
VRCモデル改変キャラクターLoRA作成手順(AI実験/2024年6月)

VRC用モデル改変キャラクターのLoRAを作成する手順の紹介です。
今回の目的
VRCで使用している自分のキャラクターのAIイラストを生成できるようになります。
前提条件
※「すでに改変済みの自分の3Dアバターがある方」向けの内容になります。
【使用ツール】
●Stable Diffusion (webui A1111)*1
●Transparent-Background*2
●Kohya_LoRA_GUI (kohya-ss)*3
●Unity*4
●VRC*5
●VRCキャラクターモデル(shimu様)*6
【実験環境】
●Model : Pony Diffusion V6 XL*7
●Model : ebara_pony_2.1*8
●GPU : GeForce RTX 3090 (VRAM24GB)
●Python 3.10.6
※VRAMはFP8なら12GBでも学習できるそうです。
※SDXLではなくSD1.5系でも同様のことができると思います。
※各プログラム・サービスへのリンクは最後に記載してあります。
LoRA作成手順
1)キャラクターの準備
今回は以前作成したフォシュニアくんの改変済みモデルを使用します。
2)教師データ画像の撮影(スクリーンショット)
最初に教師データとなるキャラクターのスクリーンショットを作成します。
VRC内で撮影した画像でも、Unityで撮影した画像でもOKです。
背景を切り抜くため被写体だけが映っているシンプルな画像が良いです。


キャラクターに動きが欲しかったので、VRC上で自分で動きながら撮影しています。
ワールドはUnityでシンプルな床平面だけのワールドを作成し、VRCにアップして撮影用ワールドとして使いました。
色んなポーズをとりつつカメラの位置を調整して教師データに使えそうなアングルを探しました。
(表情の変化をもっと撮ればよかった…)
3)教師データ画像の加工
スクリーンショットから背景を削除して被写体のみにします。
Transparent-Background*2というツールを使いました。
背景色は白にしています。

きれいに切り抜けた画像を使います。
白く消えてしまった部分があっても、良いアングルで使いたい画像の場合は加筆修正して形を直して教師データ画像とします。
教師データはできるだけ特徴の明確なものが良いです。
★Transparent-Backgroundの使い方
1)インストール
※Pythonが導入されている環境が必要です。
上記サイトから依存関係を確認してください。
コマンドプロンプトを開き下記のコードを入力してインストールします。
pip install transparent-background2)使用方法
変換対象の画像フォルダが「C:\images」にある場合として。
指定画像フォルダ内すべての画像に対して、キャラを残して背景を白抜きにする処理をかけるには
transparent-background --source "C:\images" --type white --dest "C:\images\output"と入力します。
実行後、画像フォルダ内に作成されるoutputフォルダに処理後の画像が保存されます。
画像フォルダの場所が違う場合や、処理後画像の保存場所を変更したい場合はコードのフォルダ階層を指定している部分を修正してください。
白背景にする場合:--type white
グリーンバックにする場合:--type green
透過する場合:指定なし
マスクを作成する場合:--type map
画像処理後の切り抜き残しや切りすぎはペイントソフトで修正します。
4)キャプショニング(タグ付け)
Stable Diffusion (webui A1111)の拡張機能である「Tagger」と「Dataset Tag Editor」を使用してキャプショニング(タグ付け)をします。
今回はトリガーワードを仮に「chara」として説明していきます。
★キャプショニング手順
1)教師データ画像をひとつのフォルダに集める

1_charaフォルダはtraningという名前のフォルダの中に入っています
2)Taggerをインストール
Stable Diffusion (webui A1111)を起動して「Extensionsタブ」から「Install from URLタブ」の順に選択して、URL for extension's git repositoryの欄に上記のアドレス(https://github.com/picobyte/stable-diffusion-webui-wd14-tagger)を入力します(コピペでOK)。
Installボタンを押すと拡張がインストールされるので少し待ってプログラムを再起動します。

