
生成AIが創れる世界

画像生成AI アドベントカレンダー 21日担当です😆
https://adventar.org/calendars/7766
いろんな生成AIを活用した事例を見たり、いろんな人の考えを分類してみた所基本的にこの3つの方向性で生成AIは世界を幸せにできるんじゃないかと今思っているのでここに記録します。
ただまだ分類と予測をしただけで技術的な裏付けは明確にしておらず、技術的な理解がヘボヘボなので夢物語になっており、まだ80%SF小説です。ちゃんと裏付け全部書いた状態でもう1度出そうと思っています。計算資源、データの問題や技術的な問題までちゃんと把握しておきたいです。
生成AIが世界を幸せにする方向性
1. 圧倒的コストカット
Text to Everything (Generative Text/image/Audio/Video/Code/3D/..) / NLI
膨大な探索 / コストカット
超高速化 / コンテンツの高度化
UGC→AIGC
マルチバース, 縦軸と横軸の突破, 点から領域へ
(1の影響で生まれる世界)
2. ハイパーパーソナライズ
静的→動的 / 検索→生成 / Search→Answer
Intelligent internet / Generative Search Engine
インターネットのトポロジー変更
高度なローカリゼーション / 点から場へ
Liquid User Interface
3. 仮想人間(キャラクター)
チャットボット / AIアバター
4. 創発的動機に沿った自動生成 (追記)
5. 未分類
情報圧縮技術
圧倒的コストカット、それによるコンテンツの高度化
1つは単純に圧倒的に何か作ろうとなった時のコストがほぼない世界。コストカットというところはMidjourney, Stable Diffusion, ChatGPTを見た方だと想像できるはずです。若干思考が必要で、自動化しにくかった作業というのをすっ飛ばすことができ、スピード、多様性、価格面で大きな変革が起こせる。産業革命で起きた肉体の機械化のようなことが脳で少しずつ起き始めて衝撃的な形になってきている。
Text-to-Everything
究極にコストカットされた世界とはどういうものかというと、全部テキストで出来てしまう、魔法の世界。Text-to-Everythingの世界だと思ってます。
RunwayのCEOのCristobalさんは次のように言われてます。
次の10年間で最も重要なユーザーインターフェイス
The most important user interface of the next decade pic.twitter.com/YUs9V4g7Q1
— Cristóbal Valenzuela (@c_valenzuelab) September 7, 2022
これまで勉強してスキルを積み重ねてようやく作りたいものが作れるという世界からようやく人間が抜け出せる時が来たと感じています。
例えばAdeptが作っているAction Transformer(ACT-1)は現存するあらゆるソフトウェアツール、API、ウェブアプリを使えるように訓練された行動の基盤モデル。まだ公開されていませんが、サンプル動画がいくつかアップされています。
例えば以下の例だと、「ヒューストンで四人家族向けの家を見つけてください。私の予算は600kです」と入力するとなんということでしょう..マウスが勝手に操作されてUIを操作し、欲しかった情報に辿り着いています。もしこれがあらゆるAdobeのクリエイティブツールでハイレベルに出来てくると想像すると..もうパソコンに制作会社さんが全員入っているみたいなそういう世界観になる。(しばらくはずっと支援ツール、アシスタントのような存在だと思います)
1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️ pic.twitter.com/mq7c0Vyd7N
— Adept (@AdeptAILabs) September 14, 2022
CLI(コマンドラインインターフェース)から、GUI(グラフィックユーザーインターフェース)になり、ついにNLI(Natural Language Interface / 自然言語のインターフェース)になる時代の到来です。(既に他の定義があったら知りたいのでご連絡いただけますと幸いです。)
また、NVIDIAが発表したMinecraftをプレイすることができるAIエージェント「MineDojo」(プロンプトを指定したら行動させることができる)がありますが、これはMinecraftに関する730,000本ものYouTube動画やMiecraft wikiからスクレイピングされた7,000のサイト、Minecraftに関する340,000のReddit投稿、660,000のコメントを学習して実現しています。
Adobe系ツールのチュートリアル動画やWikiは膨大にインターネットに存在しているので、Adobeのクリエイティブツールでも、他あらゆるソフトウェアでも同じことはできそうなので本当にワクワクする。
MineDojoやACT-1を見ていると、デバイスにおける知的な雑務というのはなくなり、全員なより高度な作業に集中できる世界がもうすぐやってきそうです。(データにない行動についてどうしていくかという研究についてちゃんと知っていきたい。)
なので、スキルを貯めてできていたデバイスにおける知的な作業はAIがもうすぐある程度はできてしまうという認識でいます。
徐々に実現するText-to-Everything
初めて見た方向けにちょっと説明。
例えばこれはDALL-E2で個人的に出力したもの。この3Dアイコンを生成するためのプロンプトの一部の単語をカレンダーや象に変えるだけでこの素材が作れてしまう。従来だったらBlenderで1個1個作るか、デザインの素材ストアで買ったりしないといけなかったものがこれで出来てしまう。従来だったら買って終了で40パターンの範囲しか使えなかったりしていたのが、言葉さえ変えれば膨大にほしいものが手に入ってしまう。これは圧倒的なコストカットになります。


また、Runwayは映像編集の作業をすっ飛ばす未来を目指してます。従来だったらAdobeのサブスクリプション入ってAfterEffects入れて、YouTubeのチュートリアル見たり、Udemyなどの講座を受けて学んで、エフェクト設定してパラメーターをコロコロいじって..っていう時間がかかっていた世界を、彼らはすっ飛ばそうとしてます。(Runway大好き)
Introducing AI Magic Tools
— Runway (@runwayml) October 12, 2022
Dozens of creative tools to edit and generate content like never before. New tools added every week.
