
日刊 画像生成AI (2022年11月4日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開され、日々とても早いスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
過去の投稿はこちら
開発
OpenAIがついにDALL-EのAPIを公開。そして早速..
ずっと公開されずにいたOpenAIのDALL-EのAPI。この度ついに公開されました!StableDiffusionじゃなく、DALL-Eの可能性を考えた何かサービスが生まれるかもしれない。
・256x256, 512x512, 1024x1024で生成可能
・同時に1~10個生成まで、5分だと25枚
・inpainting, バリエーション生成ができる
TheVergeやVerntureBeatにも詳しく書かれています。よかったらどうぞ
そしたら早速APIをPhotoshopで使えるように実装した方がいました。
Flying dogの方っぽいので、元々PhotoshopでSDが使えるサービスを作っていた方。そのプラグインにDALL-E2も含まれるようになるそうです。
World premiere: full DALL-E 2 integration in Photoshop! Also in combination with Stable Diffusion. Huge plugin update on Monday https://t.co/MMlc9ElH2V #dalle2 #photoshop #stablediffusion pic.twitter.com/EQ0lgdEUAG
— Nicolay Mausz (@NicolayMausz) November 4, 2022
Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP実装

クラスネームとして単語を入力したら複数自動で正確に範囲指定してくれるみたいです。既にWebUI by AUTOMATIC1111に入っているスクリプトのtext2mask(github, arxiv)に比べてかなり精度が高そうです。
> Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP
— birdMan (@birdMan710Nika) November 4, 2022
zero-shotなセグメンテーション、えげつねぇのが来たhttps://t.co/4UESWHCwEx pic.twitter.com/xREQ7JCrxh
The @Gradio Demo for Open-Vocabulary Semantic Segmentation with Mask-adapted CLIP is out on @huggingface Spaces by @LiangJeff95
— AK (@_akhaliq) November 4, 2022
demo: https://t.co/i3ZWl6YANa
colab: https://t.co/d3wo8f7KEB pic.twitter.com/7rJePzBC6D
mimicがついに再開!
mimicがついにサービスを再始動!
どういう点が変わったのか説明しますと、まず絵師さんしか使えないようにTwitterの審査が必要になったのと、学習で使った画像が公開、そしてそのジェネレーターも公開される仕様となりました。そして、利用規約違反があった際の報告フォームも作成。悪用防止対策として透かしを強化と、ガッツリ対策をされています。
安定稼働の確認のために連絡が遅くなりましたが、一昨日より「mimic(ミミック)ベータ2.0」(https://t.co/fhVVFKcr4U)を公開しております。
— mimic(ミミック) (@illustmimic) November 4, 2022
事前審査を通過した方のみイラストメーカーの作成が可能ですが、作成されたイラストはどなたでも閲覧可能です。ぜひご覧ください。(1/3)
【新作動画✨】11/4 20時プレミア公開
— ディープブリザード・イラスティア✨ (@mao_DBmiyuki) November 4, 2022
β再開!今度は大丈夫❗️❓イラスト生成AI「mimic(ミミック)」の中の人に疑問ぶつけてみた!✨/ディープブリザード https://t.co/yPcStX9njt
