
Stable DiffusionのLoRAのつくりかた

はじめに
この記事は、初めてStable DiffusionのLoRAを作成する方に向けた解説です。わかりづらかったらすみません。
この解説ではSDXLベースのAnimagine-XL-3.1で二次元イラストのキャラクターのLoRAを作成します。
注意
すでにWebUIの環境構築と生成ができていて生成に慣れている前提のガイドとなります。
Windows向けのガイドです。
また、NVIDIAのGeForce RTXグラフィックボード(VRAM 8GB以上)が搭載された高性能なパソコンが必要です。
そもそもLoRAってなんぞや?
Low-Rank Adaptationが正式名称です。
難しくいうと、ウェイトとデータセットの差分を出力するものです。低ランクの行列に分解してからファインチューンすることで少ないメモリで学習できるようにしたものです。
簡単に言えば、LoRAはキャラ、衣装、シチュエーションや画風などを追加で学習したもので、生成時に使います。トッピング感覚で簡単に使用できます。
LoRAの学習ツールはkohya-ss氏作成のsd-scriptsが主流です。
LoRAの作成(学習)方法
これからLoRAの作成方法を解説します。ここではAnimagine-XL-3.1(SDXL)で作成します。
1.環境構築
githubで公開している自作のGUIで学習をします。このGUIはsd-scriptsでの学習を容易にするもです。
