
第31話 ディープラーニングの問題点

ディープラーニングの勉強を始めて苦節3ヶ月ちょい、やっとディープラーニングを勉強するための下地が整いました!
長く苦しい道のりでした。
未知のコンピュータ言語Phython、退屈な数学を乗り越えついにここまでやってきました。
ここまで頑張れたのも、こんなマニアックな記事を読んでくださる方がいるからです。
いつもありがとうございます。
さてこれからディープラーニングを本格的に学んでいくわけですが、今回の学習内容はディープラーニングの代表的な問題についてです。
それでは学習をはじめましょう。
(教科書「はじめてのディープラーニング」我妻幸長著)

ディープラーニングってなんだっけ?
実は3ヶ月ほど前にディープラーニングについて記事を書いていますが、おさらいします。
(第1話参照←書きっぷりが今とはだいぶ違いますね^^; 色々試行錯誤しながらやっていますので、変遷ぶりも楽しんでいただければと思います。)
中間層を多くを持つニューラルネットワークのことをディープニューラルネットワークといい、これを用いた学習のことをディープラーニング(深層学習)といいます。
余談ですが、何層以上を持っていればディープと呼ぶのかは、おもしろいことに明確に定義されていないようです。
ディープラーニングでは層の数を多くするとネットワークの表現力が向上する反面、実は学習が難しくなる欠点もあります。
ディープラーニングにおける代表的な問題は次のとおりです。
・局所最適解へのトラップ(ハマる)
・過学習
・勾配消失
・学習時間の増大
これらが具体的にどういう問題なのか見ていきましょう。
局所最適解へのトラップ
ニューラルネットワークでは、正解との誤差を小さくするために勾配降下法を使って学習します。(詳細は第22話参照)
勾配=0となるところで学習がストップするのですが、下の図のように勾配=0の点が全体の最適解でないところにハマって(トラップされて)しまう可能性があります。
(曲線Eは実際は未知なのです。)

この図をルービックキューブに置き換えると次のようになります。
点A・・・1面のみが揃った状態(=局所最適解にトラップされた状態)
点B・・・キューブをいくら回しても面の色が揃っていかない状態
大域最適解にたどり着くためには、一度局所的にベストな状態(=勾配ゼロ)から脱出する必要があります。
過学習
ニューラルネットワークの目的は、既知のデータを学習して未知のデータを正しく推定することです。
しかし、ニューラルネットワークが既知データ(=学習用データ)に最適化されすぎて、未知のデータに対応できなくなることがあります。
これを過学習(または過剰学習、過適合)といいます。
過学習しない・した場合の誤差の収束のイメージを下図に示します。
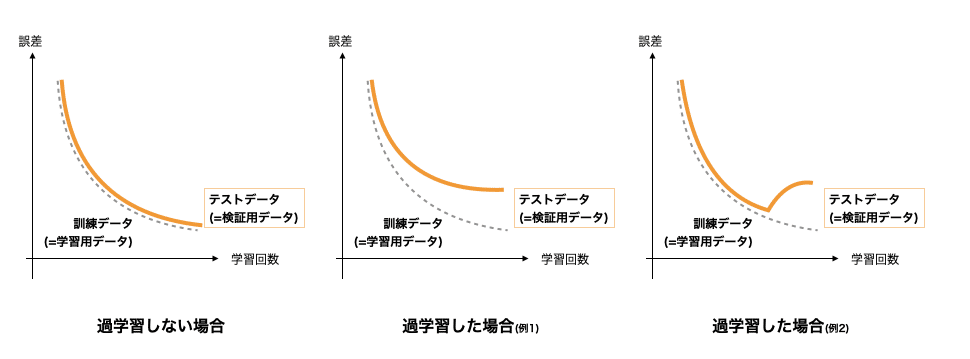
未知のデータに対応できる能力のことを汎化能力といいます。
訓練データでどれだけ誤差が小さくなろうとも、汎化能力がなければ学習は失敗です。
ネットワークを学習させた後、テストデータで学習を評価することが非常に重要ということですね。
勾配消失
逆伝播(学習)の際に、層を遡るについてれ勾配が0に近づいてしまう問題を勾配消失といいます。
なぜこのようなことが起きるのでしょうか?
例として、中間層のニューロンの活性化関数がシグモイド関数である場合を考えます。
シグモイド関数とその導関数(微分した関数)は次のようになります。

逆伝播では、活性化関数を微分したもの(=活性化関数の勾配)を掛けたものがネットワークを遡上するのでしたね。(詳細は第22〜24話参照)
シグモイド関数の導関数は最大値が0.25です。
仮に最大値が3層分遡上したとすると
1層目:0.25
2層目:0.063(=0.25×0.25)
3層目:0.016(=0.25×0.25×0.25)
と、どんどん小さくなっていきます。
ネットワークを遡るについて、勾配がどんどん小さくなり(=減衰)、やがて消失する理由が理解できたでしょうか。
なのでディープラーニングでは、勾配消失が起こらないよう活性化関数にReLU関数を使用することが多いようです。

ReLU関数を使用するメリットは、導関数がx>0で常に1であることです。
1がネットワークを遡上するのであれば、層を遡っても勾配は減衰しません。
学習時間の増大
ディープラーニングでは、重みとバイアスの数が数千〜数億に及ぶことがあり、学習に数日〜数週間といった長い時間がかかることがあります。
PCの性能向上、アルゴリズムの発展、クラウド活用によりこの問題は克服されつつあるようでが、期待して待っているわけにはいきませんね。
自分でできる対策としては次のことが挙げられます。
・必要以上にネットワークを複雑にしないこと。
・コードから実行速度を遅くする部分を取り除くこと。
・ハイスペックPCを使うこと。
こう言われてしまうと、マイPC(MacBookAir)で対応できるか不安になってきましたが、まずは当たって砕けろの精神でチャレンジしていきます!
今回はディープラーニングの概要(おさらい)と、ディープラーニングで起こる代表的な問題点について学習しました。
局所最適解へのトラップ、過学習の対策については経験が問われる問題なのかなぁと思いました。
勾配の消失は活性化関数で対策できるので、あまり気にしないでも良さそうです。
学習時間については諦める部分が出てきそうですね。
今回の内容を学習するまでは、「ディープラーニングって最強そうだし、なんでそんなに普及していないのだろう?」と疑問を抱いていた私ですが、「そんなに世の中甘くない。」と認識を改めることができました。
正しく物事を理解するために、勉強って大事ですね。
次回は、さらに細かいレベルのディープラーニングの問題点とその対策を勉強します。
それではまた(^_^)ノシ
よろしければサポートお願いします!いただいたサポートは書籍代等に活用いたします!