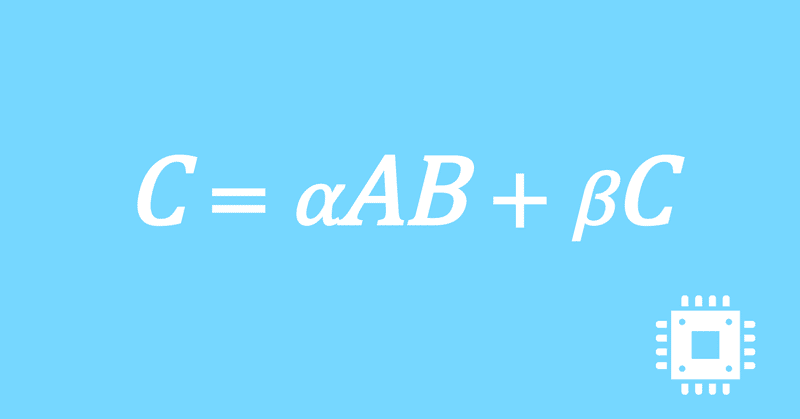
行列スケール関数のテストプログラム作成|行列積高速化#22

この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
スケール関数は、下記の計算に使用します。
C = beta * C
コピー関数と同様に、スケール関数も2つのテストプログラムを作成しておきます。
(1)処理結果確認プログラム・・・正解値と処理結果の比較
(2)処理速度測定プログラム・・・処理時間を測定
22-1. テスト用構造体
行列積のテストプログラムと同様に、テストに必要な関数と引数をまとめた構造体を用意します。
typedef void(scale2d_func_t)(double beta, double *C, size_t ldc, const block2d_info_t* info );
typedef struct _scale2d_test_t {
scale2d_func_t * func;
double beta;
double *C;
size_t ldc;
block2d_info_t* info;
} scale2d_test_t;コピー関数と同様に、スケール関数の関数ポインタ型scale2d_func_tを定義しています。行列のサイズ情報はblock2d_info_t構造体を再利用しています。
22-2. 処理結果確認プログラム
現在の関数を別名で保存しておき、同じ結果が得られれば正解と判定するようにします。処理結果の比較は、出力が行列になるので、行列積用に作成したcheck_matrix関数で行います。丸め誤差は発生しないので、√K=1となるように、K=1を固定で与えてあります。
実際のプログラムコードは次の通りです。
#define MAX_SIZE 1023
#define SEED 13892393
static void do_scale2d( scale2d_test_t *test ){
test->func( test->beta, test->C, test->ldc, test->info );
}
static int scale2d_check_error( const scale2d_test_t *test1, const scale2d_test_t *test2 ){
return check_matrix( test1->info->M2, test1->info->N2, 1,
test1->C, test1->ldc, 1, test2->C, test2->ldc, 1 );
}
int main( int argc, char** argv ){
block2d_info_t sizes={0,0,MAX_SIZE,MAX_SIZE,1,1};
scale2d_test_t test1={myblas_basic_scale2d,0e0,NULL,MAX_SIZE,&sizes};
scale2d_test_t test2={myblas_dgemm_scale2d,0e0,NULL,MAX_SIZE,&sizes};
double beta = 1.3923842e0;
double* C1 = calloc(MAX_SIZE*MAX_SIZE,sizeof(double));
double* C2 = calloc(MAX_SIZE*MAX_SIZE,sizeof(double));
rand_matrix(MAX_SIZE,MAX_SIZE,C1,MAX_SIZE,1,SEED);
C2 = memcpy(C2,C1,MAX_SIZE*MAX_SIZE*sizeof(double));
test1.beta = beta;
test1.C = C1;
test1.ldc = MAX_SIZE;
test2.beta = beta;
test2.C = C2;
test2.ldc = MAX_SIZE;
do_scale2d( &test1 );
do_scale2d( &test2 );
int error = scale2d_check_error( &test1, &test2 );
if( error ){ printf("NG\n"); }else{ printf("OK\n"); }
free(C1);
free(C2);
return error;
}
プログラムの内容は、コピー関数のテストプログラムとほぼ同じです。異なる点は、下記になります。
1.処理結果が行列なので、行列用のエラーチェック関数を呼び出している
2.実行時オプション処理は不要なので、記述されていない
3.入力と出力が同じ行列なので、初期化済みの行列C1をC2にコピーしている
22-3. 処理速度測定プログラム
スケール関数もメモリアクセスで律速するため処理性能はB/sで測定することにします。
#define MAX_SIZE 2048
static void do_scale2d( scale2d_test_t *test ){
test->func( test->beta, test->C, test->ldc, test->info );
}
int main( int argc, char** argv ){
block2d_info_t sizes={0,0,MAX_SIZE,MAX_SIZE,1,1};
scale2d_test_t test ={myblas_dgemm_scale2d,0e0,NULL,MAX_SIZE,&sizes};
double beta = 1.3923842e0;
double* C = calloc(MAX_SIZE*MAX_SIZE,sizeof(double));
test.beta = beta;
test.C = C;
test.ldc = MAX_SIZE;
int error = 0;
printf("size , elapsed time[s], copy size[KB], MFLOPS, MB/s, B/FLOP \n");
for( size_t n=16; n <= MAX_SIZE; n*=2 ){
test.info->M2 = n;
test.info->N2 = n;
init_matrix(test.info->M2, test.info->N2, test.C, test.ldc, 1, 1e0 );
double t1 = get_realtime();
do_scale2d( &test );
double t2 = get_realtime();
double dt = t2 - t1;
double mflop = ((double)test.info->M2) *((double)test.info->N2) / (1024*1024);
double bytes = test.info->M2 * test.info->N2 * sizeof(double);
printf("%6u, %15G, %15G, %15G, %15G, %15G \n",n,dt,bytes/1024,mflop/dt,bytes/dt/(1024*1024),bytes/(mflop*1024*1024));
}
free(C);
return error;
}こちらも、行列積計算のテストプログラムと同様に、一辺のサイズ16~2048の行列で測定しています。
22-4. 性能測定
このプログラムの出力結果は次のとおりです。
size , elapsed time[s], copy size[KB], MFLOPS, MB/s, B/FLOP
16, 9.53674E-07, 2, 256, 2048, 8
32, 1.90735E-06, 8, 512, 4096, 8
64, 5.00679E-06, 32, 780.19, 6241.52, 8
128, 1.88351E-05, 128, 829.57, 6636.56, 8
256, 4.48227E-05, 512, 1394.38, 11155.1, 8
512, 0.000246048, 2048, 1016.06, 8128.5, 8
1024, 0.000724077, 8192, 1381.07, 11048.5, 8
2048, 0.00917411, 32768, 436.01, 3488.08, 8 スケール計算は、下記のとおり、乗算処理があるためFLOPSも計算しています。
C = beta * C
しかし、演算量がメモリアクセスに比べて少ないので、あまり参考にはなりません。B/sの方で見ると、だいたい11.1GB/sほど出ているようです。
最終カラムのB/Fは、Byte per FLOPの略で、メモリアクセスと演算処理のどちらが優位かを調べるときに使う指標です。B/Fが大きいほどメモリアクセス依存、B/Fが小さいほど演算処理に依存しています。B/F=1を境界とすると、今回はB/F=8なのでメモリアクセス依存となります。
次の記事
元の記事はこちらです。
ソースコードはGitHubに公開しています。
この記事が気に入ったらサポートをしてみませんか?