Available now: https://t.co/ekldoIsP34 pic.twitter.com/ejcSnEiCEi
Make any idea real. Just write it.
— Runway (@runwayml) September 9, 2022
Text to video, coming soon to Runway.
Sign up for early access: https://t.co/ekldoIshdw pic.twitter.com/DCwXcmRcuK
またtomeは、スライドを作る作業をすっ飛ばそうとしています。そういえばいちいち複製してタイトル各章につけて内容をざっくり書く..というのも退屈でした。一番いい状態は思ってることが一瞬で伝わることであって、できるだけ一瞬で終われた方がいい。tomeはそんな素晴らしい未来に向かってます。MicrosoftはOpenAIと提携しているのでPowerPointでやってきそう
(これは今日(12/21)リリースされたのでぜひ)
It’s much easier to edit and refine than it is to create something from scratch.
— Henri Liriani (@hliriani) December 13, 2022
Excited to share a sneak peek of what we're building. You'll be able to try an early version this in a matter of days. 👀 pic.twitter.com/77HEFs5jXT
また、Qatalog 2.0はSaaSツールをテキストで生成しています。自分の事業を説明すれば、AIが、人材、仕事、知識等すべてを管理できるオーダーメイドのプラットフォームを数秒で設計・構築できてしまう。企業がわざわざ独自のツールを導入しなくてもテキスト入力すればできてしまう世界がもうやってきてます。
Welcome to a new era of work. Today, we released Qatalog 2.0 in Beta - the world’s first system that designs and constructs bespoke software for any business, in seconds. A 🧵.. 1/ pic.twitter.com/O2P0f4RqKL
— Tariq Rauf (@tariqrauf) December 6, 2022
研究ベースでは続々と新しいものが公開され続けてます。
おぉぉ...また
— やまかず (@Yamkaz) October 5, 2022
テキストからHD動画(1280x768 24fps)を生成する「Imagen Video」をGoogle Researchが発表。
懸念が軽減されるまでモデルやソースコードは公開しないとのこと。 #ImagenVideohttps://t.co/9KlRCxkW7i pic.twitter.com/3u35EOAF5W
テキストから音楽生成きた!
— やまかず (@Yamkaz) October 20, 2022
Stable Diffusionと同様、テキストを入力するだけでAIが音楽を生成してくれるColabノートブックが公開
(中身はmuburt(@mubertapp)のAPI)
やってみたけどこのプロンプトエンジニアリング難しいpic.twitter.com/i6ztYB8JOdhttps://t.co/pEBGhwk34W
え..このクオリティはやばい。
— やまかず (@Yamkaz) September 29, 2022
テキストから動画を生成するAI「Make-A-Video」をMetaの機械学習エンジニアチームが発表。https://t.co/ZK7iuI5KVN pic.twitter.com/VLzKTCuAYg
実現への壁
ただ画像生成AI、コード生成AIで現在大きな問題が起きています。(今後3Dでも起きるけどまだあまり言及されてない)画像だけでいうと、クリエイターさんの間で問題視され、反発を受けている部分があります。
最近だとArtStationで起こった「No AI」の運動。学習の邪魔を狙うという意図があるなら、AIを破壊しに行っているという点でいうとラッダイト運動とかなり近い部分があります。
13日から始まったArtStationでのAI作品への大規模な抗議活動
— やまかず (@Yamkaz) December 16, 2022
現在「No to AI generated images」で検索して表示される投稿は3000件を突破してるhttps://t.co/4Z0SrfF0JU pic.twitter.com/LhlH5fT2vu
No AI運動の発端となったらしいツイート
Alexander - Inca
現在のAI「アート」は、何十億枚もの画像を作り、時間と愛と献身を費やした何十万人ものアーティストや写真家の作品を、魂の抜けたように盗み、倫理の概念など微塵もない利己主義者が利益のために利用することを背に作られています。
Current AI "art" is created on the backs of hundreds of thousands of artists and photographers who made billions of images and spend time, love and dedication to have their work soullessly stolen and used by selfish people for profit without the slightest concept of ethics.#ai pic.twitter.com/1q0zjePp0c
