
行列積計算を高速化してみる

超高性能プログラミング技術のメモ(15)
実は、このメモは、行列-行列積計算C=ABを高速化するために必要な技術を記録してきました。今回は、いよいよその行列積計算の高速化に挑みたいと思います。
行列積DGEMMは、HPC業界ではTop500ランキングでもベンチマークプログラムとして使われていて、今でも世界最高速が競われています。近年は、ディープラーニングの畳み込み計算などにも利用されているようで、あまり表には出てきませんが、様々なプログラムの裏方として頑張っているアルゴリズムになります。
しかし、行列積の高速な実装はあるものの(下記記事でご紹介済み)、HPCで必要とされる行列積の高速化方法はどこにも解説が見当たりません。Qiitaにも行列積を高速化する記事がいくつかありますが、理論性能の約50%しか出せていないようです。しかし、HPC業界で世界一位を競うには、理論性能の96%以上が必要になります。
実は、10年ほど前、個人的に行列積計算の高速化について取り組み、高速な実装にたどり着くまでを何となくプロセスにしました。この記事では、そのプロセスを辿りつつ、再度実装に取り組むことで、高速な行列積計算を誰でも実装できるように書き残していきたいと思っています。
また、恐縮ですが、途中から今回は有料記事にします。価格は、理論性能の10%達成までは100円、50%を達成したら500円、100%を達成したら1000円というように、達成した性能の10倍で設定させてください。
徐々に更新していくので、早めに購入していただくと安く見ることができます。もし、途中で高速化を諦めれば、それ以上値上がりしません。また、早く購入した方が損をしないように、もし性能が落ちても値下げは行いません。
これまでの経験上、最初は低空飛行していますが、ある段階を超えると急に性能が上がります。そのため、ある時期に、急に値上がりすることが予想されます。
更新履歴
2020年7月31日 初版公開
2002年8月2日 テストプログラムの作成2を追記
2020年8月4日 アンローリング1〜4を追記、コア関数化を追記
2020年8月5日 ベクトライズ1を追記
2020年8月12日 行き詰まったためアンローリング以降を刷新、性能は低下
2020年8月13日 インラインアセンブラ、アライメントを追記
2020年8月15日 ベクトライズの設計を追記
2020年8月16日 ベクトライズの実装を追記
2020年8月30日 高速化の全工程を完了
最終性能
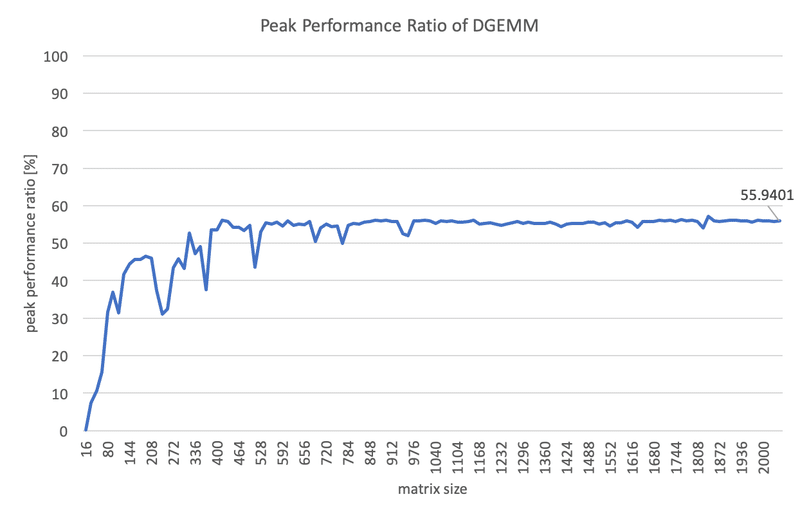
最終的に、理論ピーク性能の約56%になりました。当初のプログラムと比較するとおよそ187倍に高速化したことになります。もう少し高速にしたいところですが、想定していた手続きは全て完了したので、これを最終結果としたいと思います。
ソースコード
後日、もう少し高速化して93%程度になりました。
この記事があまりにも長くなってしまったので、章ごとに分割してマガジンにまとめました。
1. 評価環境 [無料]
使用するコンピュータは、手元のMacBook Proを使います。カタログスペックは、バッテリーが壊れた際に知ったシステム情報を見ると、次のとおりでした。
機種名 :MacBook Pro
CPU :Dual-Core Intel Core i5
動作周波数 :2.9GHz
プロセッサ数:1
コア数 :2
SMT :有効
L1キャッシュ:32KB
L2キャッシュ:コアあたり256KB
L3キャッシュ:4MB
明示されていませんが、購入時期から考えて、CPUのマイクロアーキテクチャはSkylake Microarchitecture(最新資料だと、Skylake Client Microarchitecture)だと思われます。
動作周波数は、CPUIDの情報だと基本が2.9GHz、最大が3.3GHzに設定されていました。CPU使用量が増加すると、Tarbo Boost テクノロジーによって、自動的に動作周波数が上がる可能性があります。
コア数は2個ありますが、まずは1コア性能を向上させたいと思います。SMT(ハイパー・スレッディング・テクノロジー)は、正しく性能を測るためには無効にした方がいいのですが、方法がわからないのでこのままにします。
コンパイル環境には、Xcodeをインストールした上で、brewコマンドでgcc 10.1.0及びgfortranをインストールしました。/usr/local/bin/gccは、当初clangにリンクされているので、これをインストールしたgccに置き換える必要があります。
$ brew install gcc
$ brew install gfortran
$ rm /usr/local/bin/gcc; ln -s /usr/local/bin/gcc-10 /usr/local/bin/gcc最適化オプションは、-O3を使用します。
2. 理論性能の計算 [無料]
理論性能の計算方法については、下記の記事で解説しています。
ここでは、評価マシンであるMacBook Proの理論性能を計算してみましょう。しかし、毎回手で計算するのは面倒ですので、前回作成したCPUIDプログラムを使って、プログラムにしてしまいます。
まず、FLOPS値をいつでも再計算できるように、必要な情報を格納する構造体を作りました。
typedef struct _flops_info_t {
size_t base_freq;
size_t max_freq;
size_t num_cores;
size_t fp_operator;
size_t fp_operation;
size_t vlen_bits;
double mflops_single_base;
double mflops_single_max;
double mflops_double_base;
double mflops_double_max;
} flops_info_t;まず、base_freqとmax_freqは、CPUの動作周波数の基本周波数と最大周波数を格納する変数です。これらは、全てMHz単位で取得されます。
num_coresは、コア数です。コア数が2倍になると理論性能も2倍になるため、理論性能の計算に必要になります。
fp_operatorは、浮動小数点演算器の個数です。これは、CPUのマイクロ・アーキテクチャに依存します。Intel製CPUでは、Skylake Microarchitectureまでは、Port 0(ADD)とPort 1(MUL)の2個でした。Skylake Server Microarchitectureでは、少し増えているみたいです。
