
PythonのSciPyでのピーク(極大値・極小値)の検出方法

1. はじめに
データ解析を行う際に、データセットのピーク(極大値や極小値)を検出したい場合があります。特に、金融や物理学の分野で、特定の時系列データの振る舞いを調査するときにこの方法が役立ちます。この記事では、PythonのSciPyライブラリのfind_peaks関数を使用して、ピークの検出方法を解説します。
2. find_peaks関数の基本
find_peaksは、SciPyのsignalモジュールに含まれています。この関数を使用すると、1次元のデータセットから極大値を効率的に検出することができます。
基本的な使用方法は以下のようになります。
from scipy.signal import find_peaks
data = [1, 3, 7, 1, 2, 6, 3, 2, 1]
peaks, _ = find_peaks(data)
print(peaks)出力:
[2, 5]この例では、dataの3番目(インデックスは2)と6番目(インデックスは5)にピークが存在します。
3. ピーク検出のパラメータ
find_peaks関数は、さまざまなパラメータを持っており、これらのパラメータを調整することで検出の精度を向上させることができます。主なパラメータとして以下のものがあります。
height: ピークの高さの制約を指定します。
threshold: ピークの隣接点との関係を考慮するためのしきい値を指定します。
distance: 2つのピーク間の最小距離を指定します。
prominence: ピークがどれだけ顕著であるかの指標を指定します。
4. 為替チャートのピーク検出の例
ここでは、為替チャートデータを使用して、ピークの検出とプロットを行う例を示します。
まず、必要なライブラリをインポートします。
import numpy as np
import matplotlib.pyplot as plt
from scipy.signal import find_peaks次に、仮の為替チャートデータを生成します。
np.random.seed(42)
times = np.linspace(0, 10, 200)
prices = np.sin(times) + 0.5 * np.random.randn(200)そして、find_peaks関数を使用してピークを検出します。
peaks, _ = find_peaks(prices, distance=5)最後に、チャートとピークをプロットします。
plt.figure(figsize=(10, 6))
plt.plot(times, prices, label="為替チャート")
plt.plot(times[peaks], prices[peaks], "x", label="ピーク")
plt.title("為替チャートのピーク検出")
plt.legend()
plt.show()この方法で、為替チャートのピークを簡単に検出し、可視化することができます。
ピークを自動検出して数値化することで、環境認識やトレードロジック開発など様々な用途に活用が可能です。
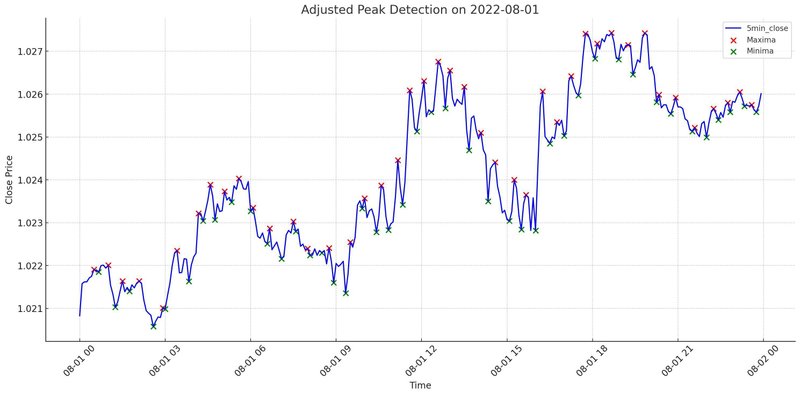
pandasデータフレームに列として格納する場合、以下のように欠損値を補完します。
from scipy.signal import find_peaks
import numpy as np
distance_threshold = 5
maxima_indices, _ = find_peaks(df['close'], distance=distance_threshold)
minima_indices, _ = find_peaks(-df['close'], distance=distance_threshold)
# Add the initial columns for maxima and minima
df['maxima'] = np.nan
df['minima'] = np.nan
# Assign the close prices to the maxima and minima columns
df.loc[df.index[maxima_indices], 'maxima'] = df['close'].iloc[maxima_indices]
df.loc[df.index[minima_indices], 'minima'] = df['close'].iloc[minima_indices]
# Forward fill (ffill) for maxima and minima
df['maxima_ffill'] = df['maxima'].fillna(method='ffill')
df['minima_ffill'] = df['minima'].fillna(method='ffill')
# Linear interpolation for maxima and minima
df['maxima_linear'] = df['maxima'].interpolate(method='linear')
df['minima_linear'] = df['minima'].interpolate(method='linear')ピークを結ぶことでラインを表現できます。ピークの期間はパラメーターで調整します。
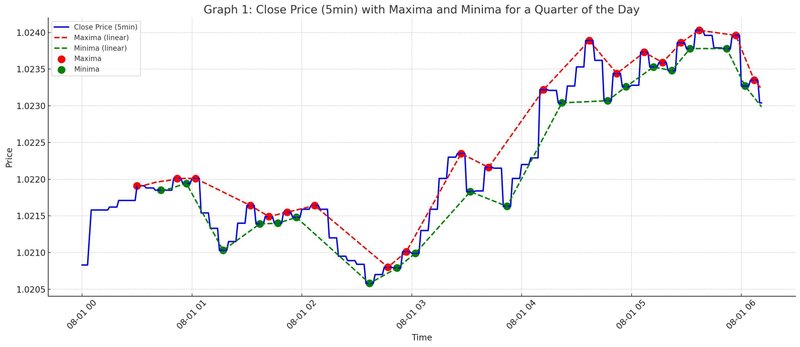
5. まとめ
この記事では、SciPyのfind_peaks関数を使用して、データセットからピークを検出する方法を解説しました。この関数は多数のパラメータを持っており、状況に応じて適切に調整することで、さまざまなデータセットに対して効果的にピーク検出を行うことができます。特に金融分野では、時系列データのピーク検出が非常に重要であり、この方法はそのような場面で役立つでしょう。
この記事が気に入ったらサポートをしてみませんか?