こちらからlatestとなっているバージョン(ファイル名はkohya_lora_gui-x.x.x.x.zip)をダウンロードし、LoRA GUIなどの名前で新しいフォルダを作成し、そこに解凍します。解凍先は日本語が含まれていない場所を推奨します。
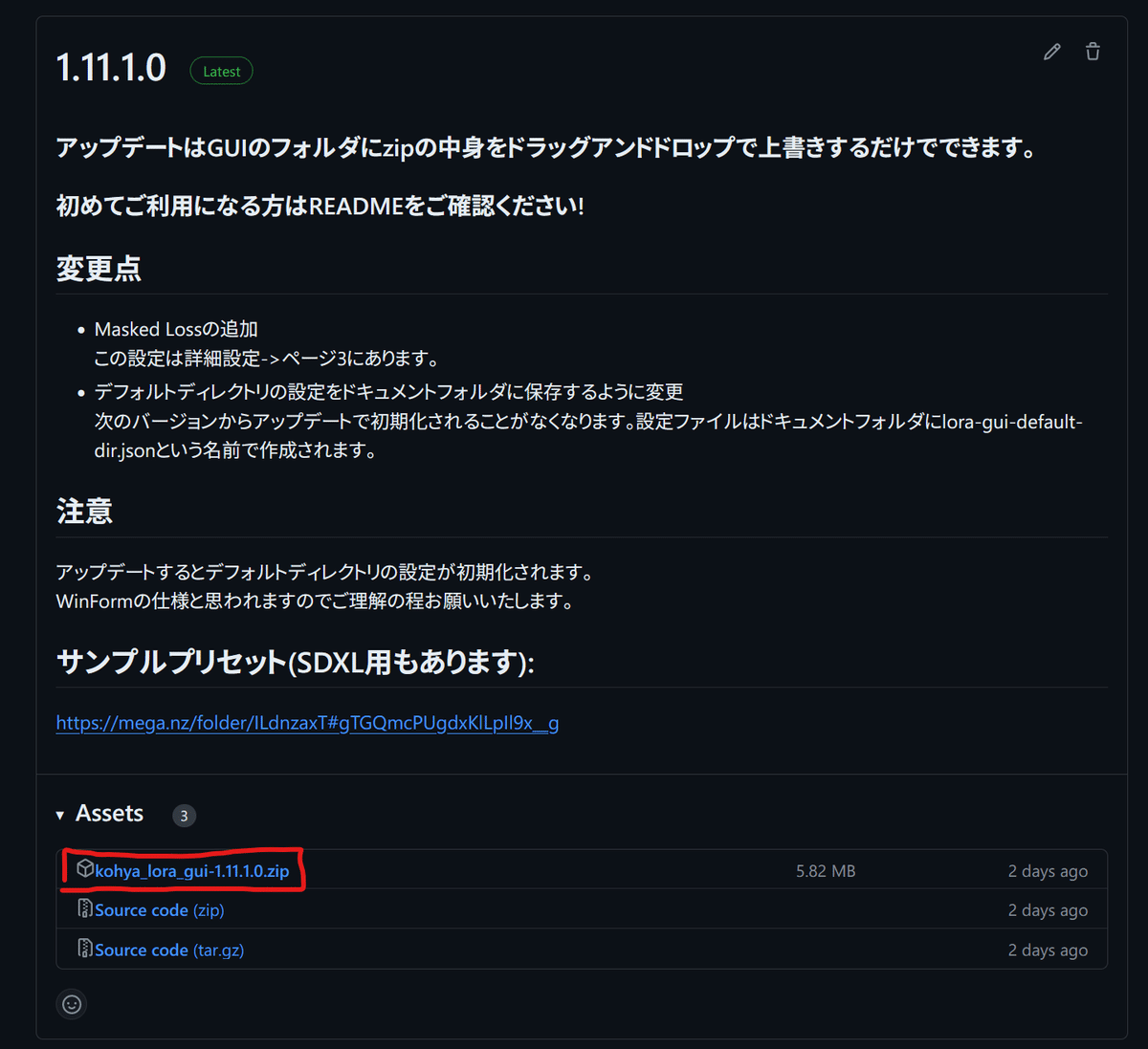
次に、解凍したフォルダに入っているexeファイルをダブルクリックしてGUIを起動します。
以下のような画面が表示されるので、画面上部にある「簡易インストーラー」をクリックして、開いた画面の手順に従って学習スクリプトのsd-scriptsをインストールしてください。
sd-scriptsのインストール先はLoRA学習GUIのフォルダが入ったフォルダです!GUIフォルダの中ではありません!

インストールが完了したら、一旦GUIを閉じておきます。
注意!このときディレクトリの階層は以下のようになります。それ以外では見つかりませんなどのメッセージが表示されます。
また、sd-scriptsの名前は変更しないでください。

2.データセット用フォルダ作成
学習するためのデータの準備をします。
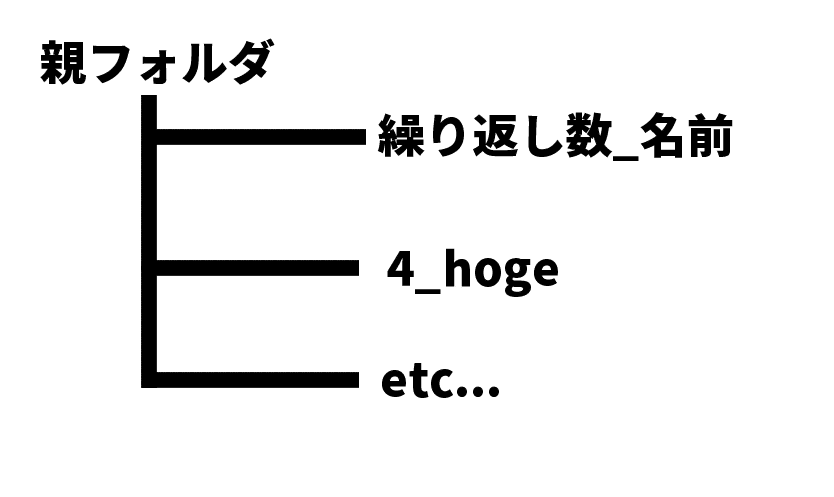
まずはフォルダを作成してください。場所は深すぎず、日本語が含まれていない場所をおすすめします。次に作成したフォルダの中に新しいフォルダを作成します。名前は「繰り返し数_名前」にします(例:4_aaaa)。
繰り返し数は1エポック(データセット全体を一巡すること)あたりのステップ数を変化させます。※1エポック=フォルダ内の画像の枚数x繰り返し数、複数フォルダがあるならそれの合計