fp_operationは、浮動小数点演算器で1回に計算できる演算数です。ADDやMULは1回につき1演算ですが、FMA(Fused Multiply and Add)は1回でADD/MULの両方を計算するため、1回につき2演算となります。
vlen_bitsは、ビット単位のベクトル長です。ベクトル長は、一命令で同じ演算をするデータ数なので、理論性能の計算に必要です。ベクトル長は、拡張命令セットが更新されるたびに長くなっています。MMXでは64ビット、SSE2で128ビット、AVXで256ビット、AVX512で512ビット、という具合です。
Mflops_single_baseとMflops_single_maxは、単精度不動小数点(float型)演算の場合のMFLOPS値です。2種類の動作周波数に合わせて、2つの値を用意しています。mflops_double_baseとMflops_double_maxは、倍精度不動小数点(double型)演算のMFLOPS値です。
これらをCPUIDの値から計算するプログラムは、下記の通りです。
void peak_flops( flops_info_t* out ){
cpuid_info_t info;
read_cpuid_info( &info );
// Frequency (MHz)
size_t base_freq = info.proc_freq_info.proc_base_freq;
size_t max_freq = info.proc_freq_info.max_freq; // on Tarbo Boost
// Number of cores
size_t num_cores = 0;
for( int i=0; i< info.num_tplevel; i++ ){
num_cores += info.topology[i].num_log_procs;
}
// Number of Floting-point operators
size_t fp_operator = 2;
// Floting-point Operations in an operator
size_t fp_operation = 1;
if( info.basic_info.features[0] & F_FMA ){ fp_operation = 2; }
// Vector length
size_t vlen_bits = 0;
if( info.basic_info.features[1] & F_MMX ){ vlen_bits = 64; } // introduced MM registers
if( info.basic_info.features[1] & F_SSE2 ){ vlen_bits = 128; } // introduced XMM registers
if( info.more_feature[0].features[1] & F_AVX2 ){ vlen_bits = 256; } // introduced YMM registers
if( info.more_feature[0].features[1] & F_AVX512F ){ vlen_bits = 512; } // introduced ZMM registers
out->base_freq = base_freq;
out->num_cores = num_cores;
out->max_freq = max_freq;
out->fp_operator = fp_operator;
out->fp_operation = fp_operation;
out->vlen_bits = vlen_bits;
out->mflops_single_base = num_cores * fp_operator * fp_operation * (vlen_bits/(8*sizeof(float))) * base_freq;
out->mflops_single_max = num_cores * fp_operator * fp_operation * (vlen_bits/(8*sizeof(float))) * max_freq;
out->mflops_double_base = num_cores * fp_operator * fp_operation * (vlen_bits/(8*sizeof(double))) * base_freq;
out->mflops_double_max = num_cores * fp_operator * fp_operation * (vlen_bits/(8*sizeof(double))) * max_freq;
}コア数の計算とvlen_bitsを浮動小数点型要素数に変換する処理がやや面倒ですが、それ以外は前段で説明したことをそのままプログラムに直しています。
vlen_bitsは、ビット単位をバイト単位に直すために8で割り、バイト単位を浮動小数点型の要素単位に直すためにsizeof(float)やsizeof(double)で割っています。
ここで使用しているCPUIDのデータを取得するプログラムは、下記の記事をご覧下さい。
さて、上記のpeak_flops関数を使って、MacBook Proの1コア理論ピーク性能を計算してみると、次のとおりでした。
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops これによって、基本周波数で動作している時は46.4GFlops、最大周波数で動作している時は52.8GFlopsと分かりました。
3. テストプログラムの作成 [無料]
プログラムの高速化をしていると、間違った変更をしてしまいがちです。また、計算速度がどのくらいになっているのかを随時確認する必要もあります。そこで、以下の2つのテストプログラムを作成しました。
(1)計算結果を確認するプログラム:unit_test
(2)計算速度を確認するプログラム:speed_test, total_test
計算速度を確認するプログラムが2つありますが、speed_testは簡易的に確認するため、total_testはグラフ描画用に細かく測定するために作成しています。プログラム自体は、ループの刻み幅が粗いか細かいかを除いて、ほとんど同じです。
テストプログラムの実装を考える前に、いろいろ準備する必要があります。
3-1. 正解値の準備
計算結果を確認するには、正解値が必要です。今回は、正解としてNetlib.orgで公開されているBLASライブラリを使用します。もし、システムにBLASライブラリがパッケージとしてインストールされている場合は、それを使用しても構いません。