対談企画第2弾!βテストが始まったけど本当に絵師のためのAIサービスなの!?中の人に全部ぶっちゃけて聞いてみた!✨ pic.twitter.com/vg2aXU3PsK
まっくすさんが足りない時のテクを話されていました
mimicに食わせるイラストが足りない!という方へのテクですが、同じ画像でもOKなので画像例のようなカサ増しができます。(またカサ増しと同時に正面顔を入れるとほんの少しだけ安定しやすいのでそういう画像を増やしています) pic.twitter.com/vJCjMNn3AH
— まっくす (@minux302) November 4, 2022
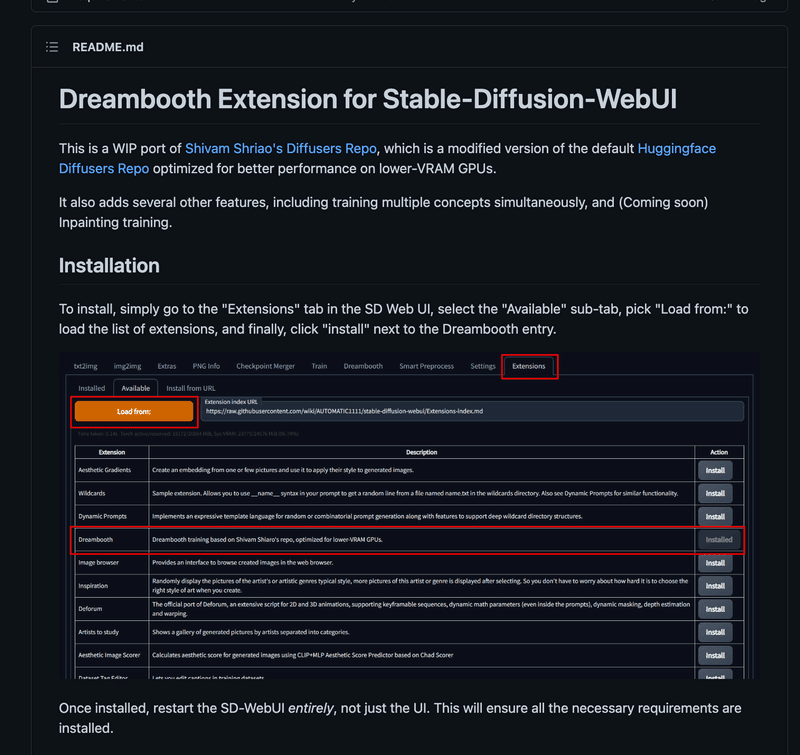
WebUIにDreamBoothが追加!
WebUIについにdreamboothのプルリクエストが来ました。
https://twitter.com/_akhaliq/status/1588376931615256576
そして、エクステンションとして追加されやったね
「Dream Textures」がv0.0.9で完全自動で3Dモデルにテクスチャリング
BlenderでStableDiffusionが使えるアドオン「Dream Textures」がv0.0.9で、テキスト入力してボタンを押せば3Dモデルを自動でテクスチャリングできるように開発が進んでいるみたいです。
Experiments with using Stable Diffusion to texture 3D models fully automatically in Blender.
— Carson Katri (@CarsonKatri) October 26, 2022
Just enter a text prompt, hit a button, and it wraps your model in a texture:#blender #stablediffusion pic.twitter.com/v5ktUUEpsY
Whisper fine-tuning is **here**!
— Sanchit Gandhi (@sanchitgandhi99) November 3, 2022
Check out the blog post for a step-by-step guide on fine-tuning Whisper with 🤗 Transformers: https://t.co/03AwUTORLj
Boost WER performance vs zero-shot with as little as 8h of training data 🤯
All on a single Google Colab notebook...
Text to Image to Music to Videoが公開
テキストから画像を生成して、画像から音楽を生成、それらをまとめて動画も生成してくれるようです。
I made a @Gradio tool at @huggingface let you convert text into image & music video: https://t.co/LcCUjPJoWZ
— Helixngc7293 (@DGSpitzer) November 4, 2022
Using ERNIE-ViLG 2.0+#Mubert
Supports 🇨🇳🇯🇵🇰🇷 language as prompts~
Special thanks to @fffiloni Img to Music space, I also merged code from #Paddlehub #AI #StableDiffusion pic.twitter.com/S2vPlw3vzH
AIアートインポスター発売開始
めっちゃやりたい。以前予告されていた画像生成AIを活用した人狼風ゲーム、AIアートインポスターがついに発売開始されました。
「AI絵師」に絵を描かせる人狼風ゲーム『AIアートインポスター』発売開始https://t.co/yJcjh3hpVI
— 電ファミニコゲーマー (@denfaminicogame) November 4, 2022
お題に沿って「指示」を出し、自動生成された絵を見せ合おう。ただし仲間の中にはお題を知らない者が。誰が潜伏犯か何がお題か、制御困難なAIの絵を通じて互いの腹の内を探る pic.twitter.com/yOXRUYFzpT
ゲームの遊び方はこちら!
