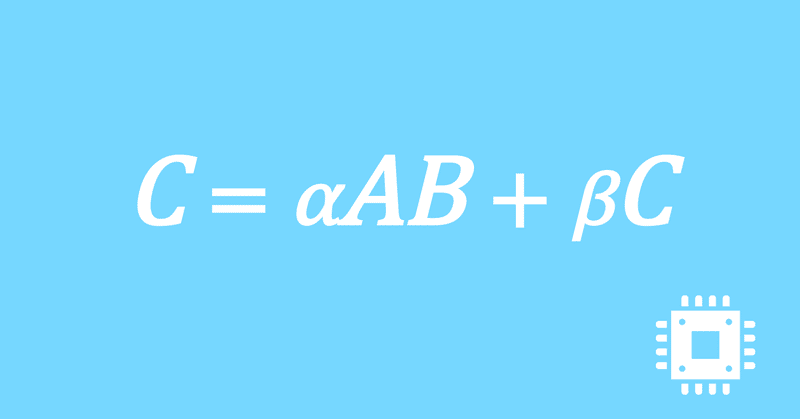
プリフェッチの挿入|行列積高速化#18

この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
次に、メインメモリからキャッシュメモリにデータを運んでおくために、プリフェッチを挿入します。プリフェッチには、ハードウェア・プリフェッチとソフトウェア・プリフェッチがあります。
ハードウェア・プリフェッチ = CPUが自動的に行うプリフェッチ
ソフトウェア・プリフェッチ = プリフェッチ命令で行うプリフェッチ
プリフェッチ命令は自由に挿入できますが、命令の1つなので命令処理コストがかかります。そのため、なるべく挿入しない方が効率的です。
18-1. ハードウェア・プリフェッチャー
Intel社の最適化マニュアルを見ると、L1キャッシュにはプリフェッチャーが1つ、L2キャッシュには2つ装備されていることが分かります。
(L1)DCU
(L2)Streamer
(L2)DPL(Data Prefetch Logic)
DCUは、L2キャッシュのデータをL1キャッシュに転送するプリフェッチャーです。データが存在しない場合、StreamerとDPLを起動します。
Streamerは、L3キャッシュのデータをL2キャッシュに転送するプリフェッチャーです。Streamerは、データをアラインメントされた128Bブロック(キャッシュライン×2)と認識していて、2つキャッシュラインのどちらか一方へファーストアクセスした場合にも起動します。
DPLは、L2キャッシュミスを観測しているプリフェッチャーです。データ読み込み処理で起動し、L2キャッシュミスが発生するとStreamerを起動します。
ソフトウェア・プリフェッチは、プリフェッチ命令を使って、これらを意図的に起動します。
18-2. ソフトウェア・プリフェッチ
プリフェッチ命令は、全部で5種類あり、キャッシュ階層のどこにデータを配置しておくかで、それぞれ動作が異なります。

prefetcht0 = 全階層へデータを書き込み
prefetcht1/2 = L1キャッシュへは書き込まない
prefetchnta = L2キャッシュへは書き込まない
prefetchw = 全階層へデータを書き込み(skylake以降)
基本的には、全キャッシュ階層へデータを書き込むprefetcht0命令を使えば良いと思います。その他は、アルゴリズムに応じて使い分けます。
18-3. プリフェッチの戦略
ソフトウェア・プリフェッチを挿入する戦略は、次のように考えます。
(1)ハードウェア・プリフェッチに可能な限り任せる
(2)ハードウェア・プリフェッチができないプリフェッチを仕込む
(3)無駄なハードウェア・プリフェッチを抑止する
要約すると、ハードウェア・プリフェッチを補完するようにソフトウェア・プリフェッチを仕込んでいきます。
基本的には、ストライド・アクセスの場合やメモリアクセスがジャンプする場合、飛び先のデータをプリフェッチしておきます。
シーケンシャル・アクセスのデータは、ハードウェア・プリフェッチが有効に働くので、L2キャッシュ容量を超えるような場合でない限り、ソフトウェア・プリフェッチを挿入する必要はありません。
L2キャッシュ容量を超える場合には、メインメモリまでデータを取りに行くため、連続メモリのかなり離れた先のデータをプリフェッチすると高速化される可能性があります。
今回は、L1キャッシュ・ブロッキングを行っているため、最初のメモリアクセス以外、キャッシュにデータが保存されていることが予想されます。そのため、問題は最初のメモリアクセスになります。
ハードウェア・プリフェッチは、キャッシュラインへのファースト・アクセスが行われると起動するので、ファースト・アクセスを早めに起こすように書き換えます。その方針は、下記の通りです。
バッファAとバッファB
L1キャッシュブロッキングされたシーケンシャルアクセスなので、メインループ内でのプリフェッチは不要。ファースト・アクセスを早めるため、ポインタアドレスを少し先に動かし、ソフトウェア・プリフェッチを1回だけ実施されるように挿入する。(正直、効果はわからないですが・・・)
行列C
4x4ブロックは、列方向にストライド・アクセスになるため、ソフトウェア・プリフェッチを挿入する。
この方針では、ループ最深部には手を加えず、次のようにプリフェッチを挿入しました。
<変更前>
// ---- Kernel
if( N >> 2 ){
size_t n4 = ( N >> 2 );
while( n4-- ){
if( M >> 2 ){
size_t m4 = ( M >> 2 );
while( m4-- ){
__asm__ __volatile__ (
"\n\t"
