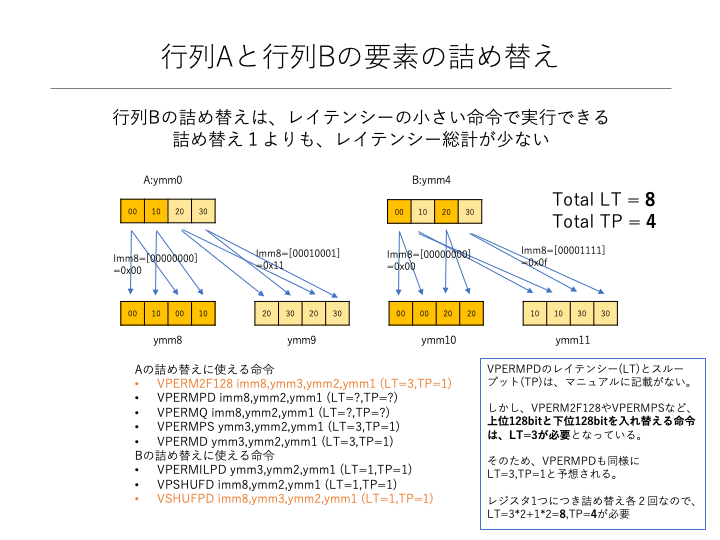
これらの命令を使ったレイテンシー合計値は次のようになります。
詰め替え処理のレイテンシーの見積もり
行列A:4(レジスタ)×2(レジスタあたり命令数)×3(レイテンシー)=24
行列B:4(レジスタ)×2(レジスタあたり命令数)×1(レイテンシー)=8
単純合計 32サイクル
結果として、レイテンシーの合計は次のようになりました。
4x4x8アンロールブロックの処理(の半分)のレイテンシー
(1)ロード処理 16サイクル
(2)演算処理 32サイクル
(3)詰め替え処理 32サイクル
単純合計 80サイクル
16-5. アセンブラ命令数の削減
上記までで、詰め替え処理のレイテンシーを48サイクルから32サイクルに削減することができました。しかし、これ以上は命令の入れ替えだけでレイテンシーを削減することは難しそうです。例えば、行列Aの詰め替え処理をVSHUFPD命令のようなレイテンシー1サイクルの命令に置換できれば、さらにレイテンシーを下げられそうですが、その場合は、行列Bの詰め替え処理が1サイクルの命令ではできなくなります。
そこで、命令数を減らす方法を考えます。
マニュアルをよく見ると、128ビットのデータをメモリから読み込み、YMMレジスタに上位128ビットと下位128ビットに書き込む命令VBROADCASTF128が存在します。この命令を使えば、行列Aの2要素を読み込み、必要な配置[a00,a10,a00,a10]を持ったYMMレジスタを1命令で作り出すことができます。
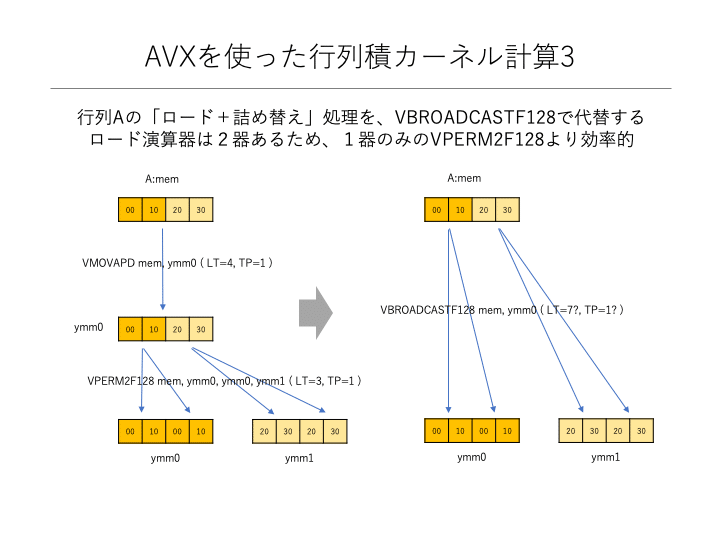
ただし、128ビットずつ読み込むため、行列Aのロード相当命令は2倍(4→8)に増えてしましいます。その代わり、詰め替え処理が不要(8→0)になります。結果として、命令数は+4−8=−4個だけ削減されます。これにより、逆スループットも4サイクル削減されます。
VBROADCASTF128命令のレイテンシーは、マニュアルに記載がありませんが、L1キャッシュからのロード命令(LT=4)+128ビット境界越え置換命令(LT=3)から、最悪の場合で7サイクル程度ではないかと推測できます。最良の場合は、置換命令なしで実行できる実装を想定して、4サイクル程度と推測します。最悪の場合は、ロード+詰め替え処理と同じレイテンシーのため全く効率化されていません。
しかしながら、置換命令が演算器1器で実行可能(推定)なのに対し、ロード演算器は2器存在するため2命令の同時実行が可能です。その分だけ、処理が効率化されると予想できます。
推定の結果、ロード命令のレイテンシーは次のように見積もれます。
ロード処理のレイテンシーの見積もり(最悪の場合)
行列A:8(命令数)×7(命令レイテンシー)÷2(演算器数)=28
行列B:4(命令数)×4(命令レイテンシー)÷2(演算器数)=8
単純合計 36サイクル
ロード処理のレイテンシーの見積もり(最良の場合)
行列A:8(命令数)×4(命令レイテンシー)÷2(演算器数)=16
行列B:4(命令数)×4(命令レイテンシー)÷2(演算器数)=8
単純合計 24サイクル
また、詰め替え処理のレイテンシーは次のように見積もれます。
詰め替え処理のレイテンシーの見積もり
行列A:0
行列B:4(レジスタ)×2(レジスタあたり命令数)×1(レイテンシー)=8
単純合計 8サイクル
以上より、4x4x8アンロールブロックの半分の処理のレイテンシーは、次のように見積もることができます。
4x4x8アンロールブロックの処理(の半分)のレイテンシー
(1)ロード処理 24~36サイクル
(2)演算処理 32サイクル
(3)詰め替え処理 8サイクル
単純合計 64~76サイクル
16-6. 最高性能比率の推定
これより、同時実行が一切できない場合は、上記の処理(1)〜(3)を逐次実行するので、処理時間は単純合計の64~76サイクルになります。しかし、処理(1)〜(3)は、下記の通り、全て別の演算器で実行可能です。そのため、完全に同時実行された場合の処理時間は、Max( 24~36, 32, 8 )=32~36サイクル程度になります。
4x4x8アンロールブロックの処理と演算器(Port)
(1)ロード処理 Port 2, Port 3
(2)演算処理 Port 0, Port 1
(3)詰め替え処理 Port 5
演算性能比は全体の処理時間に対する演算処理時間の比率なので、レイテンシーの情報から予測することができます。
演算性能比の予測値
完全逐次実行 32サイクル ÷ 64~76サイクル = 42~50%
完全同時実行 32サイクル ÷ 32~36サイクル = 89~100%
VBROADCASTF128命令のレイテンシー次第ですが、最低でも42%程度、最高だと100%の性能が出る見込みです。
100%に到達できる見込みができたので、アセンブラ命令は以上で確定にしたいと思います。
次の記事
元の記事はこちらです。
ソースコードはGitHubで公開しています。
この記事が気に入ったらサポートをしてみませんか?