— Alexander - Inca (@Artofinca) December 5, 2022
最終的にNoAI抗議運動は、ArtStationがNo AIタグという新機能を搭載して一旦終わったと認識してます。
ArtStationがNoAIの抗議運動を受けてか新機能を追加https://t.co/j0fgYPwdTJ
— やまかず (@Yamkaz) December 17, 2022
・NoAIタグをつけることで作品には「NoAI」metaタグを追加
・利用規約を更新。NoAIタグの付いたコンテンツを使用してAIアートジェネレータを訓練することを禁止
・全ての作品にNoAIタグをつけれる設定を追加
また、DeviantArtは画像生成AI(名前はDreamup)をサイトに搭載し、サイト内の画像を今後学習していくよという方針にしており、サイトの内の画像を基本設定を学習許諾を全てonにしており大バッシングを受けました。その後、すぐに全ての画像の基本設定を学習禁止に変更。
Update: We heard the community feedback, and now ALL deviations are automatically labeled as NOT authorized for use in AI datasets. https://t.co/QnTPc3TA8a pic.twitter.com/pnQVgIsFkA
— DeviantArt (@DeviantArt) November 12, 2022
CLIP STUDIO PAINTもStable Diffusionを搭載後大バッシングを受け、搭載しないことを決定。
皆様からいただいたご意見を重く受け止め、CLIP STUDIO PAINTへ画像生成AI機能を搭載しないことといたしました。
— CLIP STUDIO PAINT(クリスタ) (@clip_celsys) December 2, 2022
皆様に新しい創作の体験をしていただきたい、という想いで開発を行いましたが、体験してもらう以前に、必要な配慮が欠けていました。https://t.co/7GEUORby4O pic.twitter.com/yTD5JIAs8R
また、一番代表的なのだとGithub Copilotの集団訴訟があります。
Microsoft、OpenAI、Githubが訴えられており、元となったコードを匿名化して、あたかもCopilotによって作成されたかのようにしてユーザーに配布しているということで訴えられており、ここの判決が今後生成AIの動向を決めるのではと言われていたりします。
これは生成AI業界の今後が決まる大ニュース
— やまかず (@Yamkaz) November 10, 2022
マイクロソフト、GitHub、OpenAIの3社が、AIでオープンソース コードを複製することで著作権法に違反したとして集団訴訟されてる。これはその弁護士に話を聞いた記録https://t.co/MEjSnFlb1O
ただ個人的には、4つほど弁護士さんのAIに関する講義を聞いた結果、現行の法律の状態でいける気がしています。僕個人としてはプラットフォーム側のAI作品の棲み分け対応だけでいい理解をしてます。
細かい場合分けが沢山ありますが、基本依拠性と類似性があればアウトという判断で問題ないと考えておりかなりスッキリしています。人間と同様の扱いでいいんじゃないかという判断で、ただ制作スピードが上がっただけであり、使う側のモラルが問われるという世界になると僕は思ってます。結局その人の作品を意図的にかなり真似して、投稿して遊んでいたら、それは普通のクリエイターさんと同様の視点で見られると思いますし..。
(これあの人の真似ですよね..?みたいな連絡が来るはず)
でも実際この状況を課題に思い、活動されている何人かの方を日本でも海外でも見ていたり、ここに関して長期的な視点を持てていないので、僕の視点にはまだまだ何か足りないものがあると感じてます。
サンドイッチワークフロー
まだ創発的な衝動や高度な人間的な感覚を持たないAIは、まだ協業スタイルであり、Noah Smithさんが以前書かれていたブログが綺麗に言語化されていて素晴らしかったので引用ですが、しばらくサンドイッチワークフローというのになるんじゃないかという話があります。
(この創発的衝動や人間的な価値観という部分がどのくらい解決されうるのかという部分は全然まだ理解できてないのでここを今後は深ぼっていきたい。)
彼らはその時代の新しいワークフローを「サンドイッチ」と呼んでいる
— やまかず (@Yamkaz) December 4, 2022
"これは3段階のプロセスです。まず、人間には創造的な衝動があり、AIに刺激を与えます。その後、AI はオプションのメニューを生成します。次に、人間はオプションを選択して編集し、好みのタッチを追加します。 " 図解したよ✏️ pic.twitter.com/crYGPEdVfK
これまで、作りたいものがある→スキルを積み上げる→制作するというワークフローだったのが、作りたいものがある→AIに依頼する→AIから選ぶというワークフローに移動するという話です。
これにより、人間は本当にクリエイティブなものの手前にあった作業というのを大幅に削減できる可能性があり、それによりコンテンツのリッチ化が起きると考えています。もっと重要な課題に人間は移動することが可能になっていくということです。
マルチバースへのアクセス, 縦軸と横軸の突破, 点から領域へ