1エポックが200-500ステップになるようにするとよいでしょう。総ステップ数の調整が楽になります。
3.画像収集
フォルダの作成が終わったら、danbooruなどから学習対象の画像を「繰り返し数_名前」のフォルダにダウンロードします。このとき画像についたタグが載ったtxtファイルを一緒にDLしておくとキャプション作成が楽になります。
画像の枚数は20枚程度でもOKですが、多い方が品質が高くなります。
ちなみに私はGrabberでbooru系サイトからタグと一緒に画像をDLしています。
備考:画像サイズを学習解像度に合わせる必要はありません。
sd-scriptsが画像の比率を保ちながら学習解像度に近い値へ拡縮します。
4-1.キャプション作成
タグが載ったtxtファイルを一緒にDLした場合はここは無視して4-2.キャプション編集の項目から進めてください。
画像の説明文となるキャプションを作成します。ここではdanbooruタグを用います。
WebUIのWD14 TaggerというExtensionで自動でタグをつけます。
Exntensionをインストールするために、AUTOMATIC1111 WebUIを起動し、Extensionsタブを開きます。
Install from URLのURL for…の場所に「https://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git」を入力してInstallボタンを押します。しばらく待ってUse installed tab to restartと出たらwebuiを再起動してください。

再起動後、Taggerというタブが出るのでそちらを開きます。
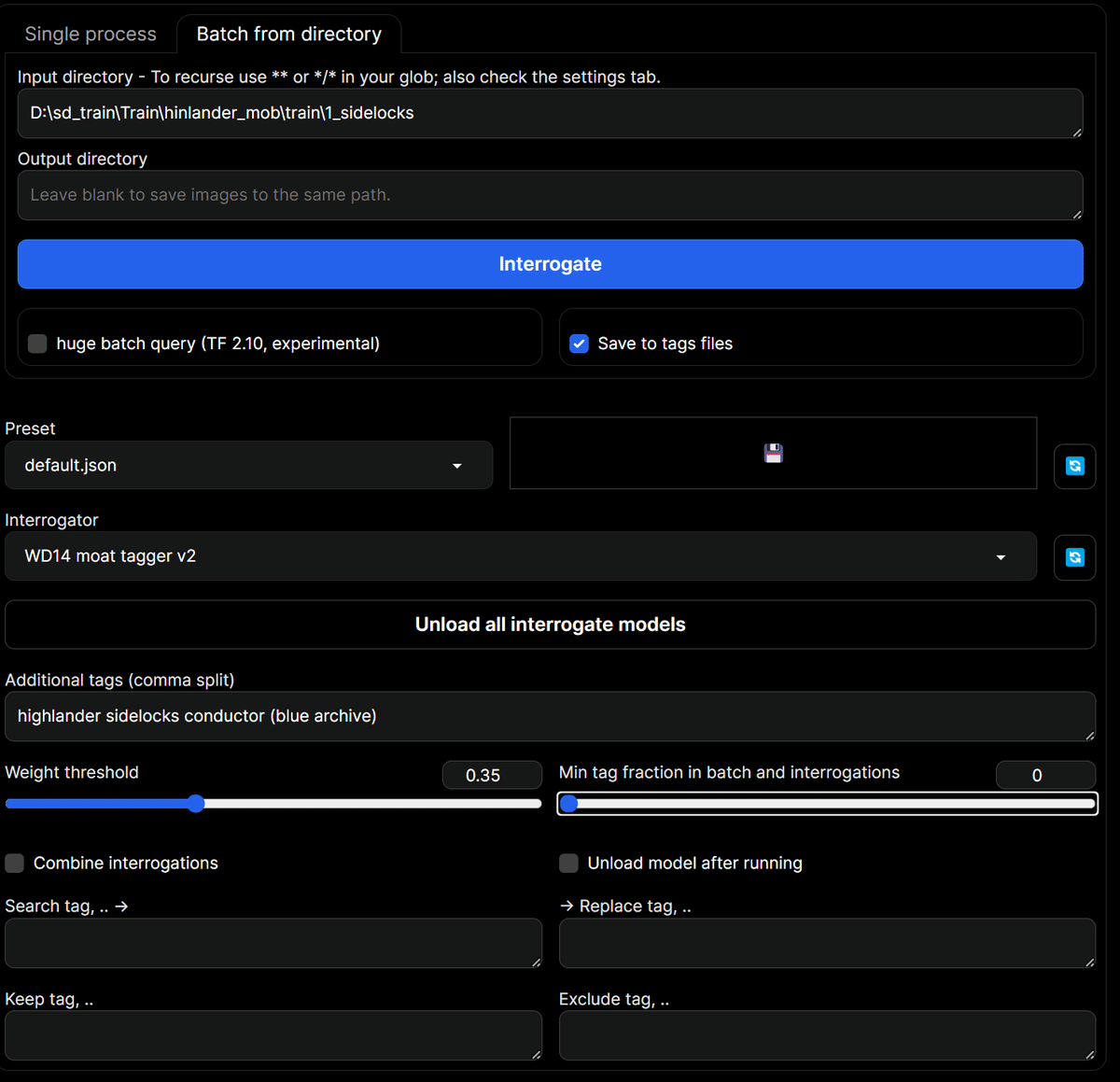
Taggerの画面でBatch from directoryのタブを開き、Input directoryにDLした画像が入ったフォルダのパスを入力します。
画面中央にあるInterrogatorにmoat tagger v2を選択し、下部にあるMin tag fraction in batch and interrogationsを0にしておきましょう。
生成時に学習対象を呼び出す単語(トリガーワード)をAdditional tagsに入力します。
入力し終えたらInterrogateを押してしばらく待ちましょう。自動タグ付けが終わったらWebUIを閉じます。
4-2.キャプション編集
4-1でキャプションを自動生成した場合はこの項目はスキップしてください。
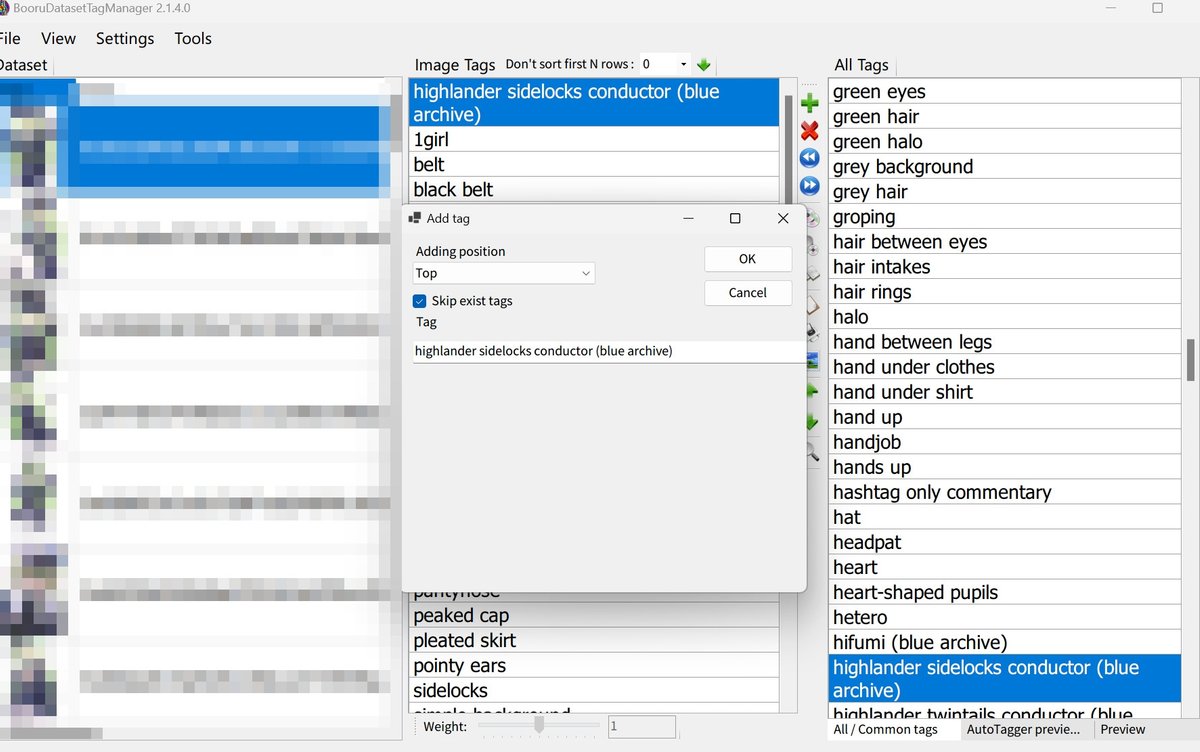
BooruDatasetTagManagerなどで生成時に学習対象を呼び出す単語(トリガーワード)を追加して先頭に配置しましょう。
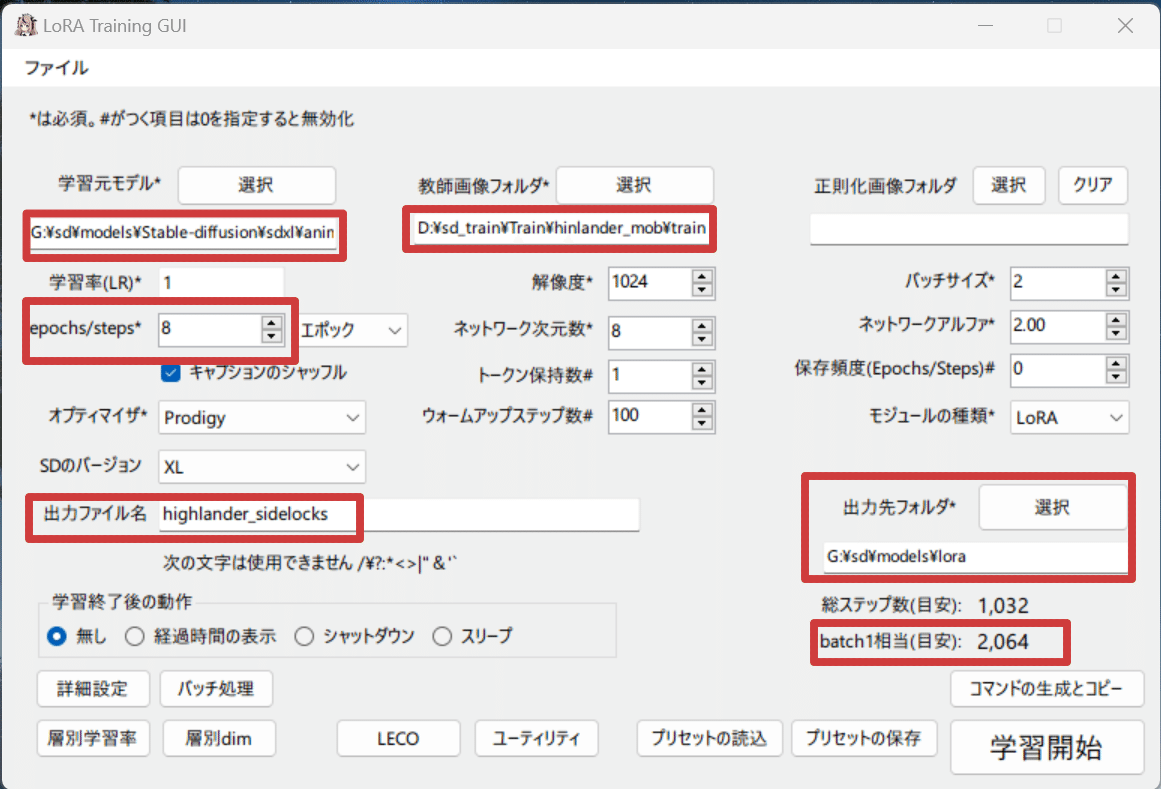
5.学習パラメータの設定
GUIを起動します。画面下部にあるプリセットの読込から、こちらで配布しているサンプルプリセット「Animagine汎用プリセット.xmlora」を開きます。
するとある程度パラメータが設定されるので、設定されていない箇所を設定しましょう。
学習元モデルにAnimagine-XL-3.1、教師画像フォルダに先ほど作成したフォルダ(繰り返し数_名前の親フォルダ)、出力先フォルダにwebuiのloraフォルダなどを指定します。出力ファイル名はお好みで。
設定したら画面右下のbatch1相当(目安)に学習ステップ数が表示されるので、これが2000-3000になるようにepochs/stepsの値を調整してください。
6.学習
画面右下の学習開始をクリックするとターミナル(黒い画面)が表示され、学習が開始します。

時間がかかるので気長に待ちましょう。
この時表示される「A matching Triton is not available. Error caught was: no module named 'triton'」は気にしないでください。Tritonがないと言っていますが正常です。TritonはWindows版が存在せず、無くても問題もありません。他にWarningも表示されますが影響はありません。
ターミナルに表示されるstepsのプログレスバーが100%になってmodel saved.と出たら完了です。
早速WebUIで使用してみましょう。
7.LoRAを使用
WebUIを起動し、sd checkpointを学習元モデルにしてから、txt2imgのLoraタブを開き先ほど作成したLoRAを選択します。
選択するとプロンプトに<lora:名前:強度>のような文字列が追加されます。これはその名前のLoRAを指定した強度で適用するという意味です。
プロンプトにトリガーワードを入力して生成しましょう。学習対象が出てくれば成功です。
お疲れ様でした。