BLASは、Fortran言語用のライブラリです。しかし、今回はC言語インターフェースを使用したいので、上記ページからダウンロードできるcblas.tgzもコンパイルして使用します。
3-2. インターフェースの準備
行列積DGEMMは引数が多く、これを毎回記述するのは大変なので、次のような構造体を用意しておきます。
typedef void (*dgemm_func_t)
(const enum CBLAS_ORDER Order, const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB, const int M, const int N,
const int K, const double alpha, const double *A,
const int lda, const double *B, const int ldb,
const double beta, double *C, const int ldc);
typedef struct _dgemm_test_t {
dgemm_func_t dgemm;
enum CBLAS_ORDER Order;
enum CBLAS_TRANSPOSE TransA;
enum CBLAS_TRANSPOSE TransB;
int M;
int N;
int K;
double alpha;
double* A;
int lda;
double* B;
int ldb;
double beta;
double* C;
int ldc;
} dgemm_test_t;dgemm_func_tは、CBLASのDGEMM関数の関数ポインタ型です。これは、cblas.hに記載されているCblas_dgemm関数を参考に作成しています。なぜ、関数ポインタ型を定義しているかというと、正解の関数と自作の関数を、テストプログラムで差し替えられるようにするためです。
dgemm_test_tは、テストプログラム内で利用するDGEMM関数と引数をセットにした構造体です。引数をそのままにして関数だけを差し替えるといった使い方ができるようにしています。
また、dgemm_test_t型を引数とした行列計算を簡単に実行できるように、次のような関数を用意しました。
void do_dgemm( dgemm_test_t* test ){
test->dgemm(test->Order, test->TransA, test->TransB, test->M, test->N, test->K,
test->alpha, test->A, test->lda, test->B, test->ldb,
test->beta , test->C, test->ldc);
}3-3. 行列初期化関数の準備
BLASルーチンでは、行列Aは、メモリ上の行列サイズがLDA×N、実際に使用する行列サイズをM×Nとして取り扱います。このLDA(及びLDB, LDC)を、Leading Dimensionと呼びます。これにより、連続一次元的に確保されたメモリ領域を、切り取って使うことができるようになっています。
Fortranの二次元配列A(M,N)は、1次元目Mがメモリ上は連続(Column Major)になっているので、行をLeading DimensionとしてA(LDA,N)という形にメモリ領域を確保します。しかし、C言語の二次元配列A[M][N]は、2次元目Nがメモリ上は連続(Row Major)になります。
Fortran用BLASでは、Leading Dimensionは自動的に1次元目を指すことになっています。しかし、C言語用BLASでは、1次元目か2次元目かを引数OrderでLeading Dimensionを選択できるようになっています。C言語用BLASでは、OrderがCblasColMajorの場合は1次元目(Fortranと同じ)を、CblasRowMajorの場合は2次元目を選んだことになります。
ただ、この仕組みがあるために、Leading Dimensionを考慮した初期化関数が必要になります。
計算速度の確認では、計算結果を問わないので、固定値で埋め尽くす初期化でも構いません。しかし、計算結果の確認は、精度比較で確認するので、倍精度の有効桁数の数字が入ったランダムな値が望ましいです。
そこで、下記の2種類の初期化関数を用意しました。
void init_matrix( const int m, const int n,
double* A, const int di, const int dj, double value )
{
double *a = A;
for( int j=0; j<n; j++ ){
for( int i=0; i<m; i++ ){
*a = value;
a = a + di;
}
a = a - m*di + dj;
}
}
void rand_matrix( const int m, const int n,
double* A, const int di, const int dj, uint64_t seed )
{
unsigned short xseed[3]={0};
if( seed != 0 ){
xseed[0] = (seed )&0xffff;
xseed[1] = (seed>>16)&0xffff;
xseed[2] = (seed>>32)&0xffff;
seed48(xseed);
}
double *a = A;
for( int j=0; j<n; j++ ){
for( int i=0; i<m; i++ ){
*a = drand48();
a = a + di;
}
a = a - m*di + dj;
}
}init_matrix関数は、1つの値で埋め尽くす初期化関数です。一方、rand_matrix関数は、倍精度の乱数で埋め尽くす初期化関数です。
行列Aの1次元目と2次元目のストライドサイズdi,djを指定できるようにすることで、CblasRowMajorとCblasColMajorの両方に対応させています。
ストライドってなあに?という方は、下記の記事をご覧ください。
3-4. エラーチェック関数の準備
2つの浮動小数の値の一致は、行列の各要素の正解値と計算値の相対誤差が、倍精度マシンイプシロンより小さいことで等しいと判定します。
相対誤差 = |正解値ー計算値|÷|正解値| ≦ マシンイプシロン
実際には、|正解値|を右辺にうつして、下記の式で判定します。
|正解値ー計算値| ≦ マシンイプシロン×|正解値|
しかし、行列Cの各要素の計算では、行列要素abをK個足し上げた総和計算を行います。一般に、総和計算は、総和サイズKに比例した丸め誤差が発生します。特に、足し上げ順序を入れ替えると、丸め誤差が顕在化します。