3)Taggerで自動キャプショニング
再起動したら「Taggerタブ」が増えていると思うので「Tagger」を押して表示して上部の「Batch from directory」を選択します。
「input directory」の欄に先ほどの画像フォルダのパスを指定します。
下の方の「Interrogator」タブで「Z3D-E621-Convnext」を選択します。
※今回はPonyV6モデルとその派生モデルでの画像生成を考えているため、e621系データセット群で構成されたinterrogate modelを使用します。
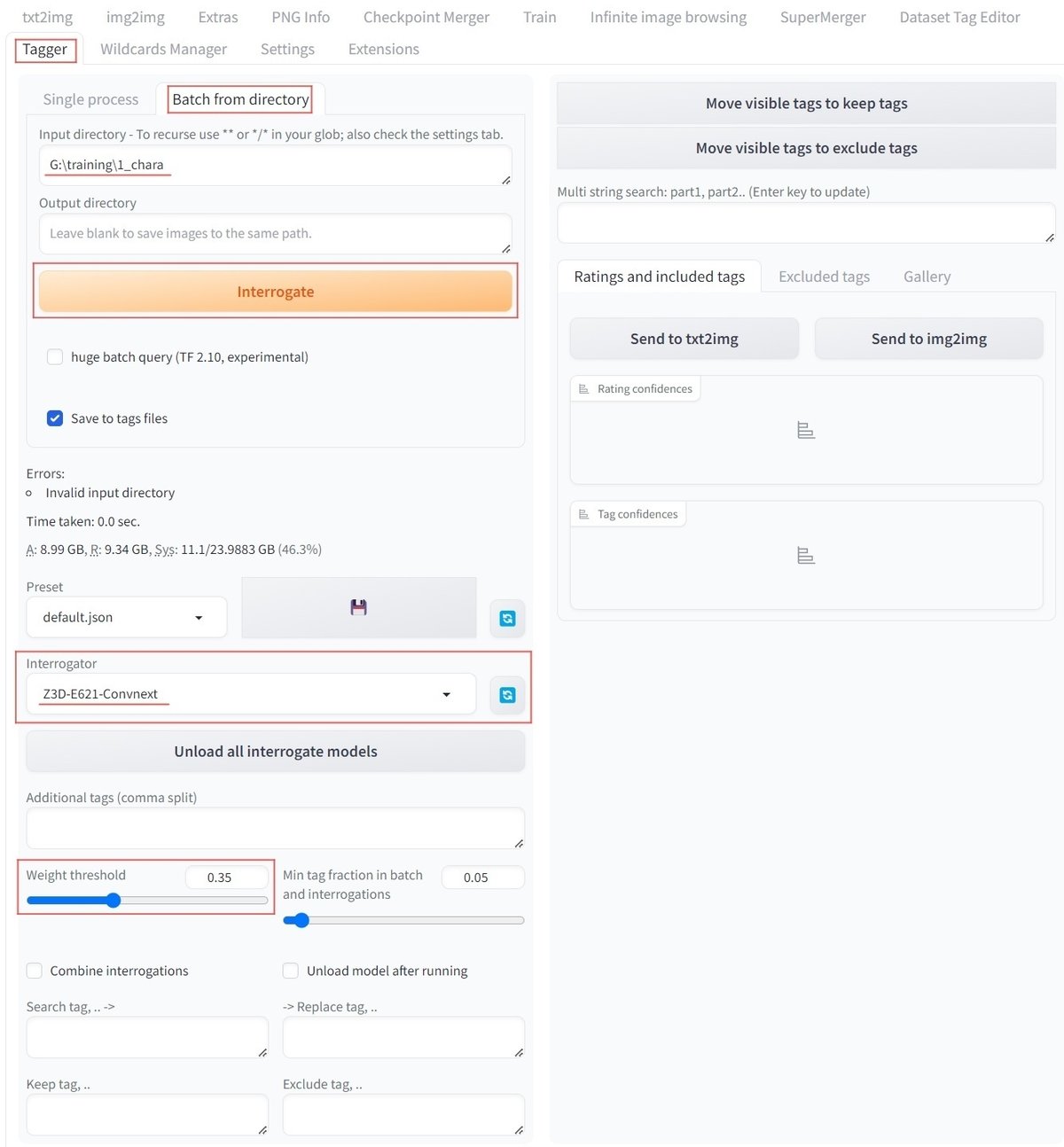
画像の要素として認識されるものの正確性に応じてタグを剪定できます
数値を上げると不確実性のあるタグが消えていきます
数値を下げると不確実性のあるタグも残るようになります

