
Feature Importanceって結局何なの?

この記事の目的
GBDT(Gradient Boosting Decesion Tree)のような、決定木をアンサンブルする手法において、特徴量の重要性を定量化し、特徴量選択などに用いられる”Feature Importance”という値があります。
本記事では、この値が実際にはどういう計算で出力されているのかについて、コードと手計算を通じて納得することを目指します。
なお、この記事は3回シリーズの第2回で、最終的にcatboostのfeature importanceの算出方法を理解するのが目的です。ここでは、用意されているfeature importanceの計算方法がわかりやすいxgboostを使います
第1回: Catboostの推論の仕組みを理解する
第2回: Feature Importanceの計算を理解する (イマココ)
第3回: CatboostのFeature Importanceを理解する
Feature Importanceって何?
Feature Importanceという単語自体を聞いたことがない、という方は前回の記事の冒頭にまとめましたのでどうぞ!
この記事を読まれる方の多くは、scikit-learnやxgboostのようなライブラリを使って、Feature Importanceを算出してとりあえず「特徴量の重要度」を確認してみる、ということをしたことがあるのではないでしょうか。一方で、feature importance自体が実際何を表しているのか、というのはあまり意識したことがないのではないでしょうか?(わたしはそうでした)
モデルだけからFeature Importanceを算出する
まず、自分が開発者だったら「特徴量の重要度」を計算するのにどうするかを考えてみましょう。一番簡単なのは、「モデルの中でその特徴量が何回使われているか」ではないでしょうか?
実は、これがxgboostで、2018年末までデフォルトの手法として使われていた、feature_impotranceの計算方法です。ここのコードで、モデルをテキストとしてパースして、木の中に出現する特徴量の数を数えています
実際に見てみましょう。xgboostで学習したnum_rounds=2のモデル(木が2つ)を用意します。木を可視化すると、以下です。f52だけが2つの木で使われており、それ以外の特徴量は、モデル全体で1回しか使われません。

では、このモデルをxgboost組み込みのfeature importanceを可視化する関数で見てみましょう。現在ではデフォルトの計算方法ではないので、importance_type="weight"というオプションで指定します。たしかに、”F score”がf52だけ2.0で、それ以外に使われている特徴量は1.0ですね。

さて、これが本当に「特徴量の重要度」なのかといわれると、まぁそうかもしれないし、そうでないかもしれないな、という感じになりませんか?
学習データも使ってみる
ちょっと考えると、すぐに拡張ができそうです。例えば、これらはすべての分岐を対等に扱っていますが、木の根元で使われている特徴量と末端で使われている特徴量は全然重みが違いますよね?根本であれば、いろんなデータがそこを通りますが、末端では一部のデータしかその分岐を通らないわけです。モデルのみからでも、適当な仮定をおけば計算できそうですが、学習データとあわせれば、各分岐を通過する確率が実際に計算できます。
実は、これもxgboostには実装されていて、上記の常態でimportance_type=”cover”を指定すると以下のようになります。

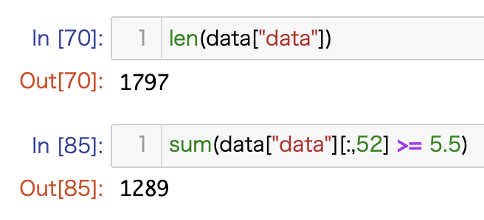
今度は大きめのF scoreがでてきました。木の根元にあるf52のf scoreの1797という値はなんでしょうか。ここではsklearnのdigits datasetを使っているのですが、1797はデータ数に一致します。さらに、0番目の木f52 > 5.5の場合の分岐でだけ登場するf36のf scoreの1289も、この分岐に到達するデータ数に一致しています。
なお、このように学習データを参照しないと正しい値が出せないため、実際の算出プロセスでは、モデルの内部にcoverの値は残しておいているようです。
ここで気づくのは、各treeのどの割合で使われているか、という情報はcoverでは使われていないようですね。例えば、f52は2つの木で両方根本で使われているので3594=1797+1797を値としてもよさそうですが、そうはなっていないようです。
"gain"からFeature Importanceを算出する
さて、分岐を通った回数だけを考慮する今までの方法はさすがにad-hocだなと思われたのではないかと思います。それぞれの分岐の重要度はそもそも違いそうですし、xgboostの学習プロセスと一切関係ない計算方法なのも気になります。
xgboostではもう一つの計算方法が実装されています。それがimportance_type=”gain”というオプションです。
xgboostは、木をroundごとに追加していく(なので、num_roundsパラメータと木の数は一緒になります)方法で学習します。木を追加する際に、max_depthになるまで、各層でどの分岐を増やすかの検討を行います。このとき、分岐を追加したときの目的関数の改善幅を評価しており、その評価値が”gain”と呼ばれます。gainの計算方法は結構複雑なのですが、解説は本家のtutorialがわかりやすいです。
このgainの値を参照して、最善の分岐を追加しているわけです。gainを各分岐に記録しておき、feature importanceの計算時には、和をとります。
(gain自体の計算がその層が追加される前の状態に依存しているので複雑であり、学習時の状況をきちんと残しておかないと再現ができないため、今回の記事では求めません)
結局どの方法がいいの?
さて、上記のxgboostの学習の方法を考えると、gainそのものが「ある特徴量がある分岐において目的関数の改善に寄与した度合い」と解釈できるため、その総和は、「ある特徴量があるモデル全体において目的関数の改善に寄与した度合い」として最も自然な計算方法に見えます。実際、ブログなどでも推薦されている場合が多いです。最新のxgboostであればデフォルトでgainが採用されるため、実用面ではそのまま使ってよいでしょう。
2018年末までのxgboostは、デフォルトがweightだったので、昔の情報やソースを使うときは注意です。
具体的な計算方法を確認すると、計算方法によって調べている値が大きくことなり、同じ"Feature Importance"といっても一緒に考えることはできなそうなことがわかります。データ数や中身に依存して大きく値も変わり得るわけなので、その実験中の他の特徴量との相対比較でしか比較できないわけですね。
今回使ったnotebookは以下においておきました
では、catboostではどうか
この記事ではxgboostのfeature importanceについて話しました。catboostも基本的には同じ、と言いたいところなのですが、ここでやっと前回の記事の話が関連していきます。前回の記事でソースコードを辿ったとおり、catboostの木は完全二分木で、同じ深さにおいては分岐は同じ特徴量を使って行われるのでした。要は、木の形式をとりながら、本質的にはデータを深さ次元のブール型ベクトルに変換しているのす。
すると、すべての分岐をすべてのサンプルが通過するわけですから、coverの方法は使えません。さらに、各層ごとに分岐を追加するという方法で学習が行われていないために、gain likeな方法も同様には使えません。
じゃあどう計算しているの?ということについては次回の記事で追っていきます!
---
MNTSQ株式会社では機械学習/自然言語処理エンジニアを募集しています!
この記事が気に入ったらサポートをしてみませんか?