
pandas_SettingWithCopyWarningを回避しながらDataFrameに列を挿入する #354

SettingWithCopyWarningとは
pandasではDataFrameのget操作がデータのビューとコピーのどちらを返すのか保証しておらず、そのことに起因して発生する警告です。どのDataFrameを操作しているのか曖昧になっている、ということが警告されています。
例えば以下のようにbidderというカラムの値が'parakeet2004'であるレコードを取得(get)する場合です。ここではビューとコピーのどちらが返ってくるか保証されていません。
data[data.bidder == 'parakeet2004']上記コードではPythonインタプリタが以下を実行しています。
data.__getitem__(data.__getitem__('bidder') == 'parakeet2004')このget操作の際にビューかコピーのいずれかが返ってきています。ここで取得した値をそのまま使うなら問題ありません。
ただ、値を更新したい場合はそうもいきません。bidderというカラムの値が'parakeet2004'であるレコードの、'bidderrate'というカラムに100という値を入力します。以下のように記述するとSettingWithCopyWarningが出ます。
data[data.bidder == 'parakeet2004']['bidderrate'] = 100上記コードではPythonインタプリタが以下を実行しています。
data.__getitem__(data.__getitem__('bidder') == 'parakeet2004').__setitem__('bidderrate', 100)これはget操作に連鎖してset操作が行われています。これは連鎖インデックス (Chain Indexing)呼ばれ、SettingWithCopyWarningの原因です。
連鎖インデックスとは、pandasの内部的には、単一の操作を実行するために__getitem__または__setitem__を複数回呼び出すこと
つまり、ビューかコピーか曖昧なままgetしてきたデータに対してsetしているので、どのメモリで値が更新されたか曖昧で警告されています。
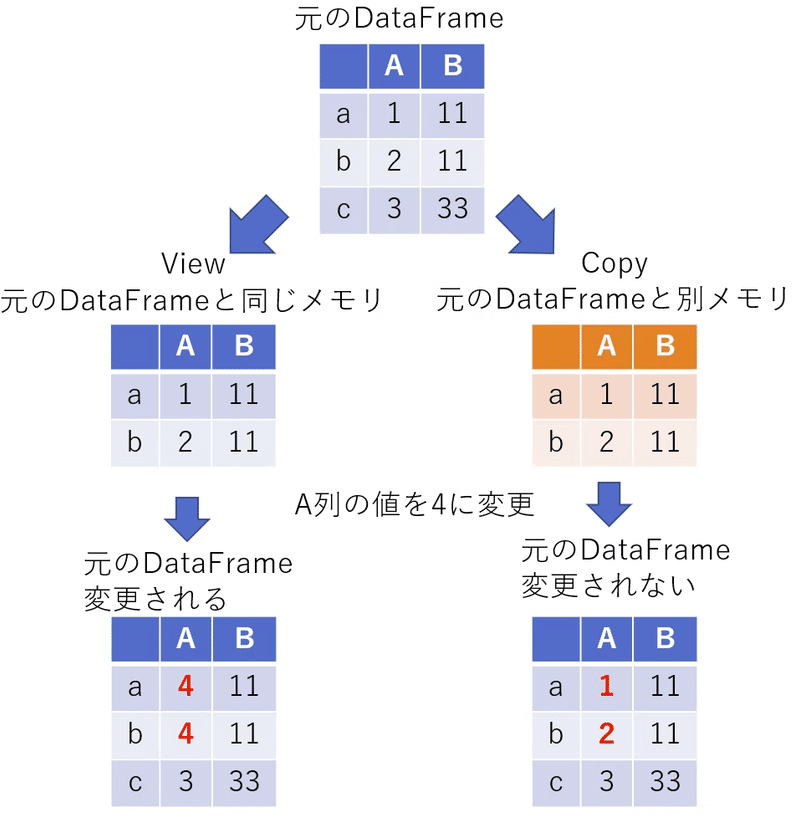
ビューとコピーについて分かりやすい図があったので掲載させていただきます。
ではこの警告をどうやって回避するか。
連鎖した処理ではなく、一つの処理になるようにまとめてあげれば良いです。
locを使って上記コードを修正すると警告は出なくなります。
data.loc[data.bidder == 'parakeet2004', 'bidderrate'] = 100上記コードではPythonインタプリタが以下を実行しています。
data.loc.__setitem__((data.__getitem__('bidder') == 'parakeet2004', 'bidderrate'), 100)getしたデータに対してsetするのではなく、setする位置を特定するところでgetしています。連鎖インデックスではなくなっているので警告も出ません。また、locプロパティはコピーではなく元のDataFrameであることが保証されています。
SettingWithCopyWarningの実例をみてみる
より実際っぽいコードで確認してみます。
df_masterはdf_originからget操作で作成されているので、以下のように1列追加しようとするとSettingWithCopyWarningが出ます。
# 元のデータフレーム
df_origin = pd.read_csv('sample.csv').reset_index(drop=True)
# 元のデータフレームから必要なカラムだけ抽出したもの
df_master = df_origin[[
'id',
'first_date_29h',
'type_num',
'fee']]