生成モデルに合わせて切り替え・追加します
入力ができたらオレンジ色の「Interrogate」ボタンを押すとタグ付け開始です。
自動的に画像フォルダ内にtxt形式のタグファイルが保存されます。

4)Dataset Tag Editorをインストール
前述のTaggerのインストールと同じ要領で今度はURLに
「https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor」
を入力してインストールします。
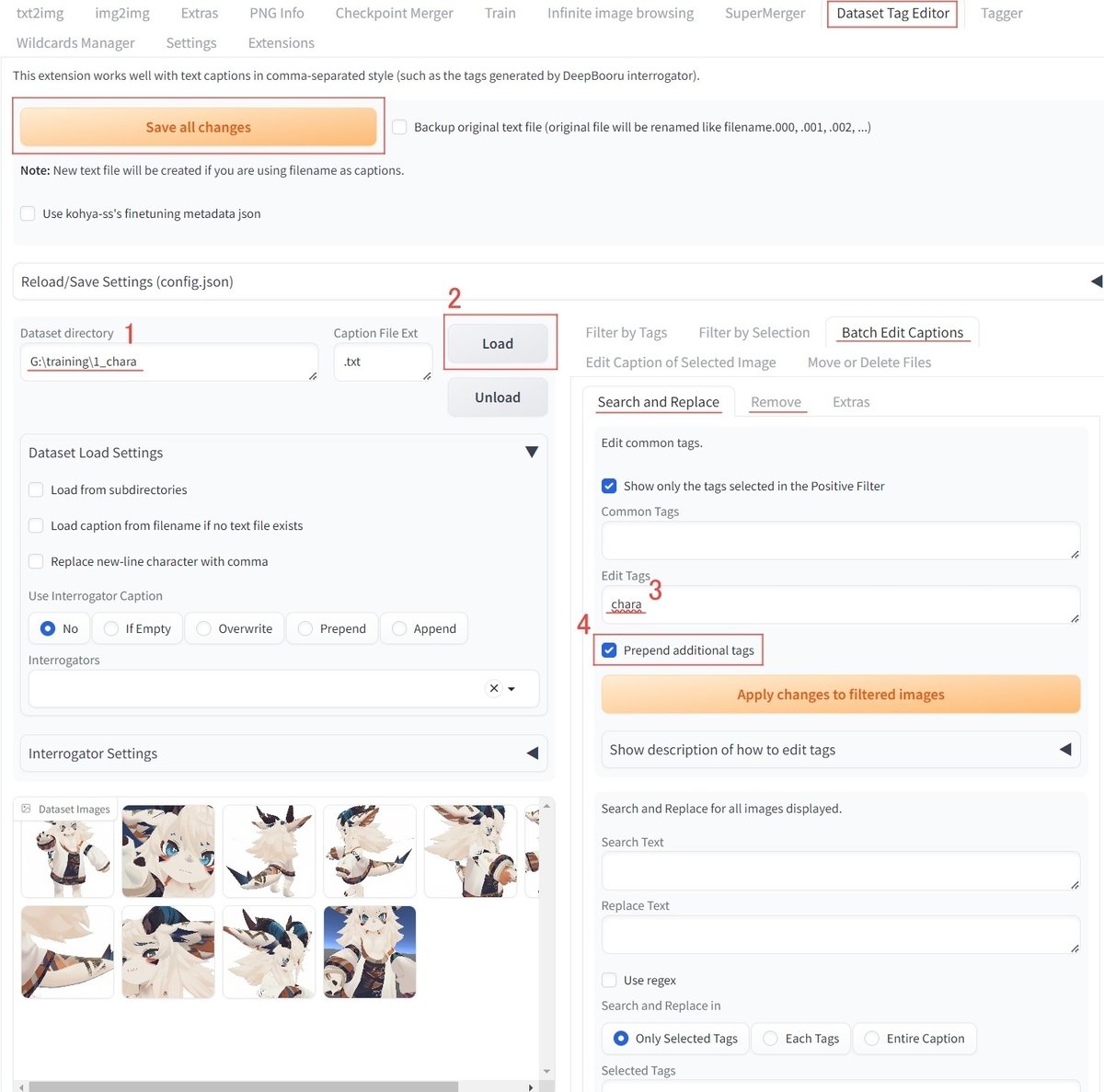
5)Dataset Tag Editorでタグ編集
5-1:Dataset directoryに画像フォルダのパスを入力。
5-2:Loadボタンを押して画像の読み込み。
Batch Edit Captionsタブに移動してタグの一括編集をします。
5-3:Edit Tagsにトリガーワードを入力。
※他に追加したいタグがある場合はここで追加できます。
5-4:Prepend additional tagsにチェックを入れる。
prompt先頭にトリガーワードが配置されるようになります。
すべてのtxtファイルのpromptに一括適用されます。
※タグの後方に追加したい場合はチェックを外します。
▼編集完了する場合
左上のオレンジ色のSave all changesボタンを押すとtxtファイルに変更が適用されます。
▼特定のタグを一括削除する場合
Batch Edit Captionsタブ内の「Remove」というタブで一括削除ができます。
誤りのタグ、特徴と異なるタグはここで削除します。
タグの整理が終わったら左上のオレンジ色のSave all changesボタンを押して完了です。
5)LoRA学習
Kohya_LoRA_param_GUIを使用します。
プログラムのインストール方法、LoRA作成のチュートリアルは作者様の記事を紹介します。
(学習プログラムとてもお世話になっています。ありがとうございます。)
記事の変更点としては学習元モデルに
Animagine-XL-3.1ではなくPony Diffusion V6 XLを使う点くらいです。
※Pony用のプリセットも用意されていました。
▼LoRA作成について(参考情報)
LoRA学習の注意点が詳細に書かれていたのでこちらも参考に紹介します。
学習対象、教師データの品質、使用モデル、目的の製作物によって人それぞれ学習方法が違います。
自分にとって最適な学習設定を探すのも楽しいです。
私の学習設定については以前の記事を参考にしてください。
最近は--optimizer_type "AdaFactor"の他に”Prodigy"も使っています。
今回のフォシュニアくん改変キャラクターLoRAは「画像数10枚」「Batch5」「2000step」「Adafactor」「すべてVRC内スクリーンショット」「背景が残ってる2枚含む」という謎の設定でお送りしています。
何かの参考になるかどうかは怪しいですが実験として楽しんでもらえたら幸いです。
6)生成結果
上記工程で作成したLoRAを用いて画像生成をします。
生成モデルはPonyV6とebara_pony2.1の2種類です。
まずは基準となる教師データの画像と学習時のpromptを紹介します。

