
LangChainを用いて大量ファイルをロードするVectorDBを作ってみた(12)

はじめに
大量ファイルを単純にVectorDBに登録して、そのデータベースに対して生成AIに質問をしても、精度の高い回答を得られないことが分かってきました。
前回と前々回では、各XMLファイルの中にある「タイトル情報」を基に生成AIによる自動タグ付けを実施し、それをVectorDB (Chroma)の属性として登録することをしてみました。これで、VectorDBに対する準備ができました。
今回はこのデータベースを基に、条件となる「タグ情報」を入力し、生成AIに質問をすることで、正しい回答が返ってくるかを試してみたいと思います。今回も`streamlit`でやってみたいと思います。
ソースコード
今回最初にコーディングしたソースコードを以下に示します。
このソースコードは前回の`chroma_retriever_tagging.py`と比較して、生成AIのAPIコールが非常に少ないため、モデルを`text-embedding-ada-002`にしています。(`chroma_retriever_tagging.py`では`text-embedding-3-small`を採用していました。)
import chainlit as cl
import streamlit as st
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import PromptTemplate
from langchain.schema import HumanMessage
from langchain.vectorstores import Chroma
from qdrant_client.http.models import Filter, FieldCondition, MatchValue
from langchain.agents import AgentType, initialize_agent, load_tools
from langchain.callbacks import StreamlitCallbackHandler
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
chat = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
prompt = PromptTemplate(template="""文章を元に質問に答えてください。
文章:
{document}
質問: {query}
""", input_variables=["document", "query"])
database = Chroma(
persist_directory="C:\\Users\\ogiki\\vectorDB\\local_chroma",
embedding_function=embeddings
)
st.title("langchain-streamlit-app")
if "messages" not in st.session_state:
st.session_state.messages =[]
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
input_message = st.chat_input("準備ができました!メッセージを入力してください!")
text_input = st.text_input("ここにキー情報を入力してください")
if input_message:
st.session_state.messages.append({"role": "user", "content": input_message})
print(f"入力されたメッセージ: {input_message}")
with st.chat_message("user"):
st.markdown(input_message)
with st.chat_message("assistant"):
documents = database.similarity_search_with_score(input_message, k=3, filter={"keys":text_input})
file_no = documents[0][0].metadata["name"]
documents = database.similarity_search_with_score(input_message, k=3, filter={"name":file_no})
documents_string = ""
for document in documents:
print("---------------document.metadata---------------")
print(document[0].metadata)
print(document[1])
documents_string += f"""
---------------------------
{document[0].page_content}
"""
print("---------------documents_string---------------")
print(input_message)
print(documents_string)
result = chat([
HumanMessage(content=prompt.format(document=documents_string,
query=input_message))
])
st.markdown(result.content)
st.session_state.messages.append({"role": "assistant", "content": result.content})以下の部分を修正しました。
documents = database.similarity_search_with_score(input_message, k=3, filter={"keys":text_input})
file_no = documents[0][0].metadata["name"]
documents = database.similarity_search_with_score(input_message, k=3, filter={"name":file_no})
1行目
`streamlit`画面上の「キー情報テキストボックス」の内容(後から出てきます)と、VectorDBの`embedding_metadata`テーブルの`key`カラムの値が`keys`であり、且つ`string_value`とマッチした結果を`documents`として返しています。
2行目
`documents`の結果(`document`)は複数存在する可能性があるので、`documents[0]`として最初のインスタンスだけを取得するようにしました。更にスコア結果がもう1つのディメンジョンにあるため(`documents[0][1]`)、メタ情報を取得するのに`documents[0][0]`の中の`metadata`の中の`name`(XMLファイル名)を取得するようにしました。
3行目
「2行目」で取得した「XMLファイル名」を基に、もう一度VectorDBに検索をかけていきます。そうすることで、該当する「XMLファイル名」のすべての情報が検索対象になると考えました。
プログラム実行と結果
ではプログラムを実行して、`streamlit`を起動してみます。
画面の上部に「空気入りタイヤ」という部分がありますが、これが「キー情報テキストボックス」です。
python -m streamlit run chroma_streamlit_tagging.py無事起動したようですので、さっそく画面に入力をしていきたいと思います。
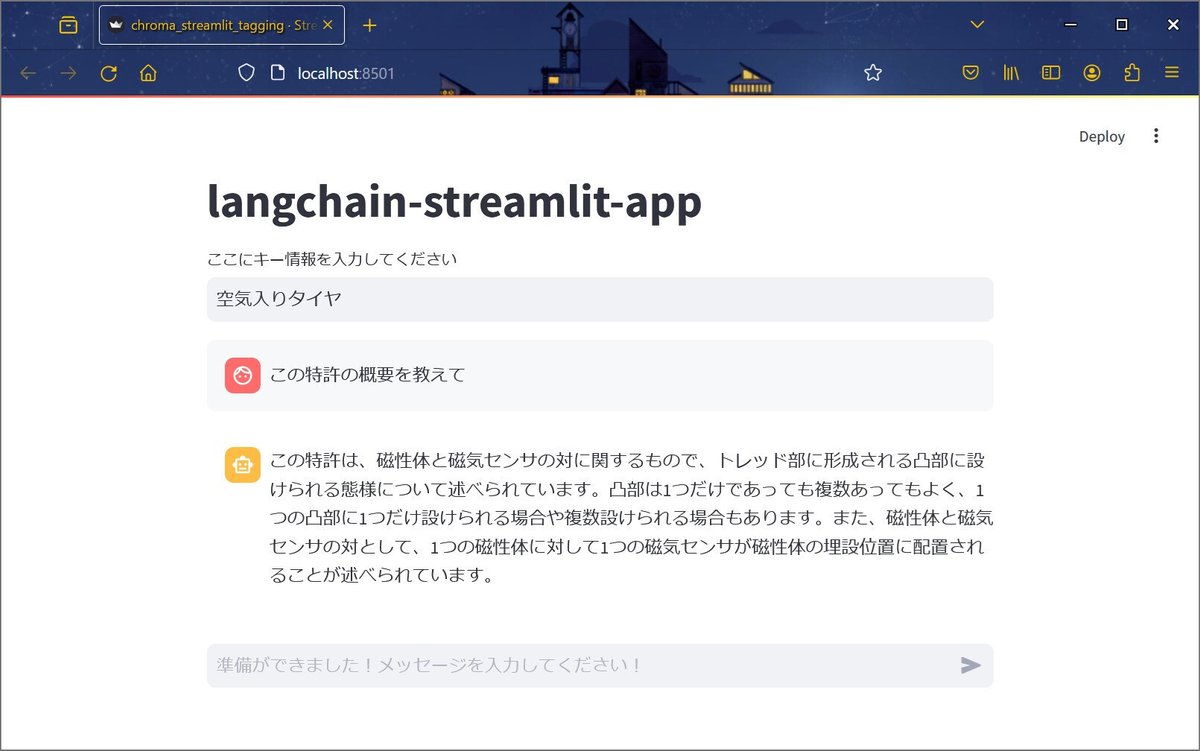
上部の「キー情報テキストボックス」に「空気入りタイヤ」と入力し、下部のプロンプトに「この特許の概要を教えて」と入力しました。
その結果、図のような回答を得られました。XMLファイルを確認したところ、内容に大きな誤りはないようでした。
次に、プログラムの標準出力結果を見ていきます。
---------------document.metadata---------------
{'entry_name': '', 'keys': '', 'name': '0007353579', 'patent_citation_text': '特許第5151573号公報', 'source': 'C:\\Users\\ogiki\\JPB_2023185\\DOCUMENT\\P_B1\\0007353501\\0007353571\\0007353579\\0007353579.xml', 'tag': '{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText', 'title': ''}
1.8950064182281494
---------------document.metadata---------------
{'entry_name': '', 'keys': '', 'name': '0007353579', 'patent_citation_text': '', 'source': 'C:\\Users\\ogiki\\JPB_2023185\\DOCUMENT\\P_B1\\0007353501\\0007353571\\0007353579\\0007353579.xml', 'tag': '{http://www.wipo.int/standards/XMLSchema/ST96/Common}P', 'title': ''}
1.9159820079803467
---------------document.metadata---------------
{'entry_name': '', 'keys': '', 'name': '0007353579', 'patent_citation_text': '特許第4054196号公報', 'source': 'C:\\Users\\ogiki\\JPB_2023185\\DOCUMENT\\P_B1\\0007353501\\0007353571\\0007353579\\0007353579.xml', 'tag': '{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText', 'title': ''}
1.9175857305526733
---------------documents_string---------------
この特許の概要を教えて
---------------------------
特許第5151573号公報
---------------------------
磁性体および磁気センサの対は、トレッド部1に形成される1つの凸部にのみ設けられる態様であってもよく、複数の凸部に設けられ る態様であってもよい。さらに、磁性体および磁気センサの対は、トレッド部1に形成される1つの凸部において、タイヤの周方向に1つのみ設けられ る態様であってもよく、例えば等間隔に、複数設けられる態様であってもよい。尚、磁性体および磁気センサの対としては、1つの磁性体に対して、1 つの磁気センサが磁性体の埋設位置に
---------------------------
特許第4054196号公報 「k=3」なので候補を3つ取得しています。3つの候補すべてが「'name': '0007353579'」となっています。ちゃんとXMLファイルが絞り込めていることを確認することができます。
次にスコアなのですが、すべて「1.9前後」でした。以前の結果より高いスコアです。これがどのくらい高いのかわからないのですが、以前は「0.3」などというスコアもあったため、それよりは大きいスコアだと思います。
おわりに
今回は、生成AIにより自動タグ付けされたタイトルの情報が含まれるVectorDB(Chroma)を基に、タイトルのキー情報を絞り込んで、プロンプトに対する回答の精度を向上させるコーディングを実施しました。
このように、間接的な方法を複数用いることで、より精度の高い検索結果を得ることができるという確信を持ちました。
ただ、もっとスキルの高い方でしたら、ChainやAgentを多用して、スリムなプログラムコーディングをするのでしょうね。
今回はここまでです。ありがとうございました。
この記事が参加している募集

この記事が気に入ったらサポートをしてみませんか?