— ポケットペア公式 - Craftopia/クラフトピア (@PocketpairJapan) November 3, 2022
ここからDL!
Steam: https://t.co/sJ7DIUfuLA
Android: https://t.co/XxEQCOptAY
iOS: https://t.co/k2BbNVOFCT
※ 現在モバイル版はGPUの赤字爆発を防ぐ為招待制になっており、
Steam 版を購入したユーザーから招待された方のみゲームを遊ぶことが出来ます。 pic.twitter.com/LxY0RhfknM
突然ですが、!!!世界初!!! AI アートを活用した『AIアートインポスター』を本日リリースしました!
— ポケットペア公式 - Craftopia/クラフトピア (@PocketpairJapan) November 3, 2022
AIは賛否両論ですが、AIイラスト生成は面白過ぎるので、是非体験してみてください!!
動画はイカAIが絵を描く様子です!とっても可愛いので最後まで見てね✨
なんとiOS/Androidも遊べます! pic.twitter.com/BpKzLgp7n0
『AIアートインポスター』
— ポケットペア公式 - Craftopia/クラフトピア (@PocketpairJapan) November 4, 2022
Steam のゲームを v0.1.3 にアップデートしました。
このアップデートでゲームがプレイ不可能になる不具合を修正いたしました。https://t.co/WfHTPscHsX
引き続き『AIアートインポスター』を宜しくお願いいたします。
Charactor.AIに作画キャラ登場
会話型AIを作れるサービスCharactor.AIに、話しかけると画像を生成してくれるキャラクターが登場したようです。
Introducing Image Generating Characters!
— Character.AI (@character_ai) November 3, 2022
Image Generating Characters generate images as you talk to them, offering a more engaging and immersive experience.
Try them at https://t.co/u1NTCjis64 pic.twitter.com/VLBQ7ZCtr7
Macで一発インストールでローカルでStableDiffusionが使える「DiffusionBee」が大幅アップデート
M1 Maxでも生成速度はそこまで速くなく、機能もかなり限定的だったDiffusionBeeがこの度大幅アップデート。早い生成速度を手に入れて、inpaiting, outpainting, 諸々オプションも追加されたそうです。これは期待
Introducing a new version of DiffusionBee - Stable Diffusion app on Mac with all cutting-edge features.
— Divam Gupta (@divamgupta) November 3, 2022
- Easy to use and install
- Runs locally
- Runs much faster now
Supports Text-to-image, Image-to-image, in-painting, out-painting, advanced options.https://t.co/N3KwWR9Own pic.twitter.com/qbwwWVN60c
Invoke AI 2.1がリリース
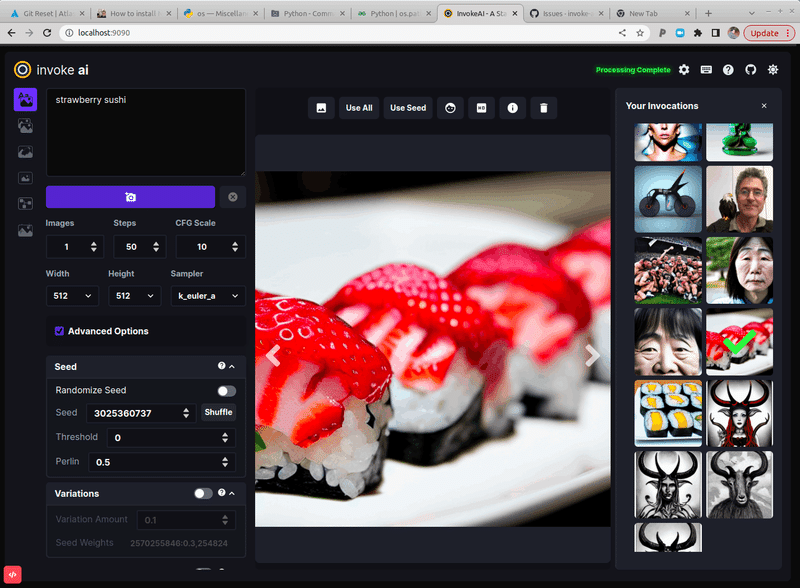
有名で豊富な機能を持つStableDiffusion実装の1つ、InvokeAIが2.1をリリース。InvokeAIは512x768 の画像を生成するのにわずか3.5 GBのVRAM しか必要とせず 、Windows/Linux/Mac (M1 & M2) と互換性があります。
2.1アップデート内容
・WebGUIでのinpaintingサポート
・WebGUIでのナビゲーションとユーザー エクスペリエンスが大幅に向上
・プロンプトの構文は、プロンプトの重み付け、クロスアテンション、およびプロンプトのマージで強化されました。
・CLI または WebGUI を離れずに、複数のモデルをロードし、それらをすばやく切り替えることができるようになりました。
・インストール プロセス (経由scripts/preload_models.py) では、いくつかの一般的なStable Diffusion モデルから選択してダウンロードし、代わりにインストールできるようになりました。他のモデルの中でも、このスクリプトは、現在の Stable Diffusion 1.5 モデルと、顔の生成を改善する StabilityAI ・variable autoencoder (VAE) をインストールします。
・修復のためにマスクされた領域を正しく取得するために写真編集者と格闘するのにうんざりしていませんか? AI がテキスト マスキングを使用してマスクを作成します。この機能を使用すると、画像の塗りつぶす部分を英語のフレーズだけで指定できます。
・被写体の頭が切り落とされるのを見るのにうんざりしていませんか? 露頭機能を使用して、CLI でそれらをアンクロップします。
・より大きな次元の画像を生成するときに、被写体の体が複製されたり壊れたりするのを見るのにうんざりしていませんか? CLI でオプションを確認する--hiresか、WebGUI で対応するトグルを選択します。
・SD Conceptsの Hugging Face アーカイブから、テキストの反転と微調整 .bin スタイルとサブジェクトをサポートするようになりました。オプションを使用して .bin ファイルをロードし--embedding_pathます。(次のバージョンでは、複数の同時モデルのマージとロードがサポートされる予定です)。
Diffuser 0.7.0vが公開
・Apple Silicon のサポートが大幅に改善されました。
・メモリ効率の良い生成: フラッシュを使用した GPU で最大 2 倍の生成速度
・DanceDiffusion: ディフューザーがオーディオに対応
・読み込みの高速化: パイプラインの読み込みが 2 倍高速化
🧨Diffusers 0.7.0 is out with ♥️ from the community!
— Suraj Patil (@psuraj28) November 3, 2022
- 🍎much better support for Apple Silicon.
- 🚀 Memory efficient generation: Up to 2x Generation speed on GPU with Flash Attention
- 🎵 Dance Diffusion: diffusers goes audio,
- 💨 Faster Loading: 2x faster pipeline loading
npakaさんのまとめがこちらにあります。どうぞ!