chara, chara clothing, anthro, solo, hair, horn, blue eyes, white hair, white background, simple background, white body, fur, kemono, smile, looking at viewer, claws, standing, white fur, feet, fingers, toes, front view, tuft, multicolored body, 3 toes, full-length portrait, pawpads, furred dragon, 4 fingers, 3d (artwork), armwear, tail
実際に学習に使った画像のうちの1枚です。
手を挙げたほうの腕の下に消し残りのモヤモヤがあります(減点)。
短辺が1024px以上にアップスケールされてません(減点)。
タグはe621タグをメインにdanbooruタグも少し追加しています。
以下、Stable Diffusion (webui A1111)でキャラLoRAを使った画像出力の例になります。
■生成モデル【Pony Diffusion V6 XL】+学習時タグ(強度:1)

■生成モデル【ebara_pony_2.1】+学習時タグ(強度:1)

▼教師データそのままなのでLoRA強度を0.5に下げてみます。
■生成モデル【Pony Diffusion V6 XL】+学習時タグ(強度:0.5)

■生成モデル【ebara_pony_2.1】+学習時タグ(強度:0.5)

ebara_pony_2.1のモデル効果もあり3D感が抜けてイラスト味が増したので、ebara_pony_2.1を基準にpromptを調整していきます。
■生成モデル【ebara_pony_2.1】+タグ編集(NP)(強度:0.5)

score_9,score_8_up,score_7_up,score_6_up,score_5_up,score_4_up,
chara, chara clothing, anthro, solo, hair, horn, blue eyes, white hair, white background, simple background, white body, fur, kemono, smile, looking at viewer, claws, standing, white fur, feet, fingers, toes, front view, tuft, multicolored body, 3 toes, full-length portrait, pawpads, furred dragon, 4 fingers, 3d (artwork), armwear, tail
lora:chara:0.5
NP:
score_4,score_5,score_6, ai-generated,nipples, negativeXL_D-negxxx-neg, aidxlv05_neg, unaestheticXL_Alb2,source_cartoon,artist logo, watermark, signature, nipples,dog nose,3d,3d (artwork),
もりもりにしたネガティブプロンプトはワードで検索すると対応するembeddingが出てくると思います。
参考例:aidxlv05_neg
なんとなく入れていますが効果のほどはあまり分からないので無くてもいいと思います。
モデルの自由度を上げるために、今度はpromptを削っていきます。
■生成モデル【ebara_pony_2.1】+タグ編集(NP)(強度:0.5)