また、圧倒的コストカットによりマルチバース、あらゆる可能性にアクセスが容易になりました。進化しすぎた未来には過去のコンテンツがアニメ版で全て復活する。そんな世界もあるかもしれないです。Stanford HAIの基盤モデル研究センターの所長 Percy Liang氏が「(動画生成AIについて)来年には、人間が作ったのか、コンピュータが作ったのか、区別がつかなくなるかもしれません。」と言われていたので、来年その片鱗が確認できるかもしれない。
Midjourneyで生成されたアニメ版ハリーポッター。過去の映画が全てアニメ版で見れる世界がくるかもしれないhttps://t.co/ZDdMMP72SI pic.twitter.com/7wiHbkcexP
— やまかず (@Yamkaz) December 21, 2022
Midjourneyで生成されたジブリ風ハリーポッターがめちゃめちゃ素敵。全ての映画がジブリ風で見れる世界が来たらいいなhttps://t.co/SVd8ANEXnQ pic.twitter.com/mEELR5uXDD
— やまかず (@Yamkaz) December 12, 2022
とか方向性としては、終わったアニメの続きも好き勝手見れたりするかもしれない。アニメの「日常」全部終わったけど続き生成してもっと先を見るみたいな。僕は縦軸と横軸が突破されると言ってるんですが、過去の人が生み出したコンテンツや未来の未知の背景が含まれた文章もつながっていけるし、離れすぎたコミュニティにいても繋がれると思っています。
また、これまで人間が作っていたが点は重要じゃなくなり、領域が重要になるんじゃないかと思ってます。そしてよりそれぞれ見ているものが異なり、点は重要じゃなく、領域が重要なんじゃないかと思っています。
「メタバースではなく、マルチバース」
Emad氏はサンフランシスコでStability AIのローンチパーティーで次のように話している。「メタバースのことは忘れて、マルチバースに投資してください。」
個人的に気になったEmad氏の発言(5/5)
— やまかず (@Yamkaz) October 19, 2022
"数年後には、想像できるものならなんでも作れる様になります。そしてそれは素晴らしいものになると思います。"
"グーテンベルク以来の大きな出来事です。"
"メタバースのことは忘れて、マルチバースに投資してください。"
コミュニケーションの高度化
また、別の話ですがAIアートインポスターはかなり秀逸でまさに圧倒的コストカットによって起こる変化の1つだと思っています。AIアートインポスターとは何かというと、人狼ゲームのAIアート版。お題が2つ与えられるけど、片方のお題だけは1人だけは与えられず、誰が与えられていない人かを見つけるというゲーム。
コストカット、スピードアップにより、対話と同じように画像が生成できるので、従来テキストだった部分は画像に置き換えられる。このイノベーションがないとできなかったコンテンツです。
ハイパーパーソナライゼーション
次の方向性です。
「検索から生成へ」「静的から動的へ」「SearchからAnswerへ」「intelligent Internet」「generative search engine」とかいう概念が出てきていますが、それをまとめるとハイパーパーソナライゼーションにまとまると思ってます。インターネットのトポロジーを変更し、分散的で個人ごとに区切られたとてもハッピーな世界を作れる可能性があるというもの。簡単にいうと、個人が最も求めていたものを全員が手に入れられる世界です。
自分だけのもので溢れる時代
例えばDavid Albert Friedbergさんは次のように語られてます。
誰もが自分だけの映画、音楽、本、ニュース記事、ビデオゲーム体験を楽しむことができます。多くの人が同じ音楽を聴き、同じ映画を見て、同じ本を読んでいるなんて、ある日ばかげたことに思えるかもしれません...
everyone will enjoy their own personalized movie, music, book, news article, video game experience. it may seem silly one day that many humans listened to the same piece of music, watched the same movie, read the same book...
— david friedberg (@friedberg) December 9, 2022
マスの時代、テレビの時代は大きな会社が作ったかなり絞られたコンテンツを僕らは見て楽しんでいました。そこにインターネットがやってきて世界中の人が作ったあらゆるコンテンツから選んで楽しむ時代がやって来た。そこではAIによるリコメンドシステムが素晴らしく働く。ここが現在でTikTokのアルゴリズム最高!の時代。ここからついに本当に好きなものがコスト0で手に入れられる時代がくるかもしれない、そこでは生成AIが活躍します。
Intelligent Internet
Emad氏がよくいう「Intelligent Internet」という概念があります。以下にEmad氏がそれについて言及した部分をいくつかまとめました。簡単にまとめると知識が圧縮された自分だけの分散的で動的な生成検索モデルのこと。従来のサーバー上に置かれた静的なインターネットではなく、圧縮し、自分が本当に求めているものを動的に変形し与えてくれる上、AIに学習させ、数GB〜100MBに知識を圧縮させることで中心となる誰かが管理する必要がなく、それぞれデバイス上に持っておける。そういう世界観だと個人的には理解してます。
インテリジェントインターネット
知識を圧縮する、すべての人のためのパーソナライズされた生成的検索モデル。
画像、音声、テキスト、その他。
分散型・動的な次世代プロトコル。
人間の潜在能力を活性化するための基盤はこうして作られる
Stability AI
The intelligent internet.