実際には、丸め誤差の方向(多いのか少ないのか)が要素によって異なるため、√Kにおおよそ比例すると言われています。そこで、判定条件は以下にします。
|正解値ー計算値| ≦ マシンイプシロン×|正解値|×sqrt(K)
上式が成立しない場合が、エラーになります。|正解値|は、入力された値のどちらが正解値か分からないので、コード上は2つの値の絶対値の大きい方で代用することにします。
以上を踏まえて、行列の全要素を比較する関数は次のようになります。
static int check_matrix( const int m, const int n, const int k,
const double *C1, const int di1, const int dj1,
const double *C2, const int di2, const int dj2 )
{
for( int j=0; j<n; j++ ){
for( int i = 0; i<m; i++ ){
double c1 = fabs(*C1);
double c2 = fabs(*C2);
double cmax = ( c1>c2 ? c1 : c2 );
double cdiff = fabs(c1-c2);
double sqrtk = sqrt((double)k);
double eps = DBL_EPSILON * sqrtk * cmax;
if( cdiff > eps ){
fprintf(stderr,"[ERROR] An element C(%d,%d) is invalid : t1=%G, t2=%G, diff=%G, eps=%G\n",i,j,*C1,*C2,cdiff,eps);
return 1;
}
C1 = C1 + di1;
C2 = C2 + di2;
}
C1 = C1 - m*di1 + dj1;
C2 = C2 - m*di2 + dj2;
}
return 0;
}また、確保したメモリ領域を全て比較する必要はなく、比較範囲は設定によって変わるので、次のようなチェック関数を用意しておきます。
int check_error( const dgemm_test_t* t1, const dgemm_test_t* t2 ){
double* C1 = t1->C;
double* C2 = t2->C;
int ldc1 = t1->ldc;
int ldc2 = t2->ldc;
if( t1->M != t2->M ){
fprintf(stderr,"[ERROR] M is not equal : t1.M=%d, t2.M=%d \n",t1->M,t2->M);
}
if( t1->N != t2->N ){
fprintf(stderr,"[ERROR] N is not equal : t1.N=%d, t2.N=%d \n",t1->N,t2->N);
}
int m = t1->M;
int n = t1->N;
int error = 0;
if( t1->Order == CblasRowMajor && t2->Order == CblasRowMajor ){
error = check_matrix( m, n, C1, 1, ldc1, C2, 1, ldc2 );
}else if( t1->Order == CblasColMajor && t2->Order == CblasRowMajor ){
error = check_matrix( m, n, C1, ldc1, 1, C2, 1, ldc2 );
}else if( t1->Order == CblasRowMajor && t2->Order == CblasColMajor ){
error = check_matrix( m, n, C1, 1, ldc1, C2, ldc2, 1 );
}else if( t1->Order == CblasColMajor && t2->Order == CblasColMajor ){
error = check_matrix( m, n, C1, ldc1, 1, C2, ldc2, 1 );
}
return error;
}3-5. スピードチェック関数の準備
計算速度の確認は、DGEMMの呼び出し前後の経過時間を測定します。経過時間の測定については、下記の記事をご覧ください。
スピードチェック関数の実装は、下記のようになります。
double check_speed( dgemm_test_t* test ){
if( test->Order == CblasRowMajor ){
init_matrix( test->M, test->K, test->A, 1, test->lda, 1e0 );
init_matrix( test->K, test->N, test->B, 1, test->ldb, 1e0 );
init_matrix( test->M, test->N, test->C, 1, test->ldc, 0e0 );
}else{
init_matrix( test->M, test->K, test->A, test->lda, 1, 1e0 );
init_matrix( test->K, test->N, test->B, test->ldb, 1, 1e0 );
init_matrix( test->M, test->N, test->C, test->ldc, 1, 0e0 );
}
double t1,t2;
int error;
t1 = get_realtime();
do_dgemm( test );
t2 = get_realtime();
return (t2-t1);
}計算値はなんでも良いので、スピードチェック関数の中で行列を初期化してしまします。
3-6. 演算数の見積もり
BLASの行列積計算ルーチンDGEMMは、次のような公式を計算しています。
C = alpha * A * B + beta * C
これの最も簡単なプログラムは下記のようになります。
for( j=0; j<N; j++){
for( i=0; i<M; i++){
C[i][j] = beta*C[i][j];
for( k=0; k<K; k++){
C[i][j] = alpha*A[i][k]*B[k][j] + C[i][j];
}}}betaの乗算は、i,jのループに依存し、乗算が1つあるのでM*N回の乗算が行われます。alphaと行列A、Bの行列積は、i,j,kのループに依存し、乗算が2つあるので2*M*N*K回の乗算が行われます。また、加算は、1つのi,jの組みに対してK回行われるので、M*N*K回の加算が行われます。これを合計すると、次のようになります。
2*M*N*K + M*N + M*N*K = M*N*(3*K+1)
実際には、alphaの計算をkループの外側に出すことも可能です。
for( j=0; j<N; j++){
for( i=0; i<M; i++){
ab = 0;
for( k=0; k<K; k++){
ab = ab + A[i][k]*B[k][j];
}
C[i][j] = alpha*ab + beta*C[i][j];
}}この場合だと、最深ループの行列Aと行列Bの行列積は、加算1つと乗算1つで構成されています。これが、M*N*K回計算されるので、演算数は2*M*N*K個になります。また、最新ループの外側の行列Cに書き込む計算は、加算1つと乗算2つで構成されています。これが、M*N回計算されるので、演算数は3*M*N個となります。したがって、演算数の総数は、下記のようになります。
2*M*N*K + 3*M*N = M*N*(2*K+3)
一方、行列積の本質的な計算は、行列Aと行列Bの行列積部分なので、演算数として2*M*N*K個が使われることもあります。まとめると、次のようになります。
(1)2*M*N*K : プログラム間の性能比較でよく用いられる近似的な演算数
(2)M*N*(2*K+3) : 最小化された正確な演算数
(3)M*N*(3*K+1):alpha乗算を冗長化した正確な演算数
今回は、他のライブラリの実装との性能比較ではなく、理論ピーク性能に対する比率を計算するので、正確な演算数が必要です。最適化を進めていくと、alpha乗算は最小ではなくなりますが、(2)の演算数M*N*(2*K+3)を用いることにします。
3-7. 計算結果を確認するプログラム
以上で準備ができたので、計算結果を確認するテストプログラムを作成します。行列サイズは、今後の場合分けに備えて1023×1023に設定します。今後、2^n毎に場合わけをする可能性があるので、全ての場合を通るように2^n-1のサイズにしています。
また、Order, TransA, TransBの全ての可能な設定の組み合わせについて確認するため、全部で8パターンをテストする必要があります。
テストプログラムを下記の通りになりました。
#define SIZE 1023
#define SEED 23091
int main(int argc, char** arv){
enum CBLAS_ORDER majors[2]={CblasRowMajor,CblasColMajor};
enum CBLAS_TRANSPOSE transposes[2]={CblasNoTrans,CblasTrans};
const char* cmajor[2]={"Row-major","Col-major"};
const char* ctrans[2]={"NoTrans","Trans"};
double *A, *B, *C, *D;
dgemm_test_t cblas = { cblas_dgemm, CblasRowMajor, CblasNoTrans, CblasNoTrans, SIZE, SIZE, SIZE, 1e0, NULL, SIZE, NULL, SIZE, 1e0, NULL, SIZE };
dgemm_test_t myblas= { cblas_dgemm, CblasRowMajor, CblasNoTrans, CblasNoTrans, SIZE, SIZE, SIZE, 1e0, NULL, SIZE, NULL, SIZE, 1e0, NULL, SIZE };
A = calloc( SIZE*SIZE, sizeof(double) );
B = calloc( SIZE*SIZE, sizeof(double) );
C = calloc( SIZE*SIZE, sizeof(double) );
D = calloc( SIZE*SIZE, sizeof(double) );
rand_matrix( SIZE, SIZE, A, 1, SIZE, SEED ); // RowMajor
rand_matrix( SIZE, SIZE, B, 1, SIZE, SEED ); // RowMajor
cblas.A = A;
cblas.B = B;
cblas.C = C;
myblas.A = A;
myblas.B = B;
myblas.C = D;
int error = 0;
for( int iorder=0; iorder<2; iorder++ ){
for( int itransa=0; itransa<2; itransa++ ){
for( int itransb=0; itransb<2; itransb++ ){
cblas.Order = majors[iorder];
cblas.TransA = transposes[itransa];
cblas.TransB = transposes[itransb];
myblas.Order = majors[iorder];
myblas.TransA = transposes[itransa];
myblas.TransB = transposes[itransb];
printf("Case : Order=%s, TransA=%s, TransB=%s ... ",cmajor[iorder],ctrans[itransa],ctrans[itransb]);
init_matrix( SIZE, SIZE, cblas.C , 1, SIZE, 0e0 );
init_matrix( SIZE, SIZE, myblas.C, 1, SIZE, 0e0 );
do_dgemm( &cblas );
do_dgemm( &myblas );
error = check_error( &cblas, &myblas );
if( error ){
printf("NG\n");
break ;
}else{
printf("OK\n");
}
}
}
}
free(A);
free(B);
free(C);
free(D);
return error;
}dgemm_test_t構造体のmyblas変数の第一変数dgemmは、後ほど自作プログラムの関数ポインタに置き換えます。
上記のテストプログラムを実行し、問題がない場合は、下記のように表示されます。
Case : Order=Row-major, TransA=NoTrans, TransB=NoTrans ... OK
Case : Order=Row-major, TransA=NoTrans, TransB=Trans ... OK
Case : Order=Row-major, TransA=Trans, TransB=NoTrans ... OK
Case : Order=Row-major, TransA=Trans, TransB=Trans ... OK
Case : Order=Col-major, TransA=NoTrans, TransB=NoTrans ... OK
Case : Order=Col-major, TransA=NoTrans, TransB=Trans ... OK
Case : Order=Col-major, TransA=Trans, TransB=NoTrans ... OK
Case : Order=Col-major, TransA=Trans, TransB=Trans ... OK3-8. 計算速度を確認するプログラム
計算性能は行列サイズによって変わってくるので、粗くサイズを変えて計算性能を確認するようにしました。テストプログラムは、下記のようになりました。
#define MAX_SIZE 2048
int main(int argc, char** arv){
int error = 0;
flops_info_t cpu;
double *A, *B, *C;
dgemm_test_t myblas = { cblas_dgemm, CblasRowMajor, CblasNoTrans, CblasNoTrans, MAX_SIZE, MAX_SIZE, MAX_SIZE, 1e0, NULL, MAX_SIZE, NULL, MAX_SIZE, 1e0, NULL, MAX_SIZE };
A = calloc( MAX_SIZE*MAX_SIZE, sizeof(double) );
B = calloc( MAX_SIZE*MAX_SIZE, sizeof(double) );
C = calloc( MAX_SIZE*MAX_SIZE, sizeof(double) );
myblas.A = A;
myblas.B = B;
myblas.C = C;
peak_flops( &cpu );
double mpeak = cpu.mflops_double_max / cpu.num_cores;
double bpeak = cpu.mflops_double_base / cpu.num_cores;
printf("Max Peak MFlops per Core: %G MFlops \n",mpeak);
printf("Base Peak MFlops per Core: %G MFlops \n",bpeak);
printf("size , elapsed time[s], MFlops, base ratio[%%], max ratio[%%] \n");
for( size_t n=16; n<=MAX_SIZE; n=n*2 ){
myblas.M = n;
myblas.N = n;
myblas.K = n;
myblas.lda = n;
myblas.ldb = n;
myblas.ldc = n;
double nflop = (2*((double)myblas.K)+3) * ((double)myblas.M) * ((double)myblas.N);
double dt = check_speed( &myblas );
double mflops = nflop / dt / 1000 / 1000;
printf("%6u, %15G, %15G, %15G, %15G \n",n,dt,mflops,mflops/bpeak*100,mflops/mpeak*100);
}
free(A);
free(B);
free(C);
return error;
}現在は、Netlib.orgのリファレンスBLASの測定をしています。
これを実行すると、下記のように表示されます。
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 2.86102E-06, 3131.75, 6.74945, 5.93134
32, 1.40667E-05, 4877.34, 10.5115, 9.23738
64, 0.000114918, 4669.22, 10.063, 8.84322
128, 0.000982046, 4321.04, 9.31258, 8.18378
256, 0.00650811, 5186, 11.1767, 9.82196
512, 0.052299, 5147.74, 11.0943, 9.74951
1024, 0.489076, 4397.33, 9.47701, 8.32828
2048, 4.04466, 4250.65, 9.16089, 8.05048 ここから、Netlib.orgからダウンロードできるBLASは、基本周波数の場合で理論ピーク性能比9~11%が出ていることがわかります。
4. 初期プログラムの作成 [無料]
チューニングに必要な準備ができたので、行列積計算プログラムを作成していきます。まず、BLASの行列積ルーチンDGEMMの公式を再確認しておきましょう。
C = alpha * A * B + beta * C
ここで、A, B, Cは行列、alpha, betaはスカラー係数を表しています。
関数インターフェースは、上記のテストプログラムで使用できるように、CBLASのcblas_dgemm関数と同じものとし、関数名をmyblas_dgemmとします。
void myblas_dgemm(const enum CBLAS_ORDER Order, const enum CBLAS_TRANSPOSE TransA,
const enum CBLAS_TRANSPOSE TransB, const int M, const int N,
const int K, const double alpha, const double *A,
const int lda, const double *B, const int ldb,
const double beta, double *C, const int ldc);myblas_dgemmでは、第一引数Orderの処理と引数のエラー処理だけを行い、Orderの違いを吸収してしまいます。第一引数Orderの処理は、CblasRowMajorが選ばれた場合に、行列Aと行列Bを入れ替えるという処理をします。これは、cblas_dgemm関数の実装を参照にしています。