score_9,score_8_up,score_7_up,score_6_up,score_5_up,score_4_up,
chara, chara clothing, anthro, solo, hair, horn, blue eyes, white hair,white background, simple background, white body, fur, kemono, smile, looking at viewer, claws,standing, white fur, feet, fingers, toes,front view, tuft, multicolored body, 3 toes,full-length portrait, pawpads, furred dragon, 4 fingers,3d (artwork), armwear, tail
lora:chara:0.5
セーターを着せてみる。

score_9,score_8_up,score_7_up,score_6_up,score_5_up,score_4_up,
chara, chara clothing, anthro, solo, hair, horn, blue eyes, white hair, white body, fur, kemono, smile, looking at viewer, claws, white fur, feet, fingers, toes,tuft, multicolored body, 3 toes, pawpads, furred dragon, 4 fingers,armwear, tail, sweater,
<lora:chara:0.5>
ソファに座らせてみる。

score_9,score_8_up,score_7_up,score_6_up,score_5_up,score_4_up,
chara, chara clothing, anthro, solo, hair, horn, blue eyes, white hair, white body, fur, kemono, smile, looking at another, claws, white fur, feet, fingers, toes,tuft, multicolored body, 3 toes, pawpads, furred dragon, 4 fingers,armwear, tail, sweater, sofa sitting,blush,
<lora:chara:0.5>
しかし頭身が高くなってしまいました。
頭身を合わせるにはpromptやcontrolnet等で調整する必要がありそうです。
今回、LoRAの学習元モデルにPony Diffusion V6 XLを選びましたが、作成したLoRAを使ってみたところPony Diffusion V6 XLで生成するよりもebara_pony_2.1で生成した方が簡単にきれいな出力ができるように感じました。
学習モデルと生成モデルを一致させているのにうまく生成できない場合は、学習モデルの派生モデルで生成してみるのも良いかもしれません。
VRCキャラクターモデルのLoRA作成の手順検討は以上になります。
改良点はたくさんありますので、いい方法がありましたら教えてください。
ここまでお読みいただきありがとうございました。
思ったこと
▼改良できそうな点
・学習画像数をもう少し増やす。20枚くらいが目標。
・3D感を軽減するための措置が必要。
→ネガティブpromptによる対応。スタイルを打ち消すための専用LoRA。
・キャラクターLoRAにbatch5はやりすぎではないか。
→batch1~4くらいで調整する。
・タグをちゃんと整理する。
→何が必要で何が不要なのかまだよく分かってない。雰囲気でやってる。
→服装や小物など特徴的なパーツを明示する。
・タグ付けプログラムのBooruDatasetTagManagerが気になっている。
▼権利関係
殆どの3Dモデルデータには利用規約の定めがあります。
販売されているモデルの規約を確認の上、改変等の作業をしたほうが良いと思います。
今回使用しているフォシュニアくんは製作者のdisshimu様(Ama ama 15 ᄎ福)に権利がありVN3ライセンスにて公開されています。
デザイン改変についてはライセンスの範囲の中であれば許可されています。
スクリーンショットで保存したキャラクターの画像を生成AIの学習に利用する場合ですが、こちらはまだ規約で整理しきれていない状況で基本的には製作者様の意向に従う形となるかと思います。
アバター等の3Dモデルの生成AIへの利用についてどう考えればよいですか↓
参考資料
●Stable Diffusion (webui A1111)*1
●Transparent-Background*2
●Kohya_LoRA_GUI (kohya-ss)*3
●Unity*4
●VRC*5
●VRCキャラクターモデル:フォシュニアくん(shimu様)*6
●Model : Pony Diffusion V6 XL*7
●Model : ebara_pony_2.1*8
この記事が気に入ったらサポートをしてみませんか?