
第25話 バックプロパゲーションの理解に必要な知識 -最適化アルゴリズム-

今回はニューラルネットワークの学習アルゴリズム"バックプロパゲーション"に必要な5つの知識のうち、4つ目の最適化アルゴリズムについて学習します。
<バックプロパゲーションの理解に必要な5要素>
・訓練データとテストデータ
・損失関数
・勾配降下法
・最適化アルゴリズム ←イマココ
・バッチサイズ
今回の具体的な内容は次のとおりです。
1. 最適化アルゴリズムの概要
2. 確率的勾配降下法(SGD)
3. Momentum
4. AdaGrad
5. RMSProp
それでは学習を始めましょう。
(教科書「はじめてのディープラーニング」我妻幸長著)
1. 最適化アルゴリズムの概要
ニューラルネットワーク の学習では、勾配降下法により勾配を使って重みとバイアスを少しずつ変化させて、誤差が最小になるようにネットワークを最適化します。
最適化アルゴリズムは、最適化のために重みとバイアスをどれくらい更新するかを決めるものです。
最適化アルゴリズムとは、例えるなら「目隠し山下りゲーム」でうまくゴールするための戦略です。
あなたならどうやってゴールを目指しますか?
目隠したら何も見えませんよね。そうなると頼りになるのは足元の傾斜のみです。
傾斜を使うと言っても、現時点で最も急な方向に下る、これまでの経路を考えて進行方向を決める、というようにいくつか戦略があると思います。
でも戦略を誤ると局所的に凹んだ地形にハマってしまったり、山を下るのに時間がかかりすぎたりしてしまうのです。
なので、効率的にしかも確実に大域最適解に到達するには、最適化アルゴリズムの選択が重要になってきます。
最適化アルゴリズムには色々なものが考案されていますが、今回は代表的なものを4つ紹介します。
・確率的勾配降下法(SGD, Stochastic Gradient Descent)
・Momentum
・AdaGrad
・RMSProp
2. 確率的勾配降下法(SGD)
確率的勾配降下法は、更新するたびにランダムにサンプルを選び出すアルゴリズムです。
重みとバイアスの更新式は次のように表されます。

メリット
局所最適解に囚われにくい。
デメリット
学習の進行に応じて柔軟に更新量を調整できない。
3. Momentum
Momentumは、確率的勾配降下法に慣性項を付け加えたアルゴリズムです。
慣性とは、ある物体に外力が働かない場合、その物体の運動状態は変わらない性質のことです。(静止物体は静止し続けるし、運動物体は等速直線運動する。)
更新式は次のとおりです。
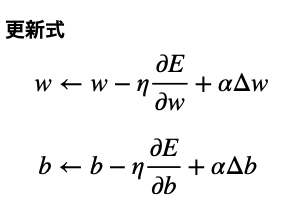
右辺第3項が慣性項で、前回の更新量を表しています。
今回の更新量は、前回の更新量の影響を受けるということです。(目隠し山下りゲームでいうと、これまでの進行方向の影響を受けるということ。)
メリット
更新量の急激な変化が防がれ、より滑らかな更新が実現する。
デメリット
確率的勾配降下法より設定するパラメータが2つ増える。(調整が難しくなる。)
4. AdaGrad
AdaGradは、更新量が自動的に調整され、学習が進むと学習率が小さくなるというアルゴリズムです。
更新式は次のとおりです。
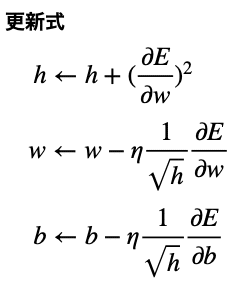
hは必ず増加するように更新されます。
w,bの更新式にはhが分母にあるので、hが大きくなるとw,bの更新量は小さくなります。
hは重みごとに計算されます。
これまでの総更新量が小さい重み/バイアスは新たな更新量が大きくなり、総更新量が多い重み/バイアスは新たな更新量が小さくなります。
これにより、最初は広い領域で探索し、次第に探索範囲を絞るという効率の良い探索ができます。
よく考えられてますね。
メリット
設定すべき定数はηしかないので、定数の調整に手間がかからない。(SGDと同じ。)
デメリット
更新量が常に減少するため、途中で更新量がほぼ0になってしまうとそれ以上最適化が進まないケースがある。
5. RMSProp
RMSPropは、AdaGradの弱点である更新量の低下により学習が停滞する点を克服したものです。
更新式は次のとおりです。

過去のhを適当な割合で忘れるためにρが存在しています。
忘れることにより学習の弱点が克服できる(=学習が速くなる)というのは面白いですよね。
考案者はρ=0.9を推奨しています。
今回は最適化アルゴリズムの概要と、代表的な最適化アルゴリズムについて学習しました。
重みとバイアスを更新する際、どの最適化アルゴリズムを選択するかによって性能が変わってきそうですね。
機会をみて性能を比べてみたいと思います。
最適化アルゴリズムは奥が深く、色々なものがあり、今回紹介したものはその一部です。
この物語はディープラーニングの実装を目指しているので、最適化アルゴリズムには深入りしないでおこうと思います。
次回は、"バックプロパゲーション"に必要な5つの知識のいよいよ最後のバッチサイズを学習します。
どうぞお楽しみに。
それではまた(^_^)ノシ
よろしければサポートお願いします!いただいたサポートは書籍代等に活用いたします!