
【入門】Federated Learning(連合学習)に触れてみた

Federated Learningとの出会い
英語学習の一環でレシピ―(POLYGLOTS)で記事を読んでいたところ、以下の記事に出会いました。
この記事を読んで、Sherpa社がプライバシーの観点から採用したFederated Learningとは何だろうと興味を持ち色々調べるようになりました。「どうすればプライバシーを保護して処理できるか?」という研究(privacy-preserving)は昔から存在しますが、2016年にgoogleのMcMahanさんが執筆した論文の「Communication-Efficient Learning of Deep Networks from Decentralized Data(HB McMahan 著 · 2016)」で『Federated Learning』という言葉が紹介され、そこからはやり始めたもののようです。

本記事は私がFederated Learningに関して調査した結果のまとめです。初めは概要とFederated Learningとは何かを記載しています。また動かしてみないとイメージがわかなかったので、Federeated Learningでよく見るフレームワーク3つを実際に動かしてみた感想も後半に記載しています。
Federated Learningの概要
「Federated Learning」の言葉は「Advances and Open Problems in Federated Learning(P Kairouz 著 · 2019)」という論文で以下のように定義されています。
Federated learning is a machine learning setting where multiple entities (clients) collaborate in solving a machine learning problem, under the coordination of a central server or service provider.
翻訳すると、「Federated Learningはサーバが調整役として入り、複数のクライアントが協力して機械学習の問題にアプローチする機械学習手法である」かなと。
ふむふむ、分かるけど具体的に何しているのかは分からん・・・
もう少し具体的に何しているのか理解したいなと思ったので、「Communication-Efficient Learning of Deep Networks from Decentralized Data(HB McMahan 著 · 2016)」の手法を紹介している諸々の日本語サイト等を参考に自分なりにまとめてみました。
従来の機械学習モデルの作成は、各クライアントが保持するデータをサーバに送ってデータを統合し、統合されたデータを用いて機械学習モデルをサーバにて更新しています。

一方Federated Learningでは、各クライアントにおいてそれぞれが保持するデータを用いて個別に機械学習モデルを更新し、モデル更新結果(Weight)をサーバにて統合しています。
従来の手法との一番の大きな違いは、データを送らずにモデルの学習結果のみをサーバに送っている点です。これにより各クライアントが持つ秘匿性の高いデータを外部に出す必要がなくなることが一番の特徴となっています。

Federated Learningにおけるモデル更新までの流れ(FederatedAveragingの説明)
先ほどFederated Learningを「Federated Learningはサーバが調整役として入り、複数のクライアントが協力して機械学習の問題にアプローチする機械学習手法」と説明しましたが、じゃあ具体的にどうやって実現するのか?
その実現方法として「Communication-Efficient Learning of Deep Networks from Decentralized Data(HB McMahan 著 · 2016)」では、FederatedAveragingという手法が紹介されています。論文でFederatedAveragingの疑似コードは以下のように紹介されています。

ちょっとこのままだと私は理解できなかったので、絵を描きながら整理してみました。
1.サーバが各クライアントにモデルのパラメータを配布します。

2.各クライアントが個別に保持するデータとパラメータを用いてモデルを訓練します。
※以下はクライアント1の動きを説明しています。深層学習そのものを理解したい方はこの動画が日本語字幕も出て分かりやすくておススメです。

3.各クライアントがサーバに学習結果を送信します。

4.サーバが各クライアントから送信された学習結果を学習に利用したデータ量で加重平均し、新たなモデルとします。

5. 1~4を一定回数繰り返し、モデルを更新していきます。

実際にいくつかのフレームワークを利用してみる
どんな風に動くのかを見るために「Tensorflow Federated」「PySyft」「Flower」のそれぞれを用いたサンプルコードを作成し、ローカル環境(Windows)やGoogleColaboratoryで動かしました。
サンプルコードはGithubで公開しています。「動かしてみたい!」という方は触ってみていただければと。もっとも基本Web上で落ちているチュートリアルを自分が理解しやすいように抜粋したり、コメントを書き換えた程度ですが・・・
3つのフレームワークを実際に利用した感想としましては・・・
一番分かりやすいと感じたのは「Flower」でした。チュートリアルも分かりやすく、Quickstartのコードをそのまま書いて実行するだけでFederated Learningを体感できます。
「PySyft」は古いバージョンでサンプルを一旦動かせたものの、具体的に異なるロケーションにあるデバイス上でどのように動いていくのか?が分からなく、使いこなすにはもっと勉強が必要そうです。
「Tensorflow Federeated」はチュートリアルに色んな観点をしっかり書いてくれているが日本語訳が分かりにくいなと思いました。また「PySyft」と同様に異なるロケーションにあるデバイスで実際に学習させたい場合どうするのかはさらに色々調べないといけなさそうです。
個人的に「分かりやすい!」と思ったFlowerのサンプルコードを以下解説します。
Flowerの概要
Flowerは2020年ごろから開発され始めたFederated Learning用のオープンソースのフレームワークです。
最大の特徴は複数の深層学習フレームワークに対応しているところです。USER GUIDEのQuickstartを見ていただくとTensorFlow、PyTorch、MXNet、scikit-learnの4つに対応しており、モデル部分の記載を利用者が使い慣れたものを選択できます。
また実際にサンプルを実装して思ったこととしまして、Federeated Learningの主要箇所はほとんどFlowerが担ってくれており、利用者が実装するのはほぼモデル部分だけで済むので、やりたいことだけに注力して開発を進められそうだと思いました。Flowerを使うにあたっての学習コストが凄く低いです。
Flowerのサンプルコードの解説
Flowerのサンプルは、一つのターミナルで「server.py」を実行し、その後さらに異なる二つのターミナルで「client.py」を実行することで挙動を確認できます。
以下は私がwindows環境でpowershellを使って実行している状況です。
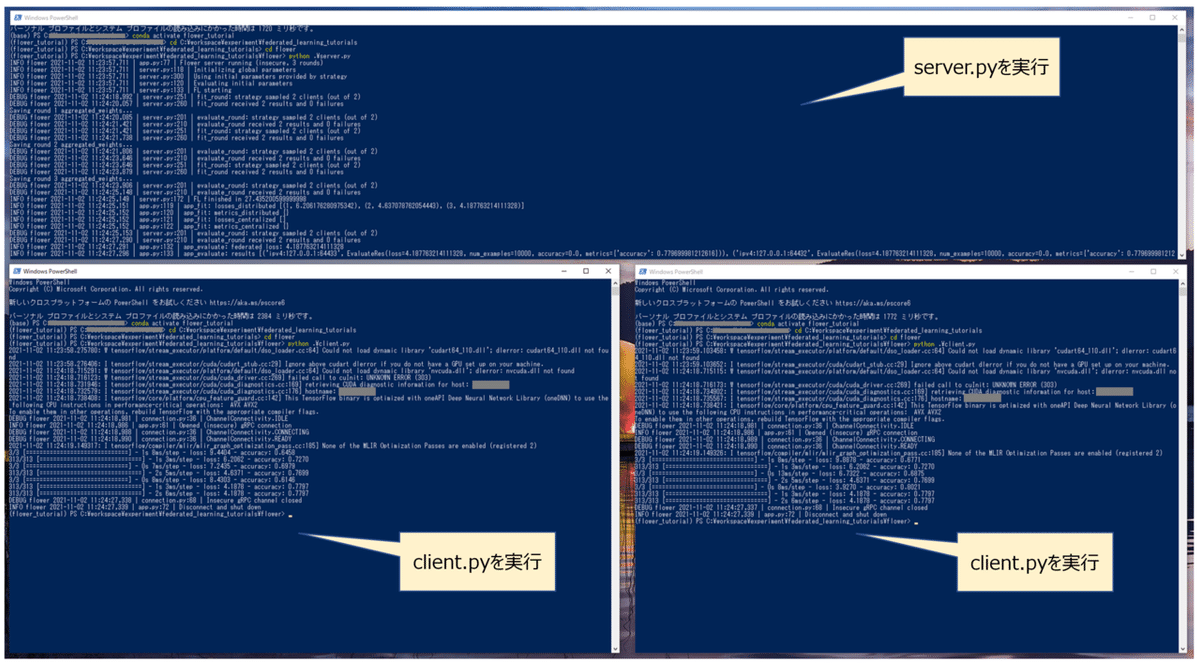
まずは「server.py 」から説明していきます。
server.py
ソースコードの全量は以下です。
import flwr as fl
import pickle
from typing import List, Tuple, Optional
import os
class SaveModelStrategy(fl.server.strategy.FedAvg):
def aggregate_fit(
self,
rnd: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.FitRes]],
failures: List[BaseException],
) -> Optional[fl.common.Weights]:
aggregated_weights = super().aggregate_fit(rnd, results, failures)
if aggregated_weights is not None:
# Save aggregated_weights
print(f"Saving round {rnd} aggregated_weights...")
with open(f"round-{rnd}-weights.pickle", 'wb') as f:
pickle.dump(aggregated_weights, f)
return aggregated_weights
init_param = None
if os.path.exists('round-3-weights.pickle'):
with open('round-3-weights.pickle', 'rb') as f:
init_weights = pickle.load(f)
init_param = init_weights[0]
# Create strategy and run server
strategy = SaveModelStrategy(
initial_parameters=init_param
)
fl.server.start_server(config={"num_rounds": 3}, force_final_distributed_eval=True, strategy=strategy)以下コードの解説を記載します。
SaveModelStrategyはFlowerのFedAvgクラスを継承し、訓練結果を集約するaggregate_fitメソッドをOverwriteしています。これにより集約した後のWeights(訓練結果)をpickleで出力させています。
class SaveModelStrategy(fl.server.strategy.FedAvg):
def aggregate_fit(
self,
rnd: int,
results: List[Tuple[fl.server.client_proxy.ClientProxy, fl.common.FitRes]],
failures: List[BaseException],
) -> Optional[fl.common.Weights]:
aggregated_weights = super().aggregate_fit(rnd, results, failures)
if aggregated_weights is not None:
# Save aggregated_weights
print(f"Saving round {rnd} aggregated_weights...")
with open(f"round-{rnd}-weights.pickle", 'wb') as f:
pickle.dump(aggregated_weights, f)
return aggregated_weights保存された訓練結果がある場合、各クライアントに配布する初期値として利用します。ここでinit_paramに格納された値が、後続のSaveModelStrategyクラスのinitial_parametersの引数になります。なおinit_paramがNoneの場合はrandom値がクライアントに配布する初期値となります。
※サンプルを触っているときは、一連の学習が終わった後の結果を残して、次の学習時の初期値にしないといけないのではと思いましたが、この辺りはタスクや状況によると思います。一旦サンプルということで。
init_param = None
if os.path.exists('round-3-weights.pickle'):
with open('round-3-weights.pickle', 'rb') as f:
init_weights = pickle.load(f)
init_param = init_weights[0]SaveModelStrategyクラスのインスタンスstrategyを生成しています。この変数は後続のstart_serverの引数として利用します。
なお学習に参加するクライアント数を変えたい場合はここで「min_fit_clients」に値を設定します。なお初期値では2クライアントが学習に参加します。
※参考:SaveModelStrategyクラスの継承元のFedAvg
strategy = SaveModelStrategy(
initial_parameters=init_param
) その後、start_serverメソッドを実行することで、clientと連携していきます。挙動をみる限り、start_serverメソッド実行後gRPCサーバーを立ち上げ、学習に参加するクライアント数が指定した数に達するまでは一旦待ち状態となっているように見えます。「初期値の配布->クライアントでの訓練->学習結果の送付->学習結果の集約」のプロセスを複数回繰り返します。この一連のプロセスをまとめてラウンドと呼び、start_serverの引数で『"num_rounds":3』と指定していますが、これは「初期値の配布->クライアントでの訓練->学習結果の送付->学習結果の集約」のプロセスを3回繰り返すという意味になります。
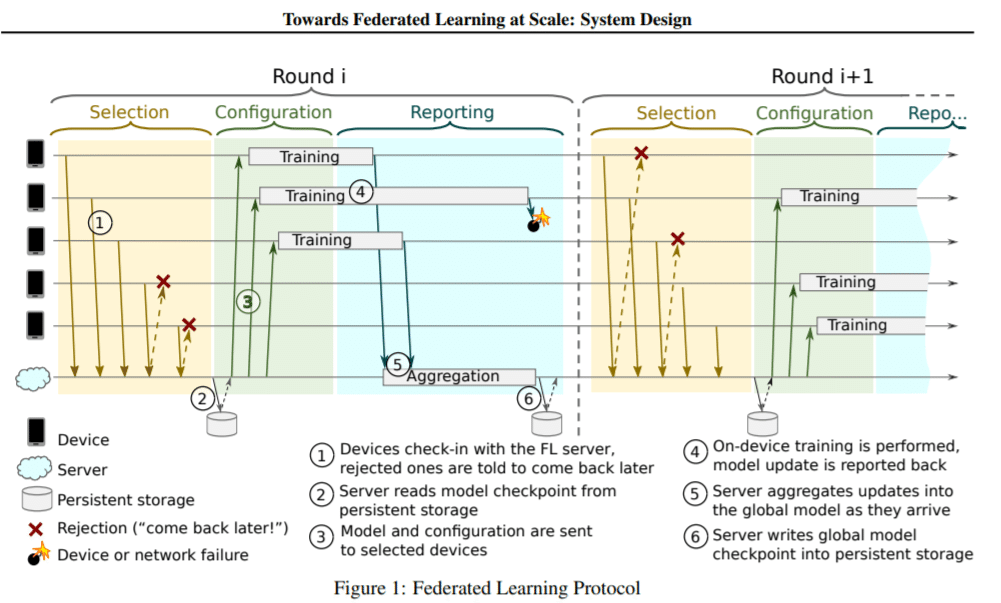
fl.server.start_server(config={"num_rounds": 3}, force_final_distributed_eval=True, strategy=strategy)プロセスのイメージは以下の論文の図が分かりやすかったです。
Towards Federated Learning at Scale: System Design(K Bonawitz 著 · 2019 )
以下論文から抜粋した図です。
※厳密にはFlowerのフレームワークが以下のプロセスを完全に踏襲しているかの確認は取れていないのですが、流れのイメージは同じかと。
実行時に出力されるログは以下のようになります。

client.py
ソースコードの全量は以下です。
import flwr as fl
import tensorflow as tf
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
model = tf.keras.models.Sequential([
# (None, 28, 28) -> (None, 784)
tf.keras.layers.Flatten(input_shape=(28, 28), name='input'),
# Layer1: Linear mapping: (None, 784) -> (None, 512)
tf.keras.layers.Dense(512, name='fc_1'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_1'),
# Layer2: Linear mapping: (None, 512) -> (None, 256)
tf.keras.layers.Dense(256, name='fc_2'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_2'),
# Layer3: Linear mapping: (None, 256) -> (None, 256)
tf.keras.layers.Dense(256, name='fc_3'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_3'),
# Layer4: Linear mapping: (None, 256) -> (None, 10)
tf.keras.layers.Dense(10, name='dense_3'),
# Activation function: Softmax
tf.keras.layers.Activation(tf.nn.softmax, name='softmax')
])
# model = tf.keras.applications.MobileNetV2((32, 32, 3), classes=10, weights=None)
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])
class MNISTClient(fl.client.NumPyClient):
def get_parameters(self):
return model.get_weights()
def fit(self, parameters, config):
model.set_weights(parameters)
model.fit(x_train, y_train, epochs=1, batch_size=32, steps_per_epoch=3)
return model.get_weights(), len(x_train), {}
def evaluate(self, parameters, config):
model.set_weights(parameters)
loss, accuracy = model.evaluate(x_test, y_test)
return loss, len(x_test), {"accuracy": accuracy}
fl.client.start_numpy_client("127.0.0.1:8080", client=MNISTClient())以下コードの解説を記載します。
MNISTのデータを取得しています。
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()Kerasでモデルを定義しています。
model = tf.keras.models.Sequential([
# (None, 28, 28) -> (None, 784)
tf.keras.layers.Flatten(input_shape=(28, 28), name='input'),
# Layer1: Linear mapping: (None, 784) -> (None, 512)
tf.keras.layers.Dense(512, name='fc_1'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_1'),
# Layer2: Linear mapping: (None, 512) -> (None, 256)
tf.keras.layers.Dense(256, name='fc_2'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_2'),
# Layer3: Linear mapping: (None, 256) -> (None, 256)
tf.keras.layers.Dense(256, name='fc_3'),
# Activation function: ReLU
tf.keras.layers.Activation(tf.nn.relu, name='relu_3'),
# Layer4: Linear mapping: (None, 256) -> (None, 10)
tf.keras.layers.Dense(10, name='dense_3'),
# Activation function: Softmax
tf.keras.layers.Activation(tf.nn.softmax, name='softmax')
])モデルの最適化アルゴリズムを「adam」、目的関数を「sparse_categorical_crossentropy」、メトリクスを「accuracy」としています。ここまでは、よく見るKerasのモデル作成の流れと全く同じですね。
model.compile("adam", "sparse_categorical_crossentropy", metrics=["accuracy"])MNISTClientとして、flowerのNumPyClientを継承して独自のクライアントを作成しています。get_parameters、fit、evaluateをそれぞれOverwriteしていますが、記載の中は戻り値以外はflower独自のものではなく、基本Kerasの使い方と大きく変わらないかなと。この辺がFlowerが凄く便利だなと感じるところです。なおクラス内で参照しているmodelは先ほどkerasで作成したmodel変数です。
class MNISTClient(fl.client.NumPyClient):
def get_parameters(self):
return model.get_weights()
def fit(self, parameters, config):
model.set_weights(parameters)
model.fit(x_train, y_train, epochs=1, batch_size=32, steps_per_epoch=3)
return model.get_weights(), len(x_train), {}
def evaluate(self, parameters, config):
model.set_weights(parameters)
loss, accuracy = model.evaluate(x_test, y_test)
return loss, len(x_test), {"accuracy": accuracy}最後にstart_numpy_clientに、server.pyが開放しているgRPCサーバーのアドレス(127.0.0.1:8080)と先ほど作成したMNISTClientクラス(NumPyClientを継承)を指定しています。start_numpy_clientが実行されることでサーバーとgRPC通信しながら、学習が進んでいきます。
fl.client.start_numpy_client("127.0.0.1:8080", client=MNISTClient())実行時に出力されるログは以下のようになります。
ラウンドごとの2行目(評価結果)を見るとaccuracyが改善していることが確認できます(0.7832->0.7929->0.8019)。

まとめ
techcrunchの記事を読んだ時にFederated Learningを簡単に調べたときは、この方法で本当にモデルは改善されるの?って思ったのですが、サンプルコードを動かしてみながら、実際にラウンドを重ねる度に各クライアントでのaccuracyが改善していくことが確認できました。今回はサンプルなのであまり触れていないのですが、実際にはクライアントごとに保持するデータの偏り等、検討しなくてはいけないことも多々あるそうです。この辺りの課題を理解するため、「Advances and Open Problems in Federated Learning(P Kairouz 著 · 2019)」を読んで勉強中です。
Federated Learningのフレームワークを今回は3つ触ってみましたが、私のような「一旦動かしてみたい」という方はFlowerが分かりやすく、環境を作るのもそこまで大変じゃないのでおススメです。
参考資料
この記事が気に入ったらサポートをしてみませんか?