"vpxor %%ymm12, %%ymm12, %%ymm12\n\t"
"vpxor %%ymm13, %%ymm13, %%ymm13\n\t"
"vpxor %%ymm14, %%ymm14, %%ymm14\n\t"
"vpxor %%ymm15, %%ymm15, %%ymm15\n\t"
::);
if( K >> 3 ){
size_t k8 = ( K >> 3 );
while( k8-- ){
<変更後>
A += 32; // *1
B += 32;
__asm__ __volatile__ ( // *1
"\n\t"
"prefetcht0 -32*8(%[a])\n\t"
"prefetcht0 -32*8(%[b])\n\t"
::[a]"r"(A),[b]"r"(B)
);
// ---- Kernel
if( N >> 2 ){
size_t n4 = ( N >> 2 );
while( n4-- ){
if( M >> 2 ){
size_t m4 = ( M >> 2 );
while( m4-- ){
__asm__ __volatile__ ( // *2
"\n\t"
"prefetcht0 0*8(%[c0] )\n\t"
"prefetcht0 0*8(%[c1] )\n\t"
"prefetcht0 0*8(%[c0],%[ldc2])\n\t"
"prefetcht0 0*8(%[c1],%[ldc2])\n\t"
::[c0]"r"(c0),[c1]"r"(c1),[ldc2]"r"(ldc2)
);
__asm__ __volatile__ (
"\n\t"
"vpxor %%ymm12, %%ymm12, %%ymm12\n\t"
"vpxor %%ymm13, %%ymm13, %%ymm13\n\t"
"vpxor %%ymm14, %%ymm14, %%ymm14\n\t"
"vpxor %%ymm15, %%ymm15, %%ymm15\n\t"
::);
if( K >> 3 ){
size_t k8 = ( K >> 3 );
while( k8-- ){ まず、ループを入る前に、ハードウェア・プリフェッチャーの早期起動(*1)を試みています。ただ、効果はあまり保証できません。次に、最深Kループに入る直前で、行列Cをプリフェッチ(*2)しています。Kループが実行されている間に、メモリからキャッシュへのデータ転送が完了することを期待して、この位置に挿入しています。
18-4. 性能測定
性能を測定してみると、24.0 GFLOPS → 24.7 GFLOPSとわずかに高速になりました。ただ、全体が高速になったため、一回一回の測定では、ちょっとした経過時間の違い(例えば、0.01秒のズレ)の影響が大きくなってしまっています。高速になったように見えるのは、このズレの影響かもしれません。
<変更前>
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 4.50611E-05, 198.841, 0.428537, 0.376593
32, 1.69277E-05, 4053, 8.73491, 7.67613
64, 0.000106096, 5057.44, 10.8997, 9.57849
128, 0.000432968, 9800.85, 21.1225, 18.5622
256, 0.00235105, 14355.8, 30.9391, 27.1889
512, 0.0146499, 18377.1, 39.6058, 34.8051
1024, 0.09536, 22552.7, 48.605, 42.7135
2048, 0.715291, 24035.6, 51.8009, 45.522
<変更後>
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 4.69685E-05, 190.766, 0.411134, 0.3613
32, 1.90735E-05, 3597.04, 7.75223, 6.81257
64, 0.000111103, 4829.53, 10.4085, 9.14684
128, 0.000569105, 7456.37, 16.0698, 14.1219
256, 0.00185299, 18214.4, 39.2551, 34.4969
512, 0.011873, 22675.1, 48.8688, 42.9453
1024, 0.0978489, 21979.1, 47.3687, 41.6271
2048, 0.69475, 24746.2, 53.3324, 46.8679 次の記事
元の記事はこちらです。
ソースコードはGitHubで公開しています。
この記事が気に入ったらサポートをしてみませんか?