
Webスクレイピング勉強①~自動ログイン~

以下の動画を参考にPythonによるWEBスクレイピングの勉強。
長い動画なのでまずは最初の部分だけ。
①環境整備
・Jupyterlab上でselniumをインストールする。
Selenium は Web ブラウザの操作を自動化するためのフレームワークです。
!pip install selenium・ブラウザドライバをインストールする(Windows)
動画の中では、Chrome用のWEBドライバを別途ダウンロードして読みこむ手順になっているが、どうもselenium4.6以降は自動で最適なドライバがダウンロードされるようになったらしい。
from selenium import webdriver
・Timeライブラリをインポートする
ブラウザの読み込み待ちに使用
from time import sleep②WEBブラウザ立ち上げ
下記コマンドでブラウザが起動することを確認。
browser = webdriver.Chrome()
停止するときは下記
browser.quit()③WEBへアクセス
ブラウザを開いてGoogleへアクセス。
browser = webdriver.Chrome()
browser.get('https://www.google.com/')
URLを変数に入れてアクセス
url = "https://scraping-for-beginner.herokuapp.com/login_page"
browser.get(url)
④フォームへ自動入力
WEBページの中身を確認
開発者モードで開く
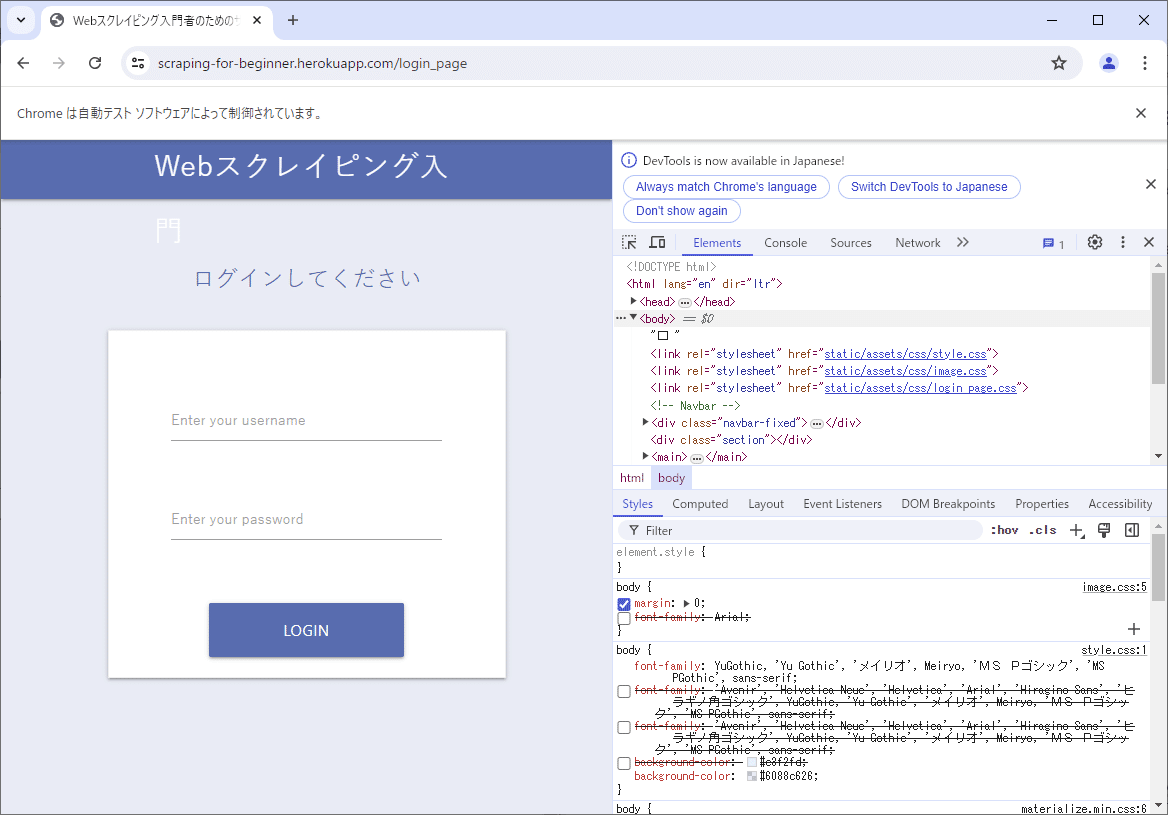
矢印ボタンを押す→入力フィールドにマウスを当てて、タグを特定する

ログインフォームのユーザ名入力欄を取得
下記コマンドで、usernameの要素を取得
from selenium.webdriver.common.by import By
elem_username = browser.find_element(By.ID,'username')
elem_password = browser.find_element(By.ID,'password')動画の中では'find_element_by_id'を使用しているが、同じように実行するとエラーが発生する。
下記の記事を参考にしたら即解決。
取得したフォームへ値を自動入力させる
elem_username.send_keys('imanishi')
elem_password.send_keys('kohei')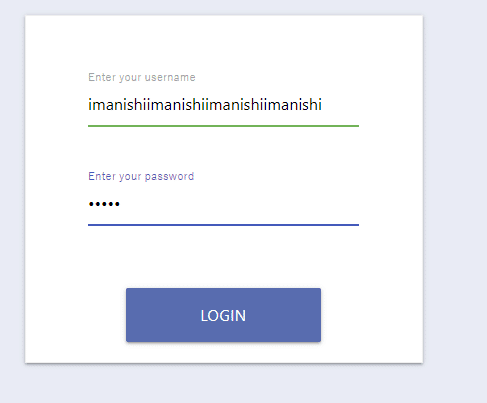
ログインボタンを自動で押す
ボタンの要素を取得し、クリックさせる。
elem_button = browser.find_element(By.ID,'login-btn')
elem_button.click()
まとめ
browser = webdriver.Chrome() #ブラウザ起動
url = "https://scraping-for-beginner.herokuapp.com/login_page" #URL指定
browser.get(url) #指定したURLを開く
sleep(4) #ブラウザ起動まで4秒待機
elem_username = browser.find_element(By.ID,'username') #ユーザ名入力フィールド取得
elem_password = browser.find_element(By.ID,'password') #PW入力フィールド取得
elem_button = browser.find_element(By.ID,'login-btn') #ログインボタン取得
elem_username.send_keys('imanishi') #ユーザ名入力
elem_password.send_keys('kohei') #パスワード入力
sleep(1) elem_button.click() #ログインボタンクリックおまけ
Headlessモードを使用すると、ブラウザを立ち上げずに裏で処理させることが出来る。
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
url = "https://scraping-for-beginner.herokuapp.com/login_page" #URL指定
browser.get(url)
browser.quit() #見えないので明示的に閉じる必ようありこの記事が気に入ったらサポートをしてみませんか?