実際の計算には、myblas_dgemm_mainという別の関数を用意しています。
void myblas_dgemm_main( gemm_args_t* args );引数はgemm_args_t型の構造体にまとめることにしました。これは、高速化作業で引数を追加する必要が出てきた時、引数の変更作業を楽にするためです。構造体の定義は、下記の通りです。
typedef struct _gemm_args_t {
size_t TransA;
size_t TransB;
size_t M;
size_t N;
size_t K;
double alpha;
const double *A;
size_t lda;
const double *B;
size_t ldb;
double beta;
double *C;
size_t ldc;
} gemm_args_t;転置設定のTransAとTransBは、元々enum CBLAS_TRANSPOSE型でしたが、今後のためを考えてビットフラグに変更しました。フラグは、転置を1ビット目、複素共役を2ビット目とし、下記のようなマスクを用意しています。
#define MASK_TRANS 0x01
#define MASK_CONJ 0x024-1. myblas_dgemm関数
行列Aと行列Bの入れ替えが必要なCblasRowMajorの場合の引数処理及びエラー処理は、下記のようになります。CblasColMajorの場合は、TransA, TransBの処理やM,Nの入れ替えを元に戻したコードを通るように条件分岐しています。
gemm_args_t args={0,0,0,0,0,0e0,NULL,0,NULL,0,0e0,NULL,0};
int info = 0;
if( Order == CblasColMajor ){
/** 省略 **/
}else if( Order == CblasRowMajor ){
// Transpose Set-up
if( TransA == CblasNoTrans ){ args.TransB = 0; }
if( TransA == CblasTrans ){ args.TransB = MASK_TRANS; }
if( TransA == CblasConjTrans){ args.TransB = MASK_TRANS | MASK_CONJ; }
if( TransB == CblasNoTrans ){ args.TransA = 0; }
if( TransB == CblasTrans ){ args.TransA = MASK_TRANS; }
if( TransB == CblasConjTrans){ args.TransA = MASK_TRANS | MASK_CONJ; }
// Error Check
if( C == NULL ) info=13;
if( B == NULL ) info=10;
if( A == NULL ) info= 8;
if( info ){ myblas_xerbla("myblas_dgemm",info); return; }
int ma = ( (args.TransB & MASK_TRANS) ? M : K );
int mb = ( (args.TransA & MASK_TRANS) ? K : N );
if( ldc < N ) info=14;
if( ldb < mb ) info=11;
if( lda < ma ) info= 9;
if( K < 0 ) info= 6;
if( N < 0 ) info= 5;
if( M < 0 ) info= 4;
if( info ){ myblas_xerbla("myblas_dgemm",info); return; }
// No Computing
if( M == 0 ) return;
if( N == 0 ) return;
if( K == 0 && beta == 1e0 ) return;
if( alpha== 0e0 && beta == 1e0 ) return;
// Set arguments
args.M = N;
args.N = M;
args.K = K;
args.alpha = alpha;
args.A = B;
args.lda = ldb;
args.B = A;
args.ldb = lda;
args.beta = beta;
args.C = C;
args.ldc = ldc;
}
myblas_dgemm_main( &args );ここで、myblas_xerbla関数は、BLASのエラー出力ルーチンXERBLAを模したものです。下記のような、BLASのエラーメッセージを出力します。
void myblas_xerbla( const char* name, int info ){
printf(" ** On entry to %s parameter number %d had an illegal value\n",name,info);
}4-2. myblas_dgemm_main関数
実際の行列積計算は、行列Aと行列Bの転置有無の組み合わせで、全部で4パターンのコードが必要になります。転置なしの場合は、次のようなコードになります。
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A += lda;
B++;
}
*C=beta*(*C) + alpha*AB;
A = A - lda*K + 1;
B = B - K;
C++;
}
A = A - M;
B = B + ldb;
C = C - M + ldc;
}行列CがM×N行列(Mがメモリ連続方向)で、Kに依存しないので、無駄なメモリアクセスを避けるために、外側からN→M→Kの順の三重ループにしています。本来、CはM*N*K回のメモリアクセスが必要ですが、この順にすると、M*N回のメモリアクセスで済みます。また、例えばM→N→Kの順にすると、Cはストライドアクセスが必要になります。これを避けるため、N→M→Kの順にしています。
一方、行列AはM×K行列なので、Kループはメモリ連続方向ではありません。このため、ldaずつ飛び飛びのストライドアクセスになってしまいます。逆に、行列BはK×N行列のため、Kループがメモリ連続方向なので連続アクセスになります。行列Aがどうしてもストライドアクセスになるため、スピードがほとんど出ないと予想されます。
実際、計算速度を測定してみると、次のようになりました。
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 4.05312E-06, 2210.64, 4.76432, 4.18683
32, 3.40939E-05, 2012.33, 4.33691, 3.81123
64, 0.000264883, 2025.71, 4.36575, 3.83657
128, 0.00234389, 1810.43, 3.90179, 3.42885
256, 0.0287192, 1175.21, 2.53278, 2.22577
512, 0.263068, 1023.39, 2.20559, 1.93824
1024, 6.27475, 342.743, 0.738671, 0.649135
2048, 113.116, 151.99, 0.327564, 0.28786 M=N=K=2048で、基本理論ピーク性能の0.3%しか出ていません。どうしようもなく、遅いですね…。
ちなみに、4パターン内で最も高速なのは、行列Aだけを転置した場合で、実装コードは次のようになります。
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A++;
B++;
}
*C=beta*(*C) + alpha*AB;
A = A - K + lda;
B = B - K;
C++;
}
A = A - lda*M;
B = B + ldb;
C = C - M + ldc;
}行列Aを転置した場合は、最内のKループにおいて、AもBも連続アクセスになっています。この時の、計算速度は次のようになります。
Max Peak MFlops per Core: 52800 MFlops
Base Peak MFlops per Core: 46400 MFlops
size , elapsed time[s], MFlops, base ratio[%], max ratio[%]
16, 4.05312E-06, 2210.64, 4.76432, 4.18683
32, 3.00407E-05, 2283.83, 4.92205, 4.32544
64, 0.000258923, 2072.34, 4.46625, 3.92489
128, 0.0022769, 1863.7, 4.0166, 3.52974
256, 0.0209579, 1610.42, 3.47073, 3.05003
512, 0.178289, 1510.03, 3.25438, 2.85991
1024, 1.40407, 1531.71, 3.3011, 2.90097
2048, 11.1541, 1541.35, 3.32188, 2.91923 この場合は、基本周波数の理論ピーク性能比で3.3%以上のスピードが出ます。
ということで、ストライドアクセスだととても遅いことがわかりますね。
4-3. 初期プログラム
最後に、初期プログラムの全体を載せておきます。
void myblas_dgemm_main( gemm_args_t* args ){
size_t TransA = args->TransA;
size_t TransB = args->TransB;
size_t M = args->M;
size_t N = args->N;
size_t K = args->K;
double alpha = args->alpha;
const double *A = args->A;
size_t lda = args->lda;
const double *B = args->B;
size_t ldb = args->ldb;
double beta = args->beta;
double *C = args->C;
size_t ldc = args->ldc;
double AB;
if( TransA & MASK_TRANS ){
if( TransB & MASK_TRANS ){
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A++;
B+=ldb;
}
*C=beta*(*C) + alpha*AB;
A = A - K + lda;
B = B - ldb*K;
C++;
}
A = A - lda*M;
B = B + 1;
C = C - M + ldc;
}
}else{
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A++;
B++;
}
*C=beta*(*C) + alpha*AB;
A = A - K + lda;
B = B - K;
C++;
}
A = A - lda*M;
B = B + ldb;
C = C - M + ldc;
}
}
}else{
if( TransB & MASK_TRANS ){
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A += lda;
B += ldb;
}
*C=beta*(*C) + alpha*AB;
A = A - lda*K + 1;
B = B - ldb*K;
C++;
}
A = A - M;
B = B + 1;
C = C - M + ldc;
}
}else{
for( size_t j=0; j<N; j++ ){
for( size_t i=0; i<M; i++ ){
AB=0e0;
for( size_t k=0; k<K; k++ ){
AB = AB + (*A)*(*B);
A += lda;
B++;
}
*C=beta*(*C) + alpha*AB;
A = A - lda*K + 1;
B = B - K;
C++;
}
A = A - M;
B = B + ldb;
C = C - M + ldc;
}
}
}
}これで、ようやく準備が整いました。以降では、高速化の方法を実際にプログラムを書きながら解説していこうと思います。また、恐縮ですが、これより先は有料記事にさせていただきます。
この記事は、実践的な高性能化プログラミング技術を学びたい人向けになっています。マニアックな内容なので、プログラミング初心者の方や技術の概要を知りたい方には向いていないと思います。ただ、もしも「世界一を目指す技術を知りたい」とか「高速なBLASは使っているけど、なんでこんなに速いのか知りたい」とか「高性能化を極める考え方を知りたい」といった興味があれば、ご購入いただけると幸いです。
また、必要な技術の解説は既に無料の別の記事で紹介していますので、概要でよければそちらをご覧いただくと良いかもしれません。
ここから先は
¥ 560
この記事が気に入ったらサポートをしてみませんか?