
catboostの推論の仕組みを理解する (1/2)

この記事の目的
catboostというライブラリがあります。GBDT(Gradient Boosting Decesion Tree )という決定木をアンサンブルする方式の識別モデルを学習するものです。同様のライブラリは他にはXGBoostやLightGBMなどが有名です。
GBDTって何やっているの?というのは以下のXGBoostのドキュメントの画像がわかりやすいです。要は、複数の決定木が存在していて、その結果をあわせて結果を決定(アンサンブル)しているわけです。学習に応じて徐々に木を追加していくのですが、どうやって新しい木を追加していくかのやり方に、「Gradient Boosting」という手法を使っている、というイメージです。catboostは、カテゴリカル変数の扱いに新しい手法を導入していて、論文にもなっています。catboostの"cat"はcatgoryの"cat"なのですね(が、残念ながら今回はまず、category変数を使わない話をします)
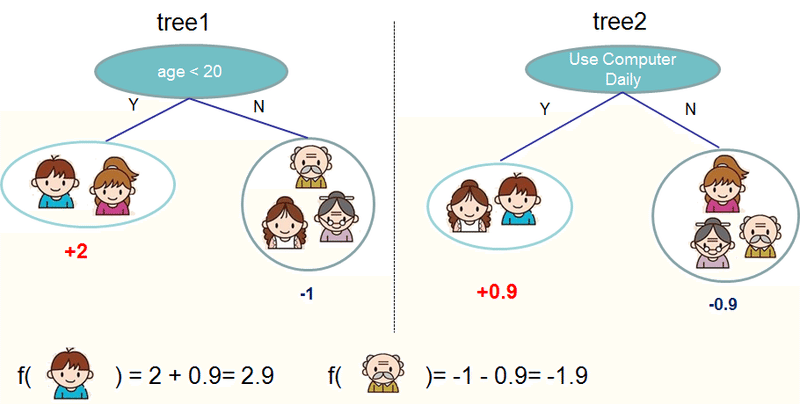
GBDT(や決定木をアンサンブルする手法)は様々な使いやすい性質があるため、幅広い応用に使われているのですが、その中の一つに、feature importanceが算出できるという性質があります。scikit-learnのドキュメントのこの図のように「どの特徴量がどれくらい重要か」を実数で表すことができます。Kaggleなどでは特徴量選択のために使われたりしていますね!
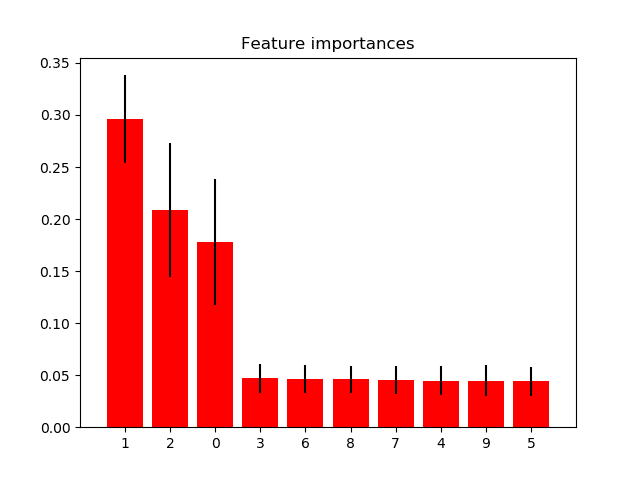
一方で、feature importance自体を手で算出したことがある人はあまりいないと思いますし、なんとなく「どの特徴量がどれくらい重要なのかをあらわすもの」という理解ではないでしょうか。
今回と次回の記事を通して、小さなモデルに対してFeature Importanceを実際に計算してみることを目指します。
この記事ではまずその準備として、catboostのモデルをdumpして、catboostの学習済みモデルのパラメータからどう推論が行われるのかを理解したいと思います。わたしも実際に見るまで気づかなかったのですが、catboostはxgboostと異なり、どの特徴量を使うかは深さによって決まっていること、完全二分木を決定木として使っていることがわかります。
catboostのおもしろ機能を使ってモデルをdumpする
catboostのモデルの内部パラメータはもちろんアクセスができるのですが、すべての決定木のパラメータがただのリストに並べられていたり、どういう構造なのかが自明でなかったりするので、パースをしていく必要がありそうです。
> classifier.get_leaf_values()
array([ 0.01709215, 0. , 0.01709215, -0.01709215, -0.01694618,
0.03147163, -0.01680166, 0.03097456, -0.01665859, 0.01641477,
0. , 0.01641477, -0.01651697, 0.03023076])
> classifier.get_borders()
{0: [1.5, 2.5], 1: [3.0, 5.5]}
> classifier.get_scale_and_bias()
(1.0, 0.0)どうやってparseするかですが、ソースコードを読めばよいのでしょうが、今回はcatboostのおもしろ機能を使います。catboostは
pip install
でスッと入るのがすごくGoodなのですが、さらになんと、学習したモデルを
classifier.save_model('model.py', format="python", export_parameters=None)
というメソッドで保存できるのです。このファイルは外部ライブラリに依存せずstandaloneで実行できるので、catboostをpipできない環境でも動かせるというわけですね。つまり、このファイルを読めば、パラメータに対して、どのように実際の出力値が決まっていくのかのロジックを理解できそうです。
featureが3つの3サンプルの2クラス分類モデルを学習し、

木が5つ(n_estimators=5)、木の深さが最大で3(max_depth=2)のモデルを保存しました(random_state=0)。catboostのversionは0.22です。
できたファイルはこうです。
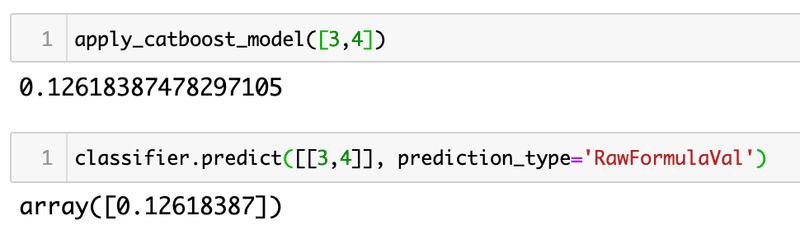
試してみると、出力にRawFormulaValを指定することで、通常のcatboostモデルでもたしかに同じ値が出ることがわかります。
解読してみる
冒頭のcatboost_modelでモデルのパラメータが保存されていています。こんなかんじですね。さきほど、モデルに対してパラメータを見ていったやつがちゃんと保存されてますね
float_features_index = [
0, 1,
]
float_feature_count = 2
cat_feature_count = 0
binary_feature_count = 2
tree_count = 5
float_feature_borders = [
[1.5, 2.5],
[3, 5.5]
]
tree_depth = [2, 1, 1, 2, 1]
tree_split_border = [2, 1, 1, 1, 1, 2, 1]
tree_split_feature_index = [1, 1, 0, 0, 0, 0, 0]
tree_split_xor_mask = [0, 0, 0, 0, 0, 0, 0]
cat_features_index = []
one_hot_cat_feature_index = []
one_hot_hash_values = [
]
ctr_feature_borders = [
]
## Aggregated array of leaf values for trees. Each tree is represented by a separate line:
leaf_values = [
0.01709215342998505, 0, 0.01709215342998505, -0.01709215342998505,
-0.01694618133243163, 0.03147163116319901,
-0.01680166157696535, 0.03097456038600766,
-0.01665859215423785, 0.01641476568743598, 0, 0.01641476568743598,
-0.01651697028909163, 0.03023076411634335
]
scale = 1
bias = 0catboostの本当においしいところはcatgeorical変数にあるのですが、今回はcategorical featureを使ってないので、関連のパラメータは空です。
catboost_modelを読み込んで、実際に処理を行うのは、apply_catboost_model関数です。
apply_catboost_model(float_features, cat_features=[], ntree_start=0, ntree_end=catboost_model.tree_count)この関数では、通常のcatboostモデルとは異なり、float featuresとcategorical featuresをそれぞれ別に渡すことを求められます。また、1回に渡すサンプル数は1つとなります。つまり両変数とも配列をわたす想定です。
この関数を見ていくことで、どのパラメータがどういう使われ方をしているのかを確認していきましょう。
binary_features = [0] * model.binary_feature_count
binary_feature_index = 0
for i in range(len(model.float_feature_borders)):
for border in model.float_feature_borders[i]:
binary_features[binary_feature_index] += 1 if (float_features[model.float_features_index[i]] > border) else 0
binary_feature_index += 1
ここでは、まず連続値の変数float_featuresをbinary_featuresなるものに変換しています。決定木は先程の図のように、連続値に関してこの値以上か、以下かで分割しているので、その閾値をすべて保存しておき、ここで一気に変換をしているということですね。今回のモデルでは、binary_feature_count=2となっているのでx1 ,x2に対応してbinary_featuresは2要素になっているようですね。
2重ループでは、外側がfloat_featureそれぞれについて、内側ループがそれぞれの閾値についてのループになっています。内側ループをみていくと、bordersは1番目の特徴量に関して[1.5, 2.5]の2つの閾値が記録されているので、それぞれの閾値について、閾値を超えていたら1を足していきます。
今回は具体的なデータとして、x1=3, x2=4を入力したとしましょう。
この場合、x1=3を入力すると、[1.5, 2.5]を両方超えるので、binary_features[0]=2となります。2つ目の特徴量x2に関しても、閾値を[3, 5.5]を用いてbinary_feature[1]=1となりました。
さて、binary_featuresを計算し終わると、今回はcategorical featureを使っていないので、そのまま以下のコードの最終結果の計算に行きます。tree_idのループは、各決定木についてのループです。ここで実際に各treeの出力を計算していくわけです。
result = 0.
tree_splits_index = 0
current_tree_leaf_values_index = 0
for tree_id in range(ntree_start, ntree_end):
current_tree_depth = model.tree_depth[tree_id]
index = 0
for depth in range(current_tree_depth):
border_val = model.tree_split_border[tree_splits_index + depth]
feature_index = model.tree_split_feature_index[tree_splits_index + depth]
xor_mask = model.tree_split_xor_mask[tree_splits_index + depth]
index |= ((binary_features[feature_index] ^ xor_mask) >= border_val) << depth result += model.leaf_values[current_tree_leaf_values_index + index]
tree_splits_index += current_tree_depth
current_tree_leaf_values_index += (1 << current_tree_depth)
result += model.leaf_values[current_tree_leaf_values_index + index]
tree_splits_index += current_tree_depth
current_tree_leaf_values_index += (1 << current_tree_depth)
ループの中身を見ていきましょう。
current_tree_depth = model.tree_depth[tree_id]
index = 0
for depth in range(current_tree_depth):
border_val = model.tree_split_border[tree_splits_index + depth]
feature_index = model.tree_split_feature_index[tree_splits_index + depth]
xor_mask = model.tree_split_xor_mask[tree_splits_index + depth]
index |= ((binary_features[feature_index] ^ xor_mask) >= border_val) << depth
まず、見ている決定木について、各深度のごとにループを回しています。
tree_depthを見ると、今回の木は5つ中3つは深さ1ですが、2つは深さ2となっています。GBDTでは、必ずしも木の深さは一定ではないので、「i番目のtreeのj番目の深さの分岐を判定する」ためには、1~i-1番目までの木の深さを考慮してパラメータのオフセットを計算する必要があります。各深度のループ内では、depthを加えたtree_splits_index + depthをオフセットとしていますね。tree_splits_indexは、各木のはじめの分岐のパラメータのオフセットを保存する変数になっているようです。たしかに、ループ終わりにいまのループの木の深さを足しています。
tree_splits_index += current_tree_depth
さて、border_valはtree_split_borderを参照しています。1番目の木を考えましょう。tree_splits_index=0なので、depth=0でborder_val=2, depth=1でborder_val1となります。木2の場合は、tree_splits_index=2なので、depth=0でborder_val=1です。同様に、feature_index, xor_maskを計算すると、表のような感じですね。
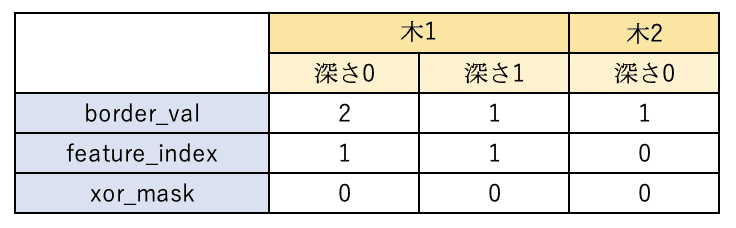
この値から、各木、各深度で"index"という値を更新しています。このindexという値は、最終的に、その決定木が最終的に出力するleaf_valuesの値のオフセットを決める値です。
result += model.leaf_values[current_tree_leaf_values_index + index]
冒頭のXGBoostの画像を思い出してほしいのですが、最終的な分岐の結果それぞれに値が付与されていました。それがleaf_valuesです。leaf_valuesは14要素のリストですが、以下のコメントのように、各行が1つの木になっているようです。tree_depthが2である、1番目と4番目の木が4つの値を持ち、残りの木は2つの値を持っているようですね。2^{深さ}のleafがあるということで、catboostの決定木は各木が完全二分木になっていそうです。
## Aggregated array of leaf values for trees. Each tree is represented by a separate line:
leaf_values = [
0.01709215342998505, 0, 0.01709215342998505, -0.01709215342998505,
-0.01694618133243163, 0.03147163116319901,
-0.01680166157696535, 0.03097456038600766,
-0.01665859215423785, 0.01641476568743598, 0, 0.01641476568743598,
-0.01651697028909163, 0.03023076411634335
]
さて、indexの値の具体的な計算を見に行きましょう。各depthで以下の式でindexを更新していきます
index |= ((binary_features[feature_index] ^ xor_mask) >= border_val) << depth
いろいろな演算子がでてくるので、順に見ていきます。まず、
(binary_features[feature_index] ^ xor_mask) >= border_val
を見ると、binary_featuresのある値がborder_valより大きいかを判断しています。これが実際に各木の各分岐の計算の操作です。
binary_featuresは入力から作られた特徴ベクトルでした。具体的な値を入れて、挙動を確認しましょう。木1の深さ0にいるとしましょう(tree_id=0, current_tree_depth=0)。先程の表を参照すると、feature_index=1, border_val=2, xor_mask=0でしたから、binary_features[1] ^ 0 >= 2となります。binary_feature[1]には、x2を評価した値が入るのでした。先程の計算から今はbinary_feature[1]=1です。^はbit演算子のXORでしたから、1^0はは2進数の0x01と0x00のXORで、そのまま0x01となりますね。つまり1のままです。border_val=2でしたので、上記の式はFalseになります。では、x2=7であればどうでしょうか?binary_feature[1]=2となりますので、border_val=2に対して大なりイコールが成立し、上記の式はTrueになります。binary_feature[1]の値の計算は、x2が5.5より大きいときに変わるのでした。つまりこの分岐は、
x2 > 5.5という条件の分岐だったわけです!
まとめると、「feature_index番目の特徴量の、border_val番目の閾値より大きいか、それ以外か」で分岐を判断しているのですね。
さて、分岐の結果がわかったら、それを用いてindexを更新しにいきましょう。
まず、depthのビット数だけ、2進数で左辺の値をシフト送りします(2進数表記の末尾に0がつく)。左辺の値は上記の分岐判定の結果ですから、結局True/Falseです。Pythonでは暗黙の型キャストでintに変換され、1/0になります。Trueだった場合を考えましょう。1を1ビットシフト送りすると0x10、2ビットシフト送りすると0x100…という感じです。これは、普通の数でいうと、2^{depth}となりますね!
<< depthその結果を最後にindexに対してさらにシフト演算します。
index |=...この記法は index = index | ...と等価です。|もビット演算子で、各ビットのorをとる、という内容です。さて、いま木1のdepth=0にいるので、index=0なのでした。つまり、右辺の値は1^{0}=1そのままの0x1です。0x0 | 0x1 = 0x1ですから、新しいindex=1となりました。
分岐の結果がFalseだったらどうなるんでしょうか?False = 0x0で、index | 0x0 = indexなので、indexを変えません。
さて、ここで不思議なことがあります。次の深さのループに行くのに、indexの値が参照されていないのです。先程見たとおり、border_val, xor_mask, feature_indexはそれぞれ、tree_splits_index + depthをインデックスとして参照しているので、depthが増えると次の要素を見るようになります。つまり、各分岐についてどの特徴量を使うのかは、各木についてそれぞれ深さだけで決まっているのです!
xgboostの決定木をプロットすると、大抵はこんな感じで、2分木ではあるものの、完全(深さがどのleafでも等しい)でなかったり、
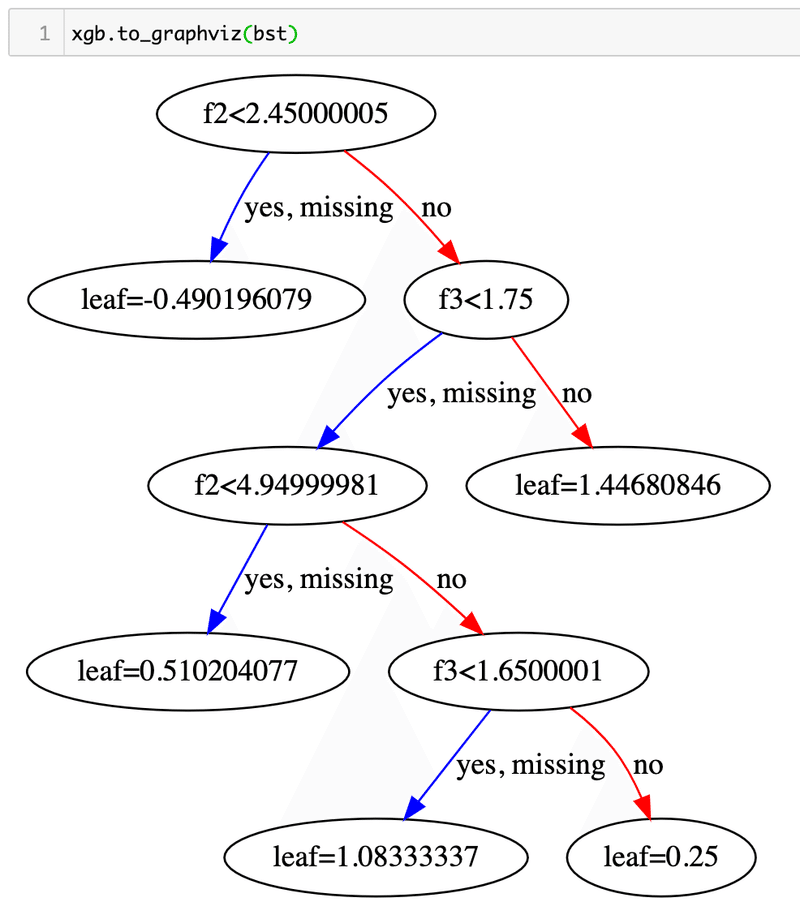
同じ深さでも、違う特徴量を使ったりしているわけです。
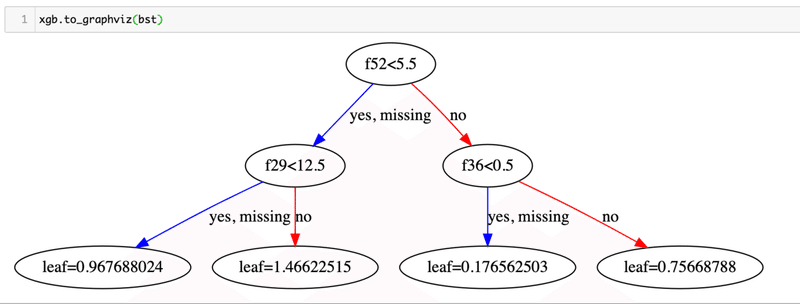
catboostの決定木はxgboostの決定木に比べて構造が大幅に制限されている、完全二分木かつ特徴量は深度で定まる木を用いていることがわかりました。
さて、indexの計算に戻りましょう。上記の性質を理解すると、indexの値の計算は腑に落ちます。
indexの値が各深さで更新されて、最終的にはcurrent_tree_leaf_values_indexにindexを足してleaf_valuesアクセスをしています。current_tree_leaf_values_indexが、ある木のleafの並びのはじまりだとすると、木が完全二分木であれば、indexの値が0から2^{current_tree_depth}の値の範囲をすべて取れば、その木のleafをすべて指定できそうです。それを確かめましょう。
model.leaf_values[current_tree_leaf_values_index + index]ある深さdepthにおいて、分岐でFalseになれば、index = indexで変化せず、Trueになれば、index = index | 2^{depth} なのでした(xor_maskは一旦忘れましょう)。
Trueであったときの演算をよく考えてみると、使われているのはビット演算のOR演算子なのですが、indexは前回のループで、深さが1つ小さい状態、つまり2^{depth-1}という、2進数で言えば1桁小さい値でORをしてきているわけなので、2^{depth} = 0x1000...000 (0がdepth個ある)の1の桁には絶対に1がないのです。つまり、この演算はORで書かれていながら、実は和なのです。したがって、先程の式はこうなります。
index = index + 2^{depth}では、これを各深さで繰り返していけばどうなるか?また2進数で考えると、結局indexの値は、深さdepthにおける分岐の結果がTrueであればdepth桁の値は1、Falseであればdepth桁の値は0となっているわけです。深さはcurrent_tree_depthなので、current_tree_depth個のTrue/Falseの組み合わせ2^current_tree_depthをすべて表せますね。先程の疑問が確かめられました。
逆に、この方法で計算しているので、「完全二分木かつ特徴量は深度で定まる」木であることは確定ですね。
あとは最後に、current_tree_leaf_values_indexが次の木に行く際にちゃんと2^{current_tree_depth}の増分があればよいのですが、1をcurrent_tree_depth分シフトしており、まさに、そのとおりのコードになっています!
current_tree_leaf_values_index += (1 << current_tree_depth)
ということで、各決定木に対してleafの値を求めるロジックがわかりました。木1のdepth=0でFalseになったあとから、leafの値まで実際に計算してみましょう。分岐がFalseのままなので、indexは0のままです。depth=1にいくと、またfeature_index=1ですから、x2をまた見ることになります。border_val=1なので、今度は
x2 > 3という分岐で、今度はTrueでした。さて、これからindexを計算すると、1桁目がFalseで0、2桁目がTrueで1なので、
index = 0x10 = 2
indexは2となりました。current_tree_leaf_values_index=0なので、そのままleaf_values[2] = 0.01709215342998505 がこの決定木の出力となります。実際には計算しませんが、木2, 3, 4, 5も同様な計算をしていけば、出力が求まります。
各木について順に resultにleafの値の和をとっていき、最後scale, bias変数を用いて線形変換し、最終出力を行います。別に平均をとったりするわけではないのですね。
ということで、catboostのモデルのパラメータから、どのように最終的に推論結果が出力されるまでのロジックがわかりました。catboostの実際の実装では、より高速に計算できるような工夫がされているはずですが、やっていることは全く同じはずです。
catboostが完全二分木だとか、単純に使っているだけでは全然気づかないので、面白いですね。木といえば普通はその前の分岐の回答に、次の分岐の内容が依存するような想定をしがちですが、catboostの場合は途中の回答内容に関わらず、固定された真偽判定を実施し、それで得られたベクトルそれぞれに最後に1つの値を与えているという感じです。
別の言い方をすると、catboostでは使う特徴量が分岐によって変わったりしないので、xgboostでは「x1>3以上であれば、x2>5なら1,5、x2<=5なら0,8, x1<=3なら x2の値に限らず0.2」のように、他の変数の値に応じて閾値が変わるということが起こりえるところ、catboostであれば、閾値自体は他の変数の影響を受けないわけですね。
ここに関しては、ドキュメントを見ているとQuantizationというステップが出てきて、各変数をいくつかの領域で分割するのですが、まさにこのステップで各次元を切っていった領域を木の形で表した、というのがcatboostの決定木なのかなぁと思います。このあたり、catboostの新規性のあるカテゴリカル変数の扱いの特徴なども絡んでくるようで、xgboostみたいなもんやろ、と思っていましたが、結構違うアルゴリズムを使っているんだなというのが体感で納得できました。(論文をちゃんと読みましょう、という話ですが)
パラメータのパースの方法が理解できたので、やっと次回はFeature Importanceの計算に取り組みます。
しかし、フォーマット的に完全にnoteに書くべき内容ではありませんでしたね…。
リーガルテックベンチャーのMNTSQでは、ライブラリの中身も見に行くような自然言語処理エンジニアを募集しています!
この記事が気に入ったらサポートをしてみませんか?