# 1列追加する
df_master['type_name'] = 'sample'<string>:43: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value insteadちなみに、元のデータフレームに値を追加するだけであれば、もちろんSettingWithCopyWarningは出ません。get操作も挟んでおらず、元のデータフレームに対する操作であることが確定しているためです。
# 元のデータフレーム
df_origin = pd.read_csv('sample.csv').reset_index(drop=True)
df_origin['type_name'] = 'sample'SettingWithCopyWarningを回避しながらDataFrameに列を挿入するには
より複雑な処理をしながらSettingWithCopyWarningを回避する方法をメモしておきます。ここではmapで処理を加えてみてます。type_numの内容に応じて、動的にtype_nameの値を挿入していくイメージです。
まず警告が出るパターンです。
お馴染みになってきましたが、以下のように1列追加するとChain indexingになっているため、SettingWithCopyWarningが出ます。
# 元のデータフレーム
df_origin = pd.read_csv('sample.csv').reset_index(drop=True)
# 元のデータフレームから必要なカラムだけ抽出したもの
df_master = df_origin[[
'id',
'first_date_29h',
'type_num',
'fee']]
# 1列追加する
df_master['type_name'] = df_origin['type_num'].map(Type.convert_type_num_to_name)<string>:41: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead以下のように元のデータフレームに対して1度の処理として書き切ってしまえば、Chain indexingにならずSettingWithCopyWarningが出ません。
# 元のデータフレーム
df_origin = pd.read_csv('sample.csv').reset_index(drop=True)
# 元のデータフレームから必要なカラムだけ抽出しつつ、行によって値が変わる列を1列追加し、不要になった列を削除する
df_master = df_origin[[
'id',
'first_date_29h',
'last_date_29h',
'type_num',
'fee']].assign(type_name=df_origin['type_num'].map(GrpType.convert_type_num_to_name)).drop('type_num', axis=1)もしくは、df_masterを宣言するところで明示的にcopyしてしまう手もあります。ビューではなくコピーであることを明示的にしてあげれば、これはこれでChain indexingになりません。
df_origin = pd.read_csv('sample.csv').reset_index(drop=True)
df_master = df_origin[[
'id',
'first_date_29h',
'last_date_29h',
'type_num',
'fee']].copy()
df_master['type_name'] = df_origin['type_num'].map(Type.convert_type_num_to_name)
df_master.drop('type_num', axis=1, inplace=True)ただ、データ量が多いとcopyの多用はメモリ逼迫に繋がります。そのため実装上は不適切なケースもあるので、そのような場合はcopyせずに前者の方法を取る方が無難です。
ここまでお読みいただきありがとうございました!
参考
この記事が気に入ったらサポートをしてみませんか?