— Emad (@EMostaque) August 25, 2022
Personalised generative search models for everyone that compress knowledge.
Image, audio, text & more.
Distributed & dynamic - a protocol for the next generation.
This is how we build the foundation to activate human potential @StabilityAI
StableDiffusionのようなパーソナライズされたAIを搭載し、エッジに分散したインテリジェントインターネットが、本当のWeb3 / Metaverseです。
最初から価値を生み出せば、経済的なインセンティブは必要ない。
インテリジェントなインターネットの価値創造 >> バカなスマートコントラクト
Intelligent internet, distributed & powered by personalised AI like #StableDiffusion on the edge is the real Web3 / Metaverse.
— Emad (@EMostaque) August 28, 2022
Don’t need to bootstrap economic incentives when you create value from the get go.
Intelligent internet value creation >> dumb smart contracts
Emad氏のPodcast
私はインテリジェントインターネットのビジョンを持っています。そこでは、すべての人、企業文化、国が、モダリティを超えた独自のAIを持ち、互いに対話し、私たちの可能性を高めています。そして、私たちの情報を結びつけて、知識へと圧縮します。そして、私たちの文脈では、それが知恵になります。今、私たちにはそれがありません。私たちを見守る人がいないのです。その代わり、情報は一元化されています。Facebookなどのパイプを経由して流れてくるわけです。ですから、私が目指しているのは、誰でもこのようなモデルを自国の文化で構築できるようにすることです。これが将来の大きなビジョンです。
前述のように、誰もがインテリジェントインターネットの生成検索エンジンとして、さまざまなモダリティにまたがる独自の AI を持つことになります。
これから何が起こるかを少しだけ示してから、これらを組み合わせ始めると..
As noted everyone will have their own AIs across modalities as generative search engines in the Intelligent Internet.
— Emad (@EMostaque) September 11, 2022
Just a little show of what's to come and then when you start combining these.. https://t.co/AL2VAnbdA6
インターネットのトポロジーが変わる
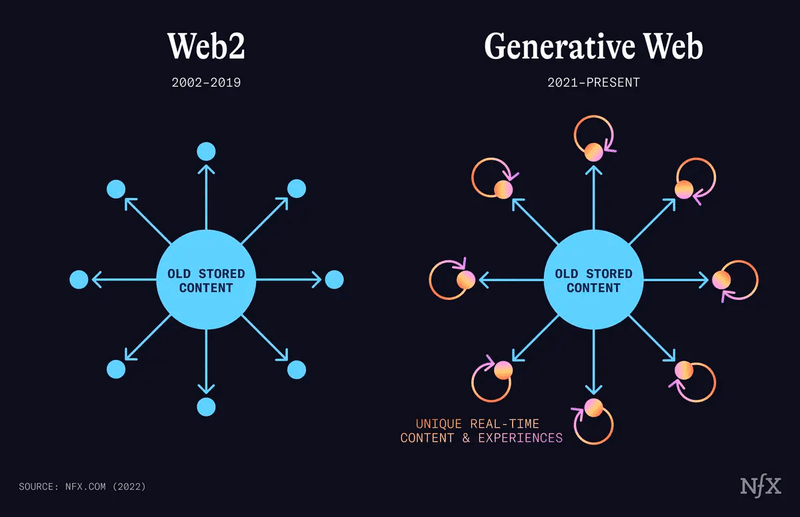
つまり、インターネットのトポロジーが変更されるという話です。NFXさんのブログで分かりやすい図と解説があったので引用させていただきます。いわゆる「検索から生成へ」「SearchからAnswerへ」という話と同じです。
Generative Webに移行することにより、本当に求めているものが手に入れられる世界を作れる。(その状態でも源泉となるWeb 2.0は今後もずっと必要なはず)
Web2.0
1.保存されている
2.古いコンテンツ
3.中央から、ネットワークの端にいるあなたに届けるために、データベースへの問い合わせを行う
Generative Web
1.ユニークなコンテンツ
2.ネットワークの端で生成される
3.あなたの行動によってリアルタイムで生成される
「2030年:すべてが「加速」する世界に備えよ」にも同じようなことが書かれています。賢いAIエージェントがいて自分が求めている適切な回答をしてくれるなら、僕らは広告を見るだろうか?広告という形式は本当に正しいのか?という話です。マーケティング:50 商品の良さ:50の時代から商品の良さ:100でいいという素晴らしい時代へ移動できるかもしれません。そしたら全員そこにのみ集中することができるはずです。
先ほどのコンセプトが形になっているわけではないですが、「Metaphor」は少しそれに少し近いコンセプトを作ろうとしています。彼らは言葉の後にどんなリンクが来るかというの予測するモデルを構築しており、従来の検索とは全く違う検索をすることができます。
https://t.co/NX99LxC7vL is now publicly available!