Chicken Diffusionが公開
Redditのチキンの投稿画像を学習したモデルが公開。プロンプトに「chkn」を利用することで使えます。


BlenderでSDが使えるプラグイン「CEB Stable Diffusion」に3D顔生成機能が搭載されるようです
CEB SD 1.0 WIP
— Carlos Barreto (@carlosedubarret) November 4, 2022
Another method for 3d face generation (I think its much better and faster than the one I showed yesterday) pic.twitter.com/1KQfjdphqt
PlatさんのNovelAIプロンプト読み込み機
NovelAIのプロンプト読み込めるやつ作ったhttps://t.co/9sOjHjbKan pic.twitter.com/7ltZe5faEQ
— Plat 🖼️ (@p1atdev_art) November 4, 2022
表現
深津さんがコラージュAIの実験中
こういう系の素敵コラージュを無限に生み出すステキAI。フォトコラージュ系のアートは、日本では著作権法で殺されてしまったが、AIによってまさかの復活のチャンス。#StableDiffusion pic.twitter.com/2H8VBrnByY
— 深津 貴之 / THE GUILD / note.com (@fladdict) November 4, 2022
こう頭の中にあるカオスと、AIの中にあるカオスをどう発掘するか?は、プロンプトだけだと発掘しきれない領域が多くあるっぽい。 pic.twitter.com/V7dou419Ac
— 深津 貴之 / THE GUILD / note.com (@fladdict) November 4, 2022
結局AI使えば、だれでもステキな絵が描けるか…というと、そんなこともなく。写真や絵画や人体に関する知識、言語化・指示能力、プログラム能力、ファインチューン、GPU資産などさまざまな要素がないと、あかんという結論。 pic.twitter.com/SiJVPVBxRi
— 深津 貴之 / THE GUILD / note.com (@fladdict) November 4, 2022
852話さんのNovelAI探求
新しい表現の合成や、最近複雑な風景内に配置する実験をずっとやられている印象です。とても素敵。
AI 無編集
— 852話 (@8co28) November 4, 2022
AIが描くバグ空間・電脳世界と少女の組み合わせいいな AIが出力してくれる所がエモい pic.twitter.com/ZpkbposfKn
AI 無編集
— 852話 (@8co28) November 4, 2022
散らかった部屋と女の子たち pic.twitter.com/CaijYwFlCB
4s4ki「電脳郷」
forasteranさんが紹介されていたのを発見しました、こちら引用させていただきます。SDやDeforumを活用したMVが公開されているようです。日本だと初めて見たかも。
4s4ki 「電脳郷」 のMV作った。https://t.co/3Tc6Jr4lVe
— Yusuke Oikawa (@yusukeoikaw) November 1, 2022
電脳(?)こと #stablediffusion にも大量に画像生成してもらい、だいぶ仲良くなった。Blenderもちょっとづつ使い方覚えてきた。
過剰脚長課金スキン気に入ってる。正八胞体気に入ってる。
おつかれさま脳。ありがとう記憶@0311asaki pic.twitter.com/qizmsfJdwg
研究
【ソロ】浅野いにおの近況報告【4】
漫画家の浅野にいお氏がAI(stable diffusionなど)を使って漫画の素材を試しに作ってみた話が非常に興味深い。新しい技術を貪欲に取り組む姿がすごい。BlenderからUnreal Engineまで使っててすごい。https://t.co/1PvLDtypUT
— むらかみふくゆき Fukuyuki (@fukuyuki) November 3, 2022
NovelAI, Waifu Diffusionで使えるスタイルガイドまとめ
RedditにてNAI, WDのスタイルガイドまとめが公開されていたのでメモ。
思想・ムーブメント
「画像生成AI」で社会はどう変わる?“無料公開”企業CEOに聞く懸念と未来
StableDiffusionについて特集がテレビで組まれたようです。Stability AIのCEOのEmad Mostaqueさんがテレビに出演し、インタビューに答えられています。また深津さんが作ったDreamBoothが出ていたり、松尾豊さんも出られています。詳しくは以下のリンクからどうぞ。
【#画像生成AI “無料公開”のワケ…独占取材】
— 報道ステーション+土日ステ (@hst_tvasahi) November 4, 2022
“Stable Diffusion”を開発
Stability AI社 エマード・モスタークCEO
「人々と手を携え、真の価値を提供したい。目指すのは #AIの民主化」
▼“Stable Diffusion”はいまや世界で約100万人が利用。キーワードを与えれば4秒で画像を生成@EMostaque
【画像生成AIでの #フェイク画像 どう対抗?】
— 報道ステーション+土日ステ (@hst_tvasahi) November 4, 2022
台風15号の際“静岡の水害”として、“Stable Diffusion”で生成されたフェイク画像が拡散
Stability AI社 エマード・モスタークCEO
「画像が本物かを確認する必要を我々が学習した。私たちはシステムに #フェイク判別機能 を追加予定」#報ステ
【#画像生成AI 懸念と同時に可能性も】
— 報道ステーション+土日ステ (@hst_tvasahi) November 4, 2022
東京大学 人工知能学専門
松尾 豊 教授(@ymatsuo)
「AIで生成した画像は写真と区別がつかなくなる。今後は“出元”を確認することが大事に」
「新しい技術は懸念と同時に #大きな可能性 を持つ。過度な規制は、そうした可能性を摘むことになる」#報ステ
報道ステーションで、StableDiffuison の報道をしたおり、大越キャスターを学習させたカスタムdreamboothを作らせていただきました。色々な大越さんが出力できます#stablediffusion pic.twitter.com/CtiztJZbd7
— 深津 貴之 / THE GUILD / note.com (@fladdict) November 4, 2022
ついにGitHubのコードで学習したAI「GitHub Copilot」が集団訴訟に直面
EmTech 2022:人類と機械の橋渡しをする
「AI をどうするかを決定するのは私たち科学者ではありません…それは社会全体の決定です。テクノロジーは…良くも悪くも使われる可能性があります。」
"It is not for us scientists to decide to what to do with AI… it is [a decision] for society at large. The technology... can be used for good or bad." - @ylecun at #EmTechMIT https://t.co/TUWC50iuuF pic.twitter.com/66AN3P1uei
— MIT Technology Review (@techreview) November 3, 2022
Microsoft がセキュリティやビデオ ゲーム デザインなどの他の職種向けに GitHub Copilot を開発することを計画しているため、ジェネレーティブAIの可能性と危険性を考察
マイクロソフトは、AI があなたの仕事を変えてくれることを望んでいます。
ジェネレーティブ メディア: オーディオとビデオの生成がテクノロジの次の大きな飛躍である理由
ビッグデータが優先事項でなくなった理由と、注目すべきその他の重要な AI トレンド
人間と機械の境界線があいまいになっていませんか?
人工知能の台頭(どこでも)、今後10年のメタトレンドに関するスレッド
The rise of artificial intelligence (everywhere)
— Peter H. Diamandis, MD (@PeterDiamandis) November 3, 2022
Thread on Metatrends in the coming decade🧵
勉強
ViEW2022 画像生成モデルの最新動向
ViEW2022の参加登録が始まってるようですhttps://t.co/j3OEETIdop
— mi141 (@mi141) November 4, 2022
実は私のいる部署のメンバーが、チュートリアルで「画像生成モデルの最新動向」という内容で発表します。どうやってこの分野の研究を始めるか?に寄り添った、まさに初学者向けの内容で、特に学生さんの参加費は無料なので是非! pic.twitter.com/JpngmibYsW
Huggingfaceで拡散モデルに関する新しいコースが開始
Generative ML の基本と、画像や音声などを作成できるモデルのトレーニング方法が学べるとのこと。登録してみました🤗
We've joined forces with @johnowhitaker to launch a new course on Diffusion Models 🧨!
— Lewis Tunstall (@_lewtun) November 3, 2022
Come learn the nuts and bolts of generative ML and how to train models that can create images, audio, and more 🔥
Register here 👉: https://t.co/w0UXB1QyYJ pic.twitter.com/r3ZkjAUT6E
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます