
Webスクレイピング勉強⑤~画像データ取得~

引き続き以下の動画で勉強。(今回で最後)
1.事前準備
いつも通りページからURL情報を取得
import requests #requestsインポート
from bs4 import BeautifulSoup #beautifulsoupインポート
url = 'https://scraping-for-beginner.herokuapp.com/image'
res = requests.get(url) #urlのHTML取得
soup = BeautifulSoup(res.text,'html.parser') #取得自他情報をHTMLタグとして格納Pillowというライブラリが必要になるようでインストール
pip install Pillow
2.画像取得
取得したHTMLからimgタグを取得
imag_tag = soup.find('img')imgタグの情報が取得できた

src(画像の相対パス)を取得
imag_tag['src']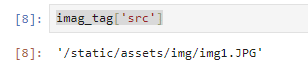
ルートURLを指定して、フルパスになるように結合
root_url = 'https://scraping-for-beginner.herokuapp.com'
img_url = root_url + imag_tag['src']
img_url
リンクを押すと画像ページに飛んだ

3.画像保存
下記インポートする
from PIL import Image
import io画像URLをgetし、content関数をつけると、画像のバイナリデータが取得できる。
requests.get(img_url).content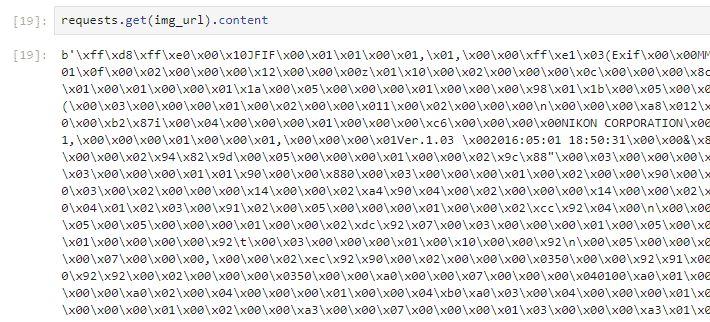
この情報をBytesIOにいれることで、画像データに変換される。
io.BytesIO(requests.get(img_url).content)さらにそれをImage.open関数に入れることで、画像が表示される。
img = Image.open(io.BytesIO(requests.get(img_url).content))
img
4.画像を保存
ドキュメント内にworkフォルダを作成済み
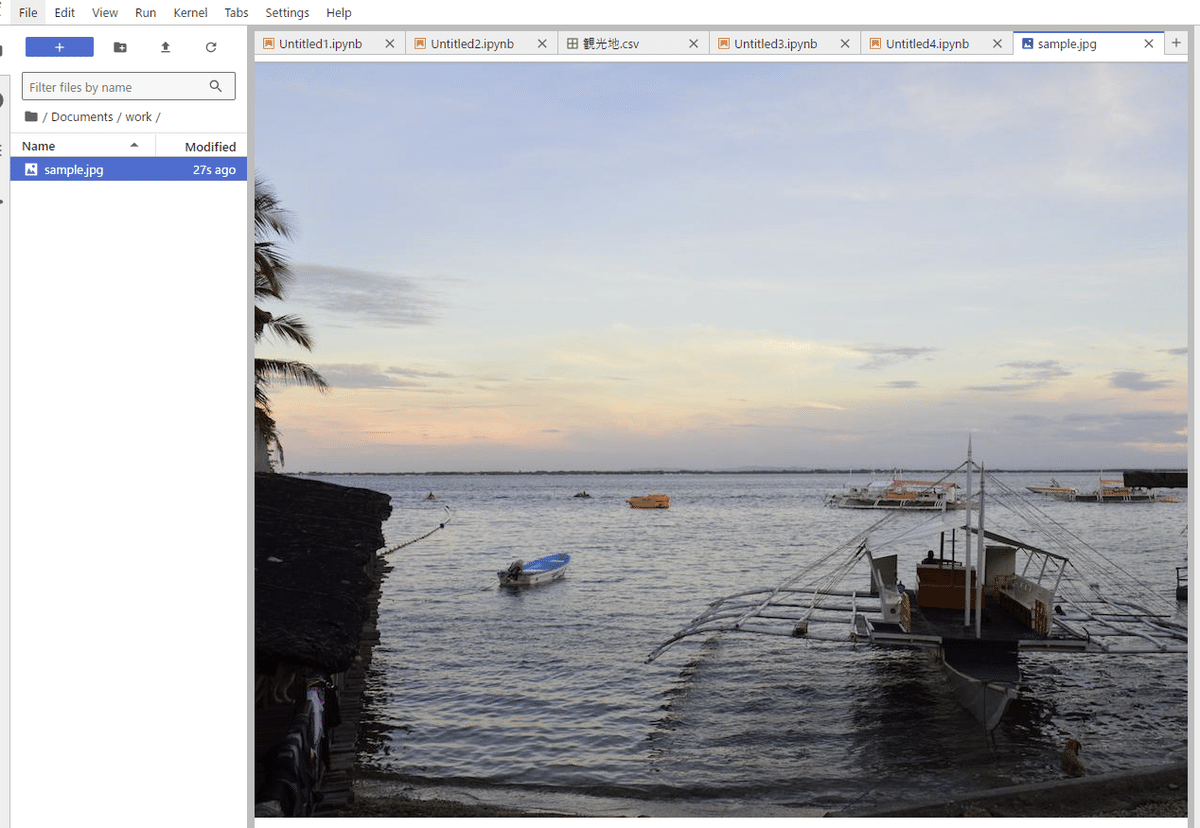
画像を保存
img.save('Documents/work/sample.jpg')保存データを確認
5.全画像を取得する
まずは1枚取得時の情報を整理し、これを複数画像に適用する。
from PIL import Image
import io
url = 'https://scraping-for-beginner.herokuapp.com/image'
res = requests.get(url) #urlのHTML取得
soup = BeautifulSoup(res.text,'html.parser') #取得自他情報をHTMLタグとして格納
imag_tag = soup.find('img')
root_url = 'https://scraping-for-beginner.herokuapp.com'
img_url = root_url + imag_tag['src']
img = Image.open(io.BytesIO(requests.get(img_url).content))
img.save('Documents/work/sample.jpg')以下の書き換えで全画像を取得。
from PIL import Image
import io
url = 'https://scraping-for-beginner.herokuapp.com/image'
root_url = 'https://scraping-for-beginner.herokuapp.com'
res = requests.get(url) #urlのHTML取得
soup = BeautifulSoup(res.text,'html.parser') #取得自他情報をHTMLタグとして格納
imag_tags = soup.find_all('img')
for i, imag_tag in enumerate(imag_tags):
img_url = root_url + imag_tag['src']
img = Image.open(io.BytesIO(requests.get(img_url).content))
img.save(f'Documents/work/{i}.jpg')
全画像取得完了

以上
この記事が気に入ったらサポートをしてみませんか?