— Metaphor (@metaphorsystems) November 10, 2022
Metaphor is a search engine based on generative AI, the same sorts of techniques behind DALL-E 2 and GPT-3
1/
例えばこんなことができます。
今までの検索ではできなかったことができてる
— やまかず (@Yamkaz) November 11, 2022
例えば「これは19世紀のイーロン・マスクのような人物のWikipediaのページです。」と入力したら1番上にNikola Teslaが、「18世紀」にしたら永久機関を作ったとされてるJohann BesslerのWikiが表示されるpic.twitter.com/uPm8mwyYDWhttps://t.co/ArBtWkiWfZ
このあたりの話はここで深い解説されてます。
「次のGoogle検索エンジンはGenerative AIになる」
Liquid User Interface
静的から動的へと書いていましたが、それはこういうもの。目的に沿って形を変えるユーザーインターフェース。あらゆるツールがこれになるかもしれません。ここまでいくと従来のUI、CLI、GUI、NUIとは一線を画すので個人的にはあまりの自由度の高さから液体に例えて「Liquid User Interface」と呼んでます。既に名前あるのかな..あったら教えてください。
imagine if you could take the raw material of websites and shape it into new forms pic.twitter.com/bHTawf9YPZ
— Matthew Siu (@MatthewWSiu) September 21, 2022
(bioshokさんの記事から拝借)
いわゆるこれってアイアンマンの世界なんですよね。アイアンマンがエンドゲームあたりできていたスーツはナノテクノロジーで出来ていて目的に沿って武器にもなるし、盾にもなるし、吸盤にも、爆弾にもなる。
Siriに頼んだらそれ専用の本当に適切なUIをそれぞれ生成していくような世界もあるかもしれないです。フラットデザイン、マテリアルデザイン、スキューモーフィズム、ニューモフィズムなどいろんなデザイン文脈が来て、ついに未知のデザイン領域が誕生しそうでワクワクしています。
ChatGPTは文字ベースでまさにそんな感じを実現していて、あらゆる言語タスクが自然な対話でできている。場合によって形も能力も変えることができる。
執筆、検索、辞書、教育、翻訳、書籍、企画、要約、会話、さらに、ゲーム、プログラミング、ディベート、仮想環境構築など..、あらゆるものがChatGPTに集約されてるの衝撃的なんだけど、人間の脳がそんな感じなのか
— やまかず (@Yamkaz) December 6, 2022
「ジェネレーティブAI」という言葉はあまり好きではありません。
私は、インテリジェント・インターネット、インテリジェント・メディア、インテリジェント・エンターテインメントというコンセプトが好きです。
静的なコンテンツがすべて対話的になるのです
Tbh I am not a fan of the term "generative AI", feels limiting when it can also understand stuff..
— Emad (@EMostaque) October 28, 2022
I like the concept of the intelligent internet, intelligent media and intelligent entertainment.
All that static content becomes interactive 🚀✨
仮想人間(キャラクター)
最後の方向性です。
Charactor.ai、ChatGPT、最近話題になったD-IDなどを見ればわかりますが、仮想の人物を作ることが可能になります。本読むよりその人に聞くことができたり、サイトそのものや本、有名人がキャラクターみたいになるかもしれない、また、お医者さん、弁護士さんレベルのAIに聞いたりする世界もあるはず。そういう仮想人間を作る方向性。彼らはコストが安く、どの時間に連絡しても答えてくれる上、安定した品質で教えてくれます。
仮想人間の実装
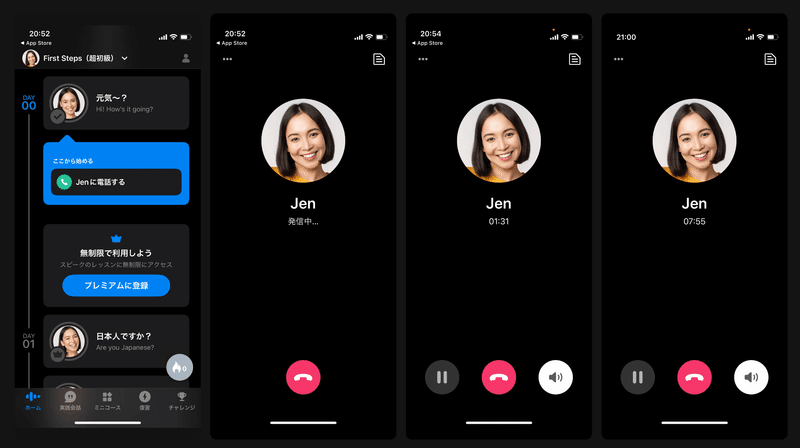
例えばSpeak。最近日本に上陸したサービスで韓国で1位の教育アプリ。現在は旧来の用意された構文を音声認識で話している感じですが、ある記事でGPT-3を搭載すると言われていたので僕は彼らは自然な対話をここで実現していくんだろうと考えています。つまり、仮想の英会話教師を作り上げることを目的にしてます。
例えばこれは僕が操作してみた画面ですが、英会話相手のJenさんとこうやって電話のようなインターフェースで会話ができます。
これが自然な対話になってくる..と考えてくるとかなり素晴らしい。
普通英会話学ぶのって結構お金かかるけどこれは月額1800円でできてしまう
また例えば他にもReplikaのような、AIフレンドを作れるサービスもあったり。

Charactor.AIというチャットボットを作っていろんなAIたちと話せるサービスもあったりします。
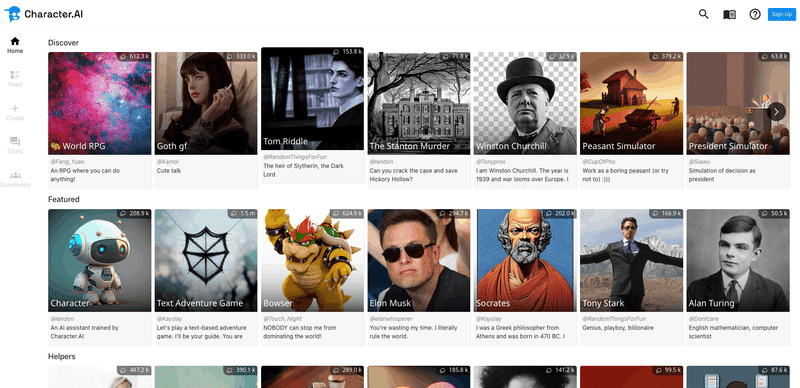
仮想人間の可能性、良さ
仮想人間が生み出す可能性は何かと考えてみる。通常の人間とは何が違うのかで言うと、コスト、自由度、知識量、自動化(働く時間が左右されない)、質の担保などがあります。
また死んでしまったあの人の過去の会話ログや画像、動画を全て学習し、仮想的にまた会える、そんなものも作れるかもしれないです。
それでいうとデータが山ほどあるひろゆきさんとか完璧な状態が作れそう
書きました。@shi3zさんに感謝。
— Koya Matsuo (@mazzo) December 17, 2022
AIと呪文で、もう逢えない妻の新しい写真を捏造した(CloseBox) @TechnoEdgeJP https://t.co/80gxWavSd3
創発的動機による自動生成
(後で書く)
未分類
情報圧縮技術として
先日お誘いいただきこちらのイベントでお話ししていた際、注目の生成AIの使い方というお話になり、その際@minami_kikukawaさんが言われていたので思い出した9月に話題になっていたこの技術の新しい使い方。情報転送技術として将来的に有効ではないか?という話です。これは他の領域に分類できないですが、何か新しい世界が作れるかもしれません。
最後に
という風に個人的にはこんな整理をしてみました。これらの世界が実現できそうという可能性が見えてしまっているため、こちらにあらゆるものが向かっていくんじゃないかと予想してます。まずはインフラとしてあらゆるサービス、ゲーム、コンテンツに入っていくという変化が2023年は頻出しそう。
別の話ですが、Neuralinkの技術と生成AIが進化した先には本当に魔法使いみたいな存在ができそうな気がしていて、ワンチャンマジでホグワーツ誕生するかもしれないみたいな妄想をしています。
イーロン・マスク率いるブレインテック企業Neuralinkの発表が終わりました!
— Daichi Konno / 紺野 大地 (@_daichikonno) December 1, 2022
要点は以下。
・サルが念じるだけでキーボードを操作し、人間の言葉を入力
・電極の自動埋め込みロボットの実演
・小型化により、1回の手術で16,000電極を埋込可能に
・ヒト臨床試験を半年以内に開始予定(!) pic.twitter.com/icwwt9VKWl
この記事はまだSF小説状態なので、技術的な理解が深まったら段階的に更新していこうと思います。ありがとうございました
Twitterに、毎日製作したものや、最新情報、検証を載せたりしていたりしてます。よかったら見ていただけたら嬉しいです。
もっと興味がある人用リンク集
text-to-imageの初心者向け動画
text-to-image modelのタイムライン
レイカーツワイル: 特異点、超知性、不死
OpenAI CEO Sam Altman | AI for the Next Era
bioshokさんの未来予測
【落合陽一のシンギュラリティ論】シンギュラリティは2025年に来る/ディフュージョンモデルの衝撃/知的ホワイトカラーが没落する/最新版デジタルネイチャー/音楽と論文が数秒でできる
2022年10大AIニュースと2023年の展望
Aranさん、AKさんがツイートしたtop 50ペーパーまとめ
Looking back at AI in 2022 -- top 50 papers tweeted by @_akhaliq and @arankomatsuzaki https://t.co/6s7mmf5304
— Daniel Gross (@danielgross) December 20, 2022
AI、自動化、雇用に関する歴史からの5つの教訓
機械が人間に取って代わる可能性のある分野と、(まだ)そうでない分野
ムーアの法則を新たな高みへ導く3次元積層型CMOS

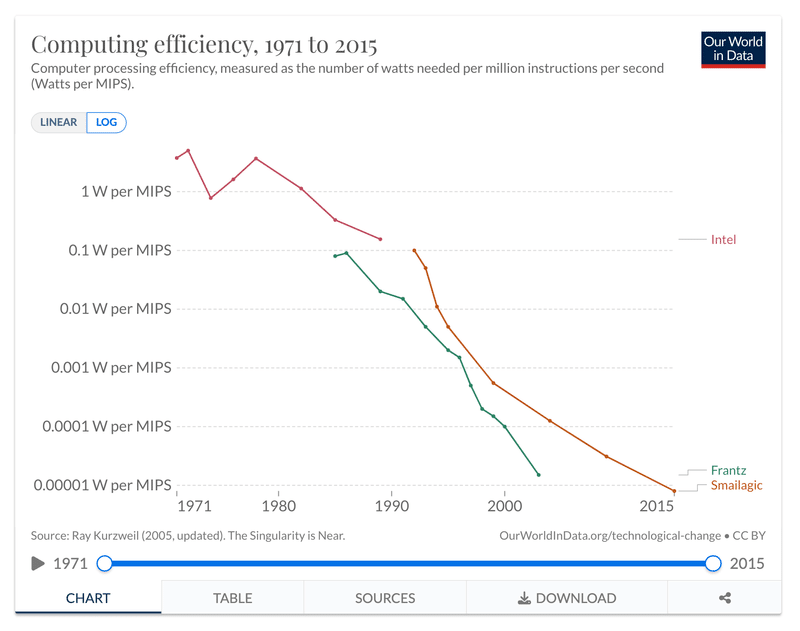
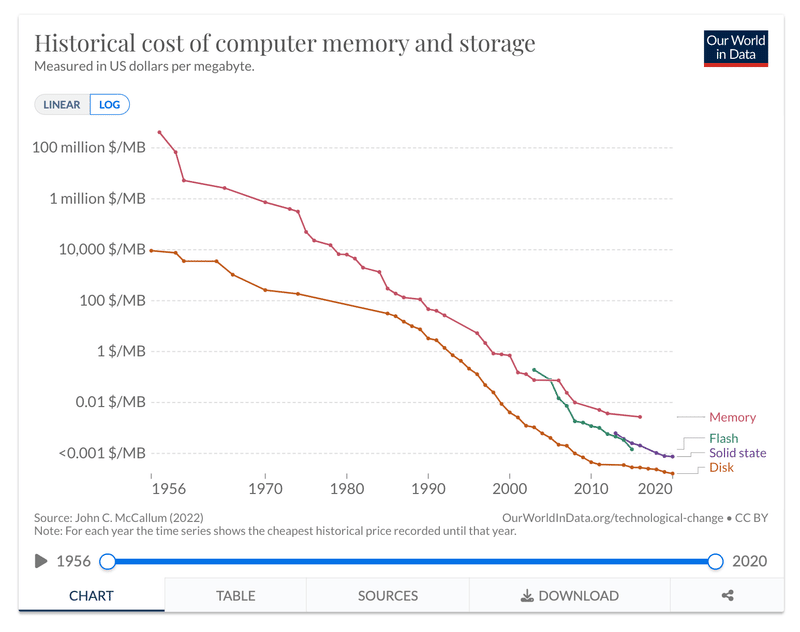
これからの数十年は荒れ狂うかもしれない
ムーアの法則、AI、そして進歩のスピード
あらゆるものにムーアの法則を
AIの近未来はアクションドリブンである
ものが考える時代
State of AI Report 2022
更新履歴
2022.12.26 「縦軸と横軸の突破, 点から領域へ, 点から